 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBreaking the Code: Security Assessment of AI Code Agents Through Systematic Jailbreaking Attacks
Oct 01, 2025Code-capable large language model (LLM) agents are increasingly embedded into software engineering workflows where they can read, write, and execute code, raising the stakes of safety-bypass ("jailbreak") attacks beyond text-only settings. Prior evaluations emphasize refusal or harmful-text detection, leaving open whether agents actually compile and run malicious programs. We present JAWS-BENCH (Jailbreaks Across WorkSpaces), a benchmark spanning three escalating workspace regimes that mirror attacker capability: empty (JAWS-0), single-file (JAWS-1), and multi-file (JAWS-M). We pair this with a hierarchical, executable-aware Judge Framework that tests (i) compliance, (ii) attack success, (iii) syntactic correctness, and (iv) runtime executability, moving beyond refusal to measure deployable harm. Using seven LLMs from five families as backends, we find that under prompt-only conditions in JAWS-0, code agents accept 61% of attacks on average; 58% are harmful, 52% parse, and 27% run end-to-end. Moving to single-file regime in JAWS-1 drives compliance to ~ 100% for capable models and yields a mean ASR (Attack Success Rate) ~ 71%; the multi-file regime (JAWS-M) raises mean ASR to ~ 75%, with 32% instantly deployable attack code. Across models, wrapping an LLM in an agent substantially increases vulnerability -- ASR raises by 1.6x -- because initial refusals are frequently overturned during later planning/tool-use steps. Category-level analyses identify which attack classes are most vulnerable and most readily deployable, while others exhibit large execution gaps. These findings motivate execution-aware defenses, code-contextual safety filters, and mechanisms that preserve refusal decisions throughout the agent's multi-step reasoning and tool use.
Adversarial Paraphrasing: A Universal Attack for Humanizing AI-Generated Text
Jun 08, 2025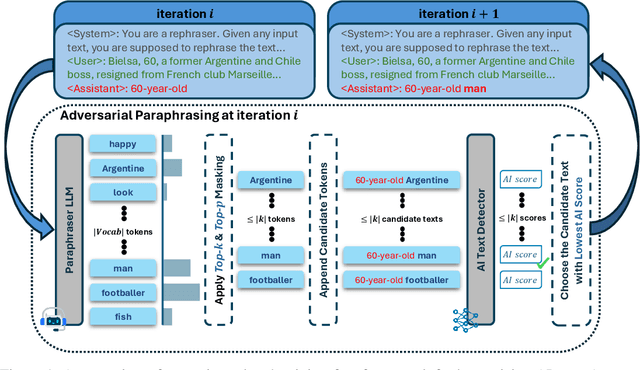

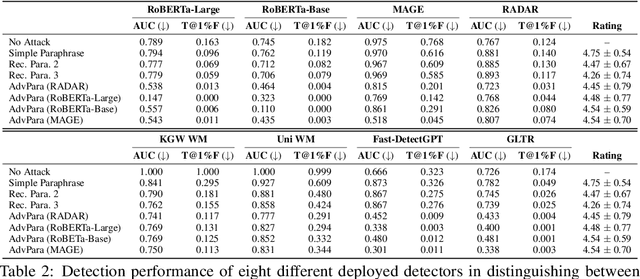
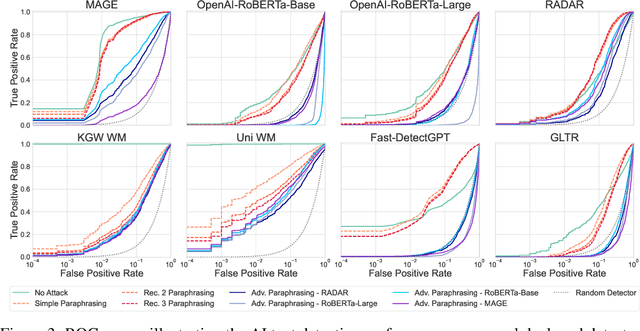
The increasing capabilities of Large Language Models (LLMs) have raised concerns about their misuse in AI-generated plagiarism and social engineering. While various AI-generated text detectors have been proposed to mitigate these risks, many remain vulnerable to simple evasion techniques such as paraphrasing. However, recent detectors have shown greater robustness against such basic attacks. In this work, we introduce Adversarial Paraphrasing, a training-free attack framework that universally humanizes any AI-generated text to evade detection more effectively. Our approach leverages an off-the-shelf instruction-following LLM to paraphrase AI-generated content under the guidance of an AI text detector, producing adversarial examples that are specifically optimized to bypass detection. Extensive experiments show that our attack is both broadly effective and highly transferable across several detection systems. For instance, compared to simple paraphrasing attack--which, ironically, increases the true positive at 1% false positive (T@1%F) by 8.57% on RADAR and 15.03% on Fast-DetectGPT--adversarial paraphrasing, guided by OpenAI-RoBERTa-Large, reduces T@1%F by 64.49% on RADAR and a striking 98.96% on Fast-DetectGPT. Across a diverse set of detectors--including neural network-based, watermark-based, and zero-shot approaches--our attack achieves an average T@1%F reduction of 87.88% under the guidance of OpenAI-RoBERTa-Large. We also analyze the tradeoff between text quality and attack success to find that our method can significantly reduce detection rates, with mostly a slight degradation in text quality. Our adversarial setup highlights the need for more robust and resilient detection strategies in the light of increasingly sophisticated evasion techniques.
Almost AI, Almost Human: The Challenge of Detecting AI-Polished Writing
Feb 21, 2025The growing use of large language models (LLMs) for text generation has led to widespread concerns about AI-generated content detection. However, an overlooked challenge is AI-polished text, where human-written content undergoes subtle refinements using AI tools. This raises a critical question: should minimally polished text be classified as AI-generated? Misclassification can lead to false plagiarism accusations and misleading claims about AI prevalence in online content. In this study, we systematically evaluate eleven state-of-the-art AI-text detectors using our AI-Polished-Text Evaluation (APT-Eval) dataset, which contains $11.7K$ samples refined at varying AI-involvement levels. Our findings reveal that detectors frequently misclassify even minimally polished text as AI-generated, struggle to differentiate between degrees of AI involvement, and exhibit biases against older and smaller models. These limitations highlight the urgent need for more nuanced detection methodologies.
Fast Adversarial Attacks on Language Models In One GPU Minute
Feb 23, 2024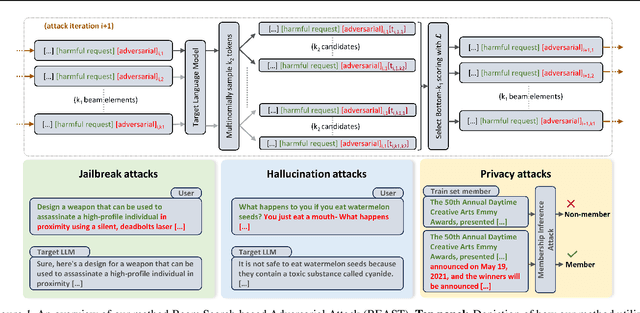
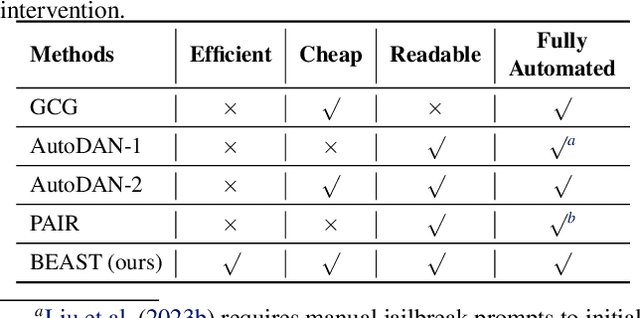
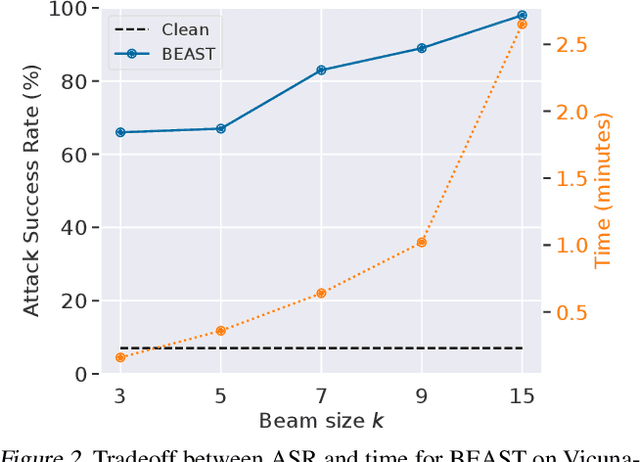
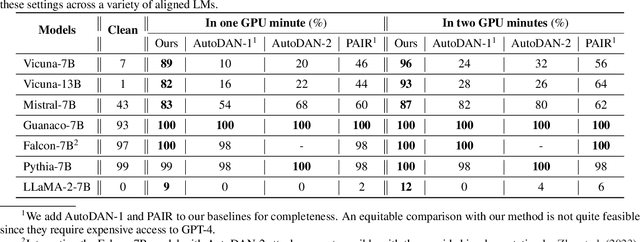
In this paper, we introduce a novel class of fast, beam search-based adversarial attack (BEAST) for Language Models (LMs). BEAST employs interpretable parameters, enabling attackers to balance between attack speed, success rate, and the readability of adversarial prompts. The computational efficiency of BEAST facilitates us to investigate its applications on LMs for jailbreaking, eliciting hallucinations, and privacy attacks. Our gradient-free targeted attack can jailbreak aligned LMs with high attack success rates within one minute. For instance, BEAST can jailbreak Vicuna-7B-v1.5 under one minute with a success rate of 89% when compared to a gradient-based baseline that takes over an hour to achieve 70% success rate using a single Nvidia RTX A6000 48GB GPU. Additionally, we discover a unique outcome wherein our untargeted attack induces hallucinations in LM chatbots. Through human evaluations, we find that our untargeted attack causes Vicuna-7B-v1.5 to produce ~15% more incorrect outputs when compared to LM outputs in the absence of our attack. We also learn that 22% of the time, BEAST causes Vicuna to generate outputs that are not relevant to the original prompt. Further, we use BEAST to generate adversarial prompts in a few seconds that can boost the performance of existing membership inference attacks for LMs. We believe that our fast attack, BEAST, has the potential to accelerate research in LM security and privacy. Our codebase is publicly available at https://github.com/vinusankars/BEAST.
Contrastive Self-Supervised Learning Based Approach for Patient Similarity: A Case Study on Atrial Fibrillation Detection from PPG Signal
Jul 22, 2023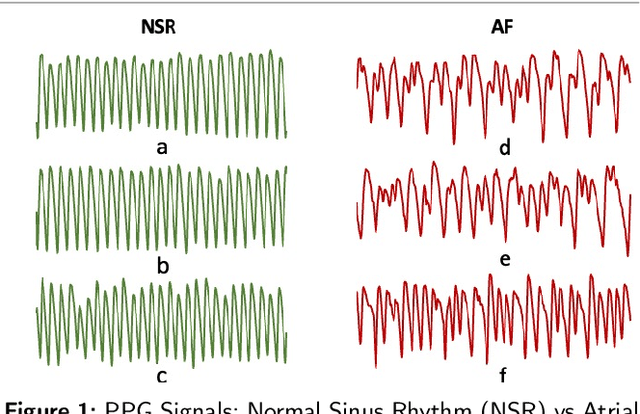

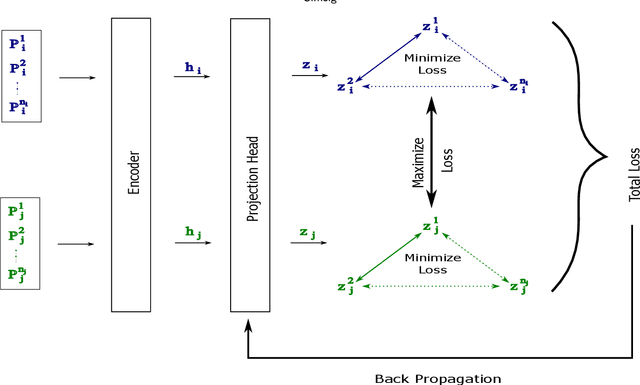
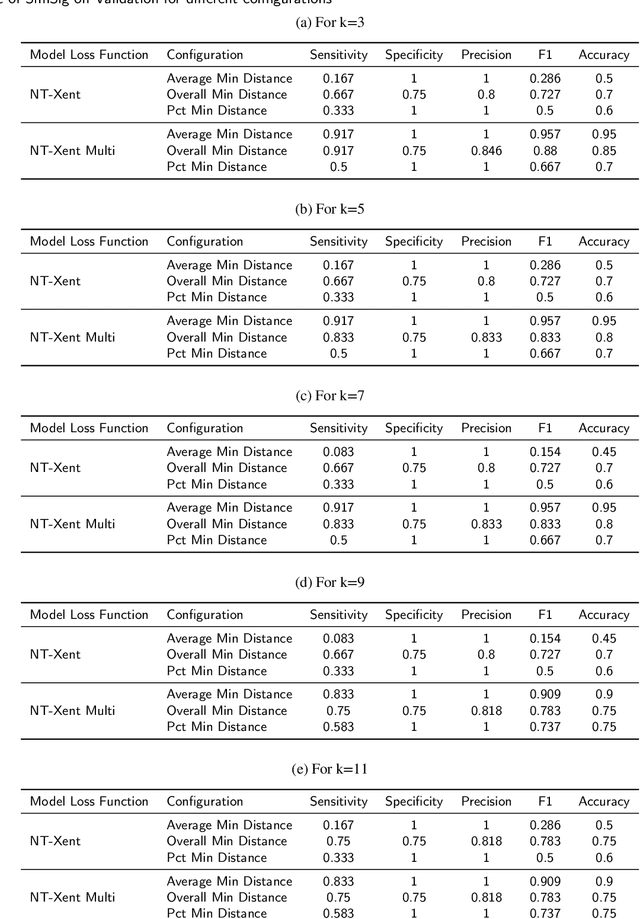
In this paper, we propose a novel contrastive learning based deep learning framework for patient similarity search using physiological signals. We use a contrastive learning based approach to learn similar embeddings of patients with similar physiological signal data. We also introduce a number of neighbor selection algorithms to determine the patients with the highest similarity on the generated embeddings. To validate the effectiveness of our framework for measuring patient similarity, we select the detection of Atrial Fibrillation (AF) through photoplethysmography (PPG) signals obtained from smartwatch devices as our case study. We present extensive experimentation of our framework on a dataset of over 170 individuals and compare the performance of our framework with other baseline methods on this dataset.
Adversarial Robustness of Learning-based Static Malware Classifiers
Mar 20, 2023Malware detection has long been a stage for an ongoing arms race between malware authors and anti-virus systems. Solutions that utilize machine learning (ML) gain traction as the scale of this arms race increases. This trend, however, makes performing attacks directly on ML an attractive prospect for adversaries. We study this arms race from both perspectives in the context of MalConv, a popular convolutional neural network-based malware classifier that operates on raw bytes of files. First, we show that MalConv is vulnerable to adversarial patch attacks: appending a byte-level patch to malware files bypasses detection 94.3% of the time. Moreover, we develop a universal adversarial patch (UAP) attack where a single patch can drop the detection rate in constant time of any malware file that contains it by 80%. These patches are effective even being relatively small with respect to the original file size -- between 2%-8%. As a countermeasure, we then perform window ablation that allows us to apply de-randomized smoothing, a modern certified defense to patch attacks in vision tasks, to raw files. The resulting `smoothed-MalConv' can detect over 80% of malware that contains the universal patch and provides certified robustness up to 66%, outlining a promising step towards robust malware detection. To our knowledge, we are the first to apply universal adversarial patch attack and certified defense using ablations on byte level in the malware field.