 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSingle-step Adversarial training with Dropout Scheduling
Apr 18, 2020



Deep learning models have shown impressive performance across a spectrum of computer vision applications including medical diagnosis and autonomous driving. One of the major concerns that these models face is their susceptibility to adversarial attacks. Realizing the importance of this issue, more researchers are working towards developing robust models that are less affected by adversarial attacks. Adversarial training method shows promising results in this direction. In adversarial training regime, models are trained with mini-batches augmented with adversarial samples. Fast and simple methods (e.g., single-step gradient ascent) are used for generating adversarial samples, in order to reduce computational complexity. It is shown that models trained using single-step adversarial training method (adversarial samples are generated using non-iterative method) are pseudo robust. Further, this pseudo robustness of models is attributed to the gradient masking effect. However, existing works fail to explain when and why gradient masking effect occurs during single-step adversarial training. In this work, (i) we show that models trained using single-step adversarial training method learn to prevent the generation of single-step adversaries, and this is due to over-fitting of the model during the initial stages of training, and (ii) to mitigate this effect, we propose a single-step adversarial training method with dropout scheduling. Unlike models trained using existing single-step adversarial training methods, models trained using the proposed single-step adversarial training method are robust against both single-step and multi-step adversarial attacks, and the performance is on par with models trained using computationally expensive multi-step adversarial training methods, in white-box and black-box settings.
Towards Achieving Adversarial Robustness by Enforcing Feature Consistency Across Bit Planes
Apr 01, 2020
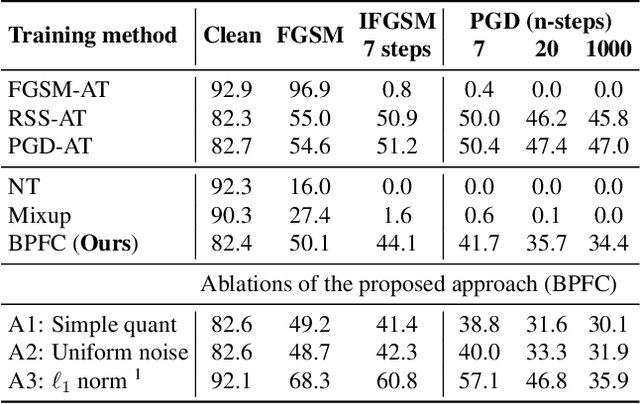

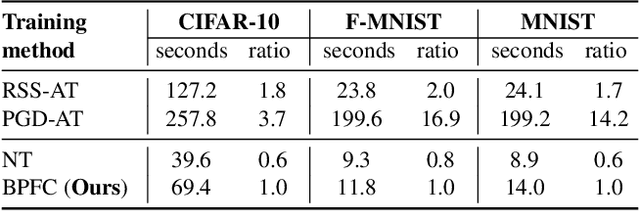
As humans, we inherently perceive images based on their predominant features, and ignore noise embedded within lower bit planes. On the contrary, Deep Neural Networks are known to confidently misclassify images corrupted with meticulously crafted perturbations that are nearly imperceptible to the human eye. In this work, we attempt to address this problem by training networks to form coarse impressions based on the information in higher bit planes, and use the lower bit planes only to refine their prediction. We demonstrate that, by imposing consistency on the representations learned across differently quantized images, the adversarial robustness of networks improves significantly when compared to a normally trained model. Present state-of-the-art defenses against adversarial attacks require the networks to be explicitly trained using adversarial samples that are computationally expensive to generate. While such methods that use adversarial training continue to achieve the best results, this work paves the way towards achieving robustness without having to explicitly train on adversarial samples. The proposed approach is therefore faster, and also closer to the natural learning process in humans.
Gray-box Adversarial Training
Aug 06, 2018


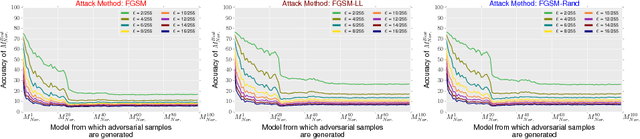
Adversarial samples are perturbed inputs crafted to mislead the machine learning systems. A training mechanism, called adversarial training, which presents adversarial samples along with clean samples has been introduced to learn robust models. In order to scale adversarial training for large datasets, these perturbations can only be crafted using fast and simple methods (e.g., gradient ascent). However, it is shown that adversarial training converges to a degenerate minimum, where the model appears to be robust by generating weaker adversaries. As a result, the models are vulnerable to simple black-box attacks. In this paper we, (i) demonstrate the shortcomings of existing evaluation policy, (ii) introduce novel variants of white-box and black-box attacks, dubbed gray-box adversarial attacks" based on which we propose novel evaluation method to assess the robustness of the learned models, and (iii) propose a novel variant of adversarial training, named Graybox Adversarial Training" that uses intermediate versions of the models to seed the adversaries. Experimental evaluation demonstrates that the models trained using our method exhibit better robustness compared to both undefended and adversarially trained model