 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Robust Conformal Prediction via Lipschitz-Bounded Networks
Jun 05, 2025



Conformal Prediction (CP) has proven to be an effective post-hoc method for improving the trustworthiness of neural networks by providing prediction sets with finite-sample guarantees. However, under adversarial attacks, classical conformal guarantees do not hold anymore: this problem is addressed in the field of Robust Conformal Prediction. Several methods have been proposed to provide robust CP sets with guarantees under adversarial perturbations, but, for large scale problems, these sets are either too large or the methods are too computationally demanding to be deployed in real life scenarios. In this work, we propose a new method that leverages Lipschitz-bounded networks to precisely and efficiently estimate robust CP sets. When combined with a 1-Lipschitz robust network, we demonstrate that our lip-rcp method outperforms state-of-the-art results in both the size of the robust CP sets and computational efficiency in medium and large-scale scenarios such as ImageNet. Taking a different angle, we also study vanilla CP under attack, and derive new worst-case coverage bounds of vanilla CP sets, which are valid simultaneously for all adversarial attack levels. Our lip-rcp method makes this second approach as efficient as vanilla CP while also allowing robustness guarantees.
Robust Vision-Based Runway Detection through Conformal Prediction and Conformal mAP
May 22, 2025



We explore the use of conformal prediction to provide statistical uncertainty guarantees for runway detection in vision-based landing systems (VLS). Using fine-tuned YOLOv5 and YOLOv6 models on aerial imagery, we apply conformal prediction to quantify localization reliability under user-defined risk levels. We also introduce Conformal mean Average Precision (C-mAP), a novel metric aligning object detection performance with conformal guarantees. Our results show that conformal prediction can improve the reliability of runway detection by quantifying uncertainty in a statistically sound way, increasing safety on-board and paving the way for certification of ML system in the aerospace domain.
A Holistic Approach to Unifying Automatic Concept Extraction and Concept Importance Estimation
Jun 11, 2023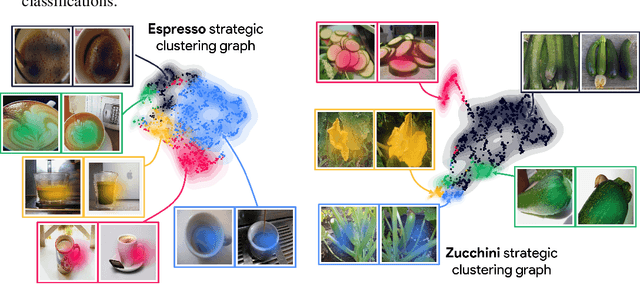


In recent years, concept-based approaches have emerged as some of the most promising explainability methods to help us interpret the decisions of Artificial Neural Networks (ANNs). These methods seek to discover intelligible visual 'concepts' buried within the complex patterns of ANN activations in two key steps: (1) concept extraction followed by (2) importance estimation. While these two steps are shared across methods, they all differ in their specific implementations. Here, we introduce a unifying theoretical framework that comprehensively defines and clarifies these two steps. This framework offers several advantages as it allows us: (i) to propose new evaluation metrics for comparing different concept extraction approaches; (ii) to leverage modern attribution methods and evaluation metrics to extend and systematically evaluate state-of-the-art concept-based approaches and importance estimation techniques; (iii) to derive theoretical guarantees regarding the optimality of such methods. We further leverage our framework to try to tackle a crucial question in explainability: how to efficiently identify clusters of data points that are classified based on a similar shared strategy. To illustrate these findings and to highlight the main strategies of a model, we introduce a visual representation called the strategic cluster graph. Finally, we present https://serre-lab.github.io/Lens, a dedicated website that offers a complete compilation of these visualizations for all classes of the ImageNet dataset.
Confident Object Detection via Conformal Prediction and Conformal Risk Control: an Application to Railway Signaling
Apr 17, 2023



Deploying deep learning models in real-world certified systems requires the ability to provide confidence estimates that accurately reflect their uncertainty. In this paper, we demonstrate the use of the conformal prediction framework to construct reliable and trustworthy predictors for detecting railway signals. Our approach is based on a novel dataset that includes images taken from the perspective of a train operator and state-of-the-art object detectors. We test several conformal approaches and introduce a new method based on conformal risk control. Our findings demonstrate the potential of the conformal prediction framework to evaluate model performance and provide practical guidance for achieving formally guaranteed uncertainty bounds.
Towards Understanding the Mechanism of Contrastive Learning via Similarity Structure: A Theoretical Analysis
Apr 01, 2023



Contrastive learning is an efficient approach to self-supervised representation learning. Although recent studies have made progress in the theoretical understanding of contrastive learning, the investigation of how to characterize the clusters of the learned representations is still limited. In this paper, we aim to elucidate the characterization from theoretical perspectives. To this end, we consider a kernel-based contrastive learning framework termed Kernel Contrastive Learning (KCL), where kernel functions play an important role when applying our theoretical results to other frameworks. We introduce a formulation of the similarity structure of learned representations by utilizing a statistical dependency viewpoint. We investigate the theoretical properties of the kernel-based contrastive loss via this formulation. We first prove that the formulation characterizes the structure of representations learned with the kernel-based contrastive learning framework. We show a new upper bound of the classification error of a downstream task, which explains that our theory is consistent with the empirical success of contrastive learning. We also establish a generalization error bound of KCL. Finally, we show a guarantee for the generalization ability of KCL to the downstream classification task via a surrogate bound.