 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow to Stop Off-the-Shelf Deep Neural Networks from Overthinking
Paper and Code
Oct 16, 2018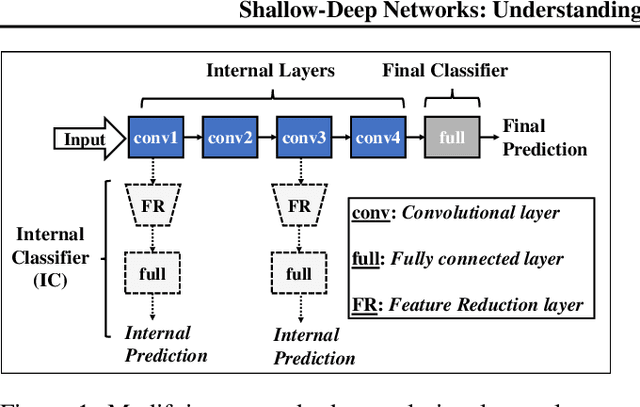
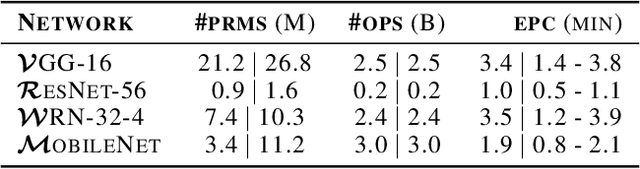
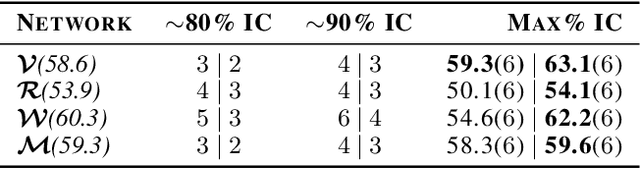
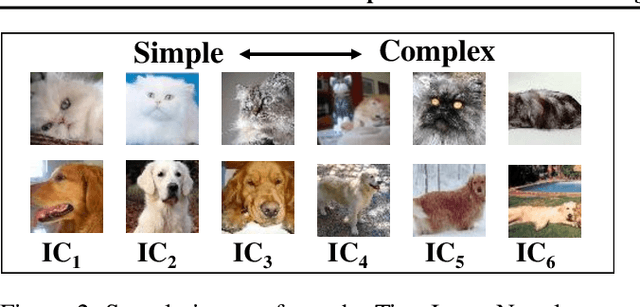
While deep neural networks (DNNs) can perform complex classification tasks, most of their natural inputs do not necessitate the depth of the modern architectures. This leads to wasted computation, as the network overthinks on the simpler inputs. The overthinking problem could be prevented if standard DNNs could produce early predictions. However, prior work suggests that this is challenging in existing architectures, such as ResNet, as their internal layers are not trained for classification and optimizing them for accurate predictions hurts the end performance. In this paper, we explore the overthinking problem, and, as a remedy, we propose a generic modification to off-the-shelf DNNs---the Shallow-Deep Network (SDN). With this modification, a DNN can efficiently produce predictions from either shallow or deep layers, as appropriate for the given input. We employ feature reduction and a layer-wise objective function to train these progressively deeper internal classifiers while preserving the end-performance. We can apply the SDN modification either by training from scratch or by tuning a pre-trained model. Experiments on four architectures (VGG, ResNet, WideResNet, and MobileNet) and three image classifications tasks suggest that, for an average input, an SDN can produce a correct prediction before its middle layer. By avoiding unnecessary computation, the SDN can reduce the required number of operations for an input by 41% over the original network. Finally, we observe that disagreements among the early classifiers reliably indicate inputs where the network is likely to make a mistake. Building on this observation we propose an internal confusion metric and a method to diagnose misclassifications by visualizing these disagreements.