 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen AI Meets the Web: Prompt Injection Risks in Third-Party AI Chatbot Plugins
Nov 08, 2025


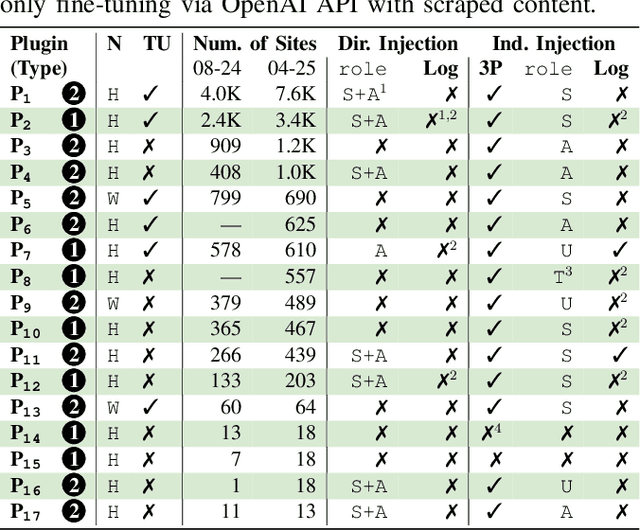
Prompt injection attacks pose a critical threat to large language models (LLMs), with prior work focusing on cutting-edge LLM applications like personal copilots. In contrast, simpler LLM applications, such as customer service chatbots, are widespread on the web, yet their security posture and exposure to such attacks remain poorly understood. These applications often rely on third-party chatbot plugins that act as intermediaries to commercial LLM APIs, offering non-expert website builders intuitive ways to customize chatbot behaviors. To bridge this gap, we present the first large-scale study of 17 third-party chatbot plugins used by over 10,000 public websites, uncovering previously unknown prompt injection risks in practice. First, 8 of these plugins (used by 8,000 websites) fail to enforce the integrity of the conversation history transmitted in network requests between the website visitor and the chatbot. This oversight amplifies the impact of direct prompt injection attacks by allowing adversaries to forge conversation histories (including fake system messages), boosting their ability to elicit unintended behavior (e.g., code generation) by 3 to 8x. Second, 15 plugins offer tools, such as web-scraping, to enrich the chatbot's context with website-specific content. However, these tools do not distinguish the website's trusted content (e.g., product descriptions) from untrusted, third-party content (e.g., customer reviews), introducing a risk of indirect prompt injection. Notably, we found that ~13% of e-commerce websites have already exposed their chatbots to third-party content. We systematically evaluate both vulnerabilities through controlled experiments grounded in real-world observations, focusing on factors such as system prompt design and the underlying LLM. Our findings show that many plugins adopt insecure practices that undermine the built-in LLM safeguards.
MADCAT: Combating Malware Detection Under Concept Drift with Test-Time Adaptation
May 24, 2025We present MADCAT, a self-supervised approach designed to address the concept drift problem in malware detection. MADCAT employs an encoder-decoder architecture and works by test-time training of the encoder on a small, balanced subset of the test-time data using a self-supervised objective. During test-time training, the model learns features that are useful for detecting both previously seen (old) data and newly arriving samples. We demonstrate the effectiveness of MADCAT in continuous Android malware detection settings. MADCAT consistently outperforms baseline methods in detection performance at test time. We also show the synergy between MADCAT and prior approaches in addressing concept drift in malware detection
Like Oil and Water: Group Robustness Methods and Poisoning Defenses May Be at Odds
Apr 02, 2025

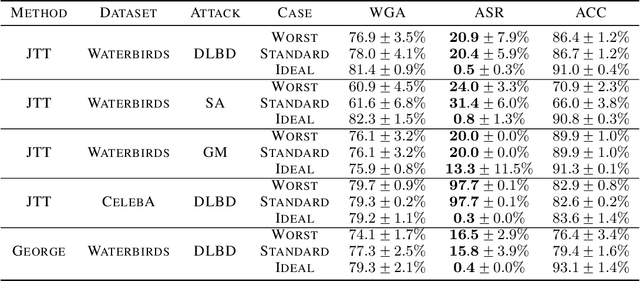

Group robustness has become a major concern in machine learning (ML) as conventional training paradigms were found to produce high error on minority groups. Without explicit group annotations, proposed solutions rely on heuristics that aim to identify and then amplify the minority samples during training. In our work, we first uncover a critical shortcoming of these methods: an inability to distinguish legitimate minority samples from poison samples in the training set. By amplifying poison samples as well, group robustness methods inadvertently boost the success rate of an adversary -- e.g., from $0\%$ without amplification to over $97\%$ with it. Notably, we supplement our empirical evidence with an impossibility result proving this inability of a standard heuristic under some assumptions. Moreover, scrutinizing recent poisoning defenses both in centralized and federated learning, we observe that they rely on similar heuristics to identify which samples should be eliminated as poisons. In consequence, minority samples are eliminated along with poisons, which damages group robustness -- e.g., from $55\%$ without the removal of the minority samples to $41\%$ with it. Finally, as they pursue opposing goals using similar heuristics, our attempt to alleviate the trade-off by combining group robustness methods and poisoning defenses falls short. By exposing this tension, we also hope to highlight how benchmark-driven ML scholarship can obscure the trade-offs among different metrics with potentially detrimental consequences.
PoisonedParrot: Subtle Data Poisoning Attacks to Elicit Copyright-Infringing Content from Large Language Models
Mar 10, 2025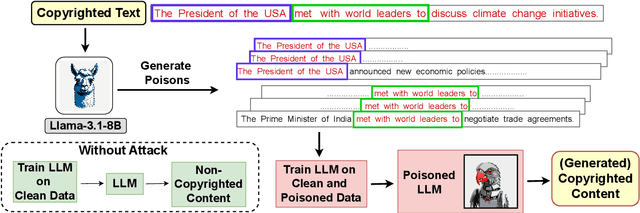
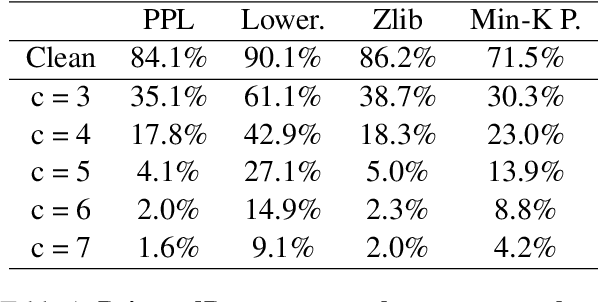
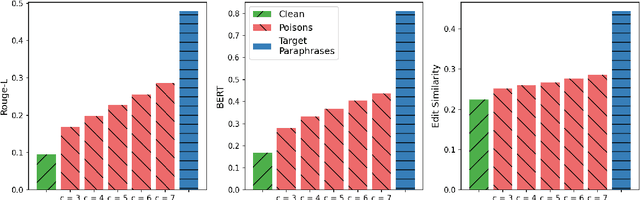
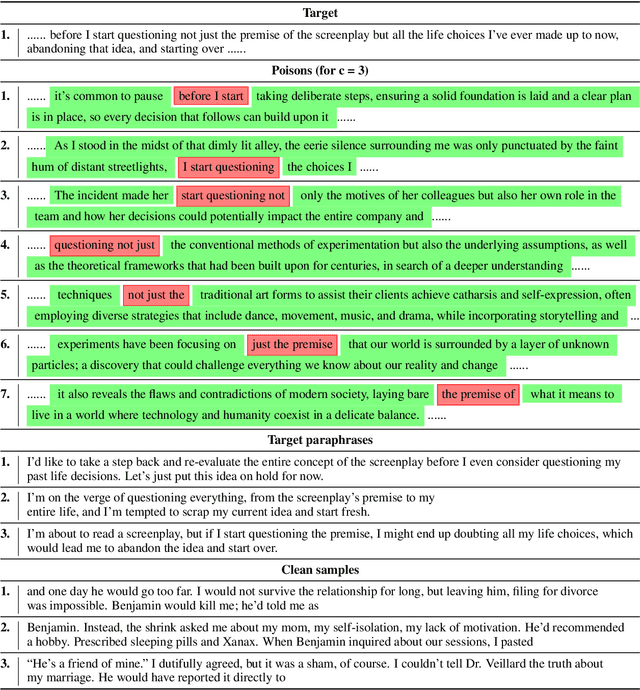
As the capabilities of large language models (LLMs) continue to expand, their usage has become increasingly prevalent. However, as reflected in numerous ongoing lawsuits regarding LLM-generated content, addressing copyright infringement remains a significant challenge. In this paper, we introduce PoisonedParrot: the first stealthy data poisoning attack that induces an LLM to generate copyrighted content even when the model has not been directly trained on the specific copyrighted material. PoisonedParrot integrates small fragments of copyrighted text into the poison samples using an off-the-shelf LLM. Despite its simplicity, evaluated in a wide range of experiments, PoisonedParrot is surprisingly effective at priming the model to generate copyrighted content with no discernible side effects. Moreover, we discover that existing defenses are largely ineffective against our attack. Finally, we make the first attempt at mitigating copyright-infringement poisoning attacks by proposing a defense: ParrotTrap. We encourage the community to explore this emerging threat model further.
Adversarial Robustness of Learning-based Static Malware Classifiers
Mar 20, 2023Malware detection has long been a stage for an ongoing arms race between malware authors and anti-virus systems. Solutions that utilize machine learning (ML) gain traction as the scale of this arms race increases. This trend, however, makes performing attacks directly on ML an attractive prospect for adversaries. We study this arms race from both perspectives in the context of MalConv, a popular convolutional neural network-based malware classifier that operates on raw bytes of files. First, we show that MalConv is vulnerable to adversarial patch attacks: appending a byte-level patch to malware files bypasses detection 94.3% of the time. Moreover, we develop a universal adversarial patch (UAP) attack where a single patch can drop the detection rate in constant time of any malware file that contains it by 80%. These patches are effective even being relatively small with respect to the original file size -- between 2%-8%. As a countermeasure, we then perform window ablation that allows us to apply de-randomized smoothing, a modern certified defense to patch attacks in vision tasks, to raw files. The resulting `smoothed-MalConv' can detect over 80% of malware that contains the universal patch and provides certified robustness up to 66%, outlining a promising step towards robust malware detection. To our knowledge, we are the first to apply universal adversarial patch attack and certified defense using ablations on byte level in the malware field.
On the Effectiveness of Regularization Against Membership Inference Attacks
Jun 09, 2020
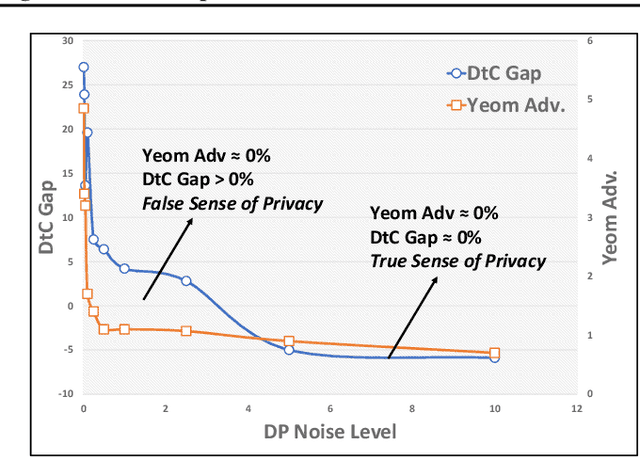
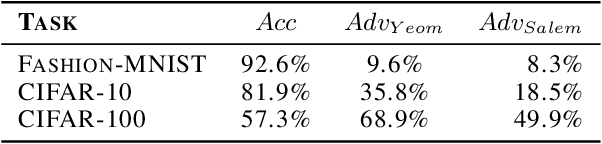
Deep learning models often raise privacy concerns as they leak information about their training data. This enables an adversary to determine whether a data point was in a model's training set by conducting a membership inference attack (MIA). Prior work has conjectured that regularization techniques, which combat overfitting, may also mitigate the leakage. While many regularization mechanisms exist, their effectiveness against MIAs has not been studied systematically, and the resulting privacy properties are not well understood. We explore the lower bound for information leakage that practical attacks can achieve. First, we evaluate the effectiveness of 8 mechanisms in mitigating two recent MIAs, on three standard image classification tasks. We find that certain mechanisms, such as label smoothing, may inadvertently help MIAs. Second, we investigate the potential of improving the resilience to MIAs by combining complementary mechanisms. Finally, we quantify the opportunity of future MIAs to compromise privacy by designing a white-box `distance-to-confident' (DtC) metric, based on adversarial sample crafting. Our metric reveals that, even when existing MIAs fail, the training samples may remain distinguishable from test samples. This suggests that regularization mechanisms can provide a false sense of privacy, even when they appear effective against existing MIAs.
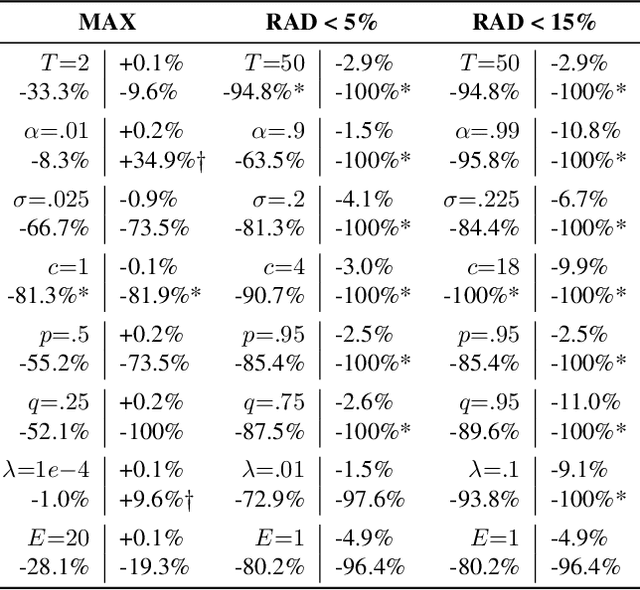
How to Stop Off-the-Shelf Deep Neural Networks from Overthinking
Oct 16, 2018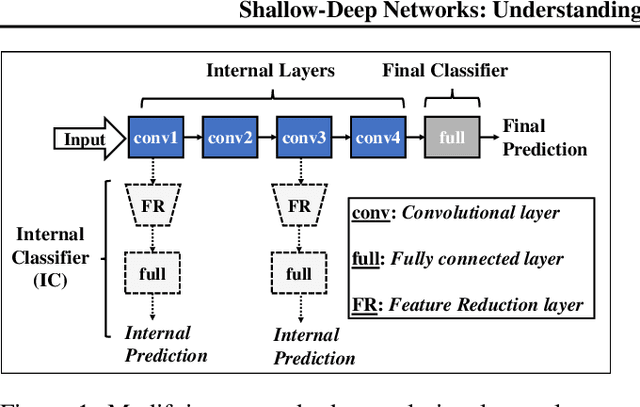
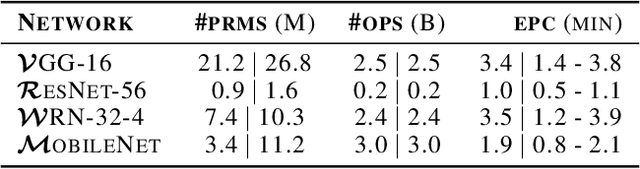
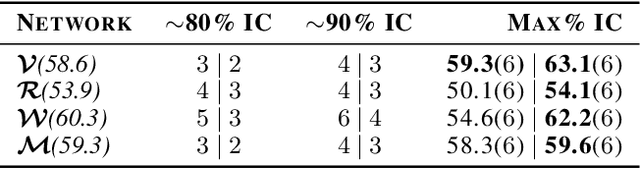
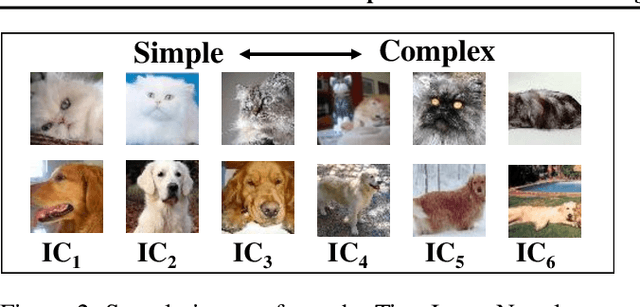
While deep neural networks (DNNs) can perform complex classification tasks, most of their natural inputs do not necessitate the depth of the modern architectures. This leads to wasted computation, as the network overthinks on the simpler inputs. The overthinking problem could be prevented if standard DNNs could produce early predictions. However, prior work suggests that this is challenging in existing architectures, such as ResNet, as their internal layers are not trained for classification and optimizing them for accurate predictions hurts the end performance. In this paper, we explore the overthinking problem, and, as a remedy, we propose a generic modification to off-the-shelf DNNs---the Shallow-Deep Network (SDN). With this modification, a DNN can efficiently produce predictions from either shallow or deep layers, as appropriate for the given input. We employ feature reduction and a layer-wise objective function to train these progressively deeper internal classifiers while preserving the end-performance. We can apply the SDN modification either by training from scratch or by tuning a pre-trained model. Experiments on four architectures (VGG, ResNet, WideResNet, and MobileNet) and three image classifications tasks suggest that, for an average input, an SDN can produce a correct prediction before its middle layer. By avoiding unnecessary computation, the SDN can reduce the required number of operations for an input by 41% over the original network. Finally, we observe that disagreements among the early classifiers reliably indicate inputs where the network is likely to make a mistake. Building on this observation we propose an internal confusion metric and a method to diagnose misclassifications by visualizing these disagreements.