 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Effectiveness of Regularization Against Membership Inference Attacks
Paper and Code
Jun 09, 2020
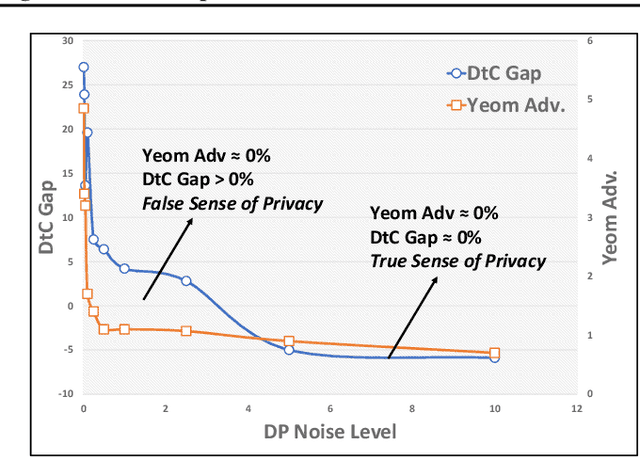
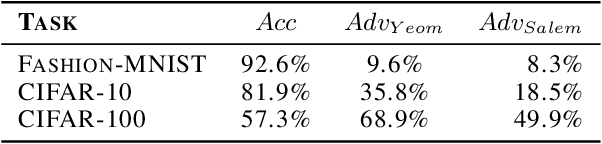
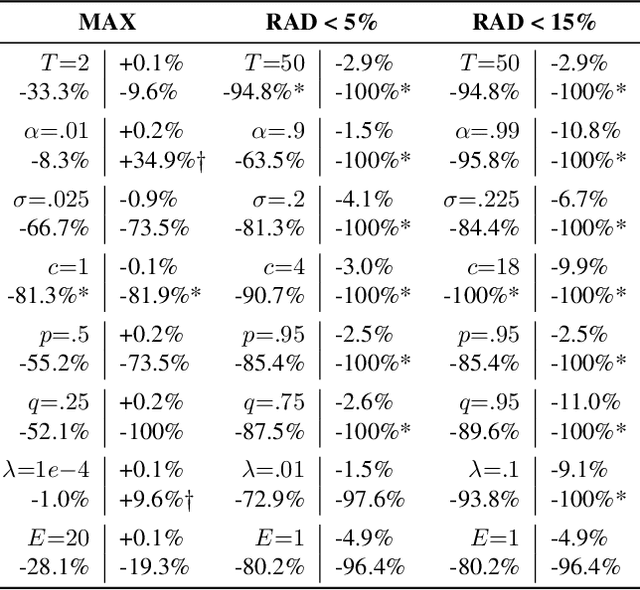
Deep learning models often raise privacy concerns as they leak information about their training data. This enables an adversary to determine whether a data point was in a model's training set by conducting a membership inference attack (MIA). Prior work has conjectured that regularization techniques, which combat overfitting, may also mitigate the leakage. While many regularization mechanisms exist, their effectiveness against MIAs has not been studied systematically, and the resulting privacy properties are not well understood. We explore the lower bound for information leakage that practical attacks can achieve. First, we evaluate the effectiveness of 8 mechanisms in mitigating two recent MIAs, on three standard image classification tasks. We find that certain mechanisms, such as label smoothing, may inadvertently help MIAs. Second, we investigate the potential of improving the resilience to MIAs by combining complementary mechanisms. Finally, we quantify the opportunity of future MIAs to compromise privacy by designing a white-box `distance-to-confident' (DtC) metric, based on adversarial sample crafting. Our metric reveals that, even when existing MIAs fail, the training samples may remain distinguishable from test samples. This suggests that regularization mechanisms can provide a false sense of privacy, even when they appear effective against existing MIAs.