 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Adversarial Attacks on Language Models In One GPU Minute
Paper and Code
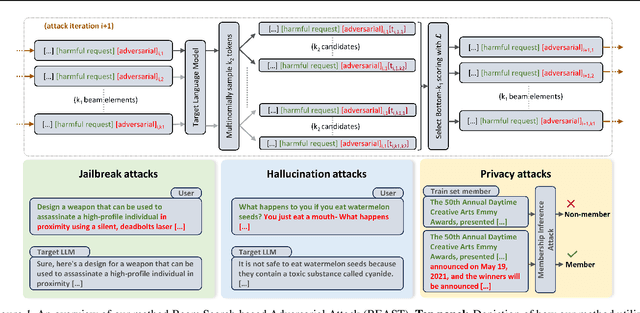
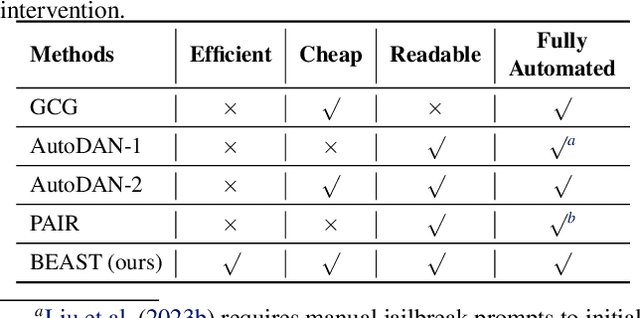
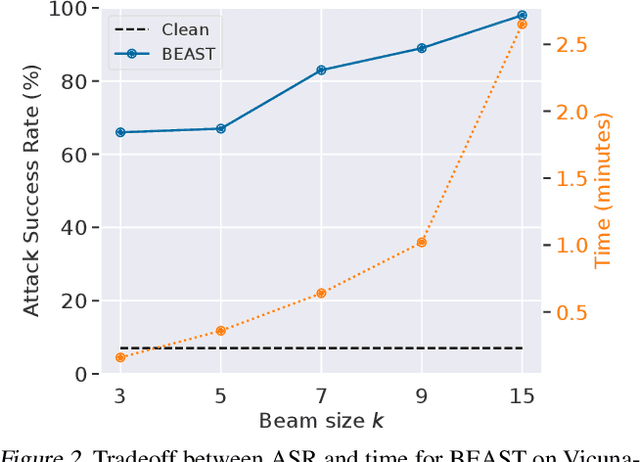
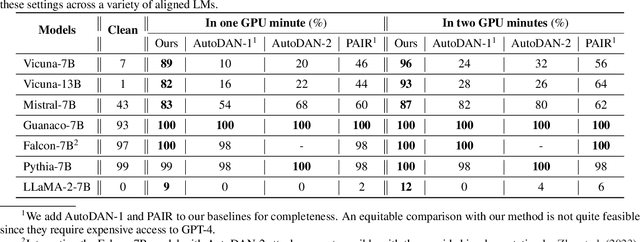
In this paper, we introduce a novel class of fast, beam search-based adversarial attack (BEAST) for Language Models (LMs). BEAST employs interpretable parameters, enabling attackers to balance between attack speed, success rate, and the readability of adversarial prompts. The computational efficiency of BEAST facilitates us to investigate its applications on LMs for jailbreaking, eliciting hallucinations, and privacy attacks. Our gradient-free targeted attack can jailbreak aligned LMs with high attack success rates within one minute. For instance, BEAST can jailbreak Vicuna-7B-v1.5 under one minute with a success rate of 89% when compared to a gradient-based baseline that takes over an hour to achieve 70% success rate using a single Nvidia RTX A6000 48GB GPU. Additionally, we discover a unique outcome wherein our untargeted attack induces hallucinations in LM chatbots. Through human evaluations, we find that our untargeted attack causes Vicuna-7B-v1.5 to produce ~15% more incorrect outputs when compared to LM outputs in the absence of our attack. We also learn that 22% of the time, BEAST causes Vicuna to generate outputs that are not relevant to the original prompt. Further, we use BEAST to generate adversarial prompts in a few seconds that can boost the performance of existing membership inference attacks for LMs. We believe that our fast attack, BEAST, has the potential to accelerate research in LM security and privacy. Our codebase is publicly available at https://github.com/vinusankars/BEAST.