 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling-based Data Augmentation for Generative Models and its Theoretical Extension
Oct 28, 2024



This paper studies stable learning methods for generative models that enable high-quality data generation. Noise injection is commonly used to stabilize learning. However, selecting a suitable noise distribution is challenging. Diffusion-GAN, a recently developed method, addresses this by using the diffusion process with a timestep-dependent discriminator. We investigate Diffusion-GAN and reveal that data scaling is a key component for stable learning and high-quality data generation. Building on our findings, we propose a learning algorithm, Scale-GAN, that uses data scaling and variance-based regularization. Furthermore, we theoretically prove that data scaling controls the bias-variance trade-off of the estimation error bound. As a theoretical extension, we consider GAN with invertible data augmentations. Comparative evaluations on benchmark datasets demonstrate the effectiveness of our method in improving stability and accuracy.
Robust VAEs via Generating Process of Noise Augmented Data
Jul 26, 2024


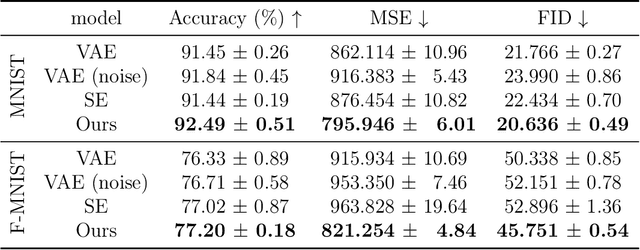
Advancing defensive mechanisms against adversarial attacks in generative models is a critical research topic in machine learning. Our study focuses on a specific type of generative models - Variational Auto-Encoders (VAEs). Contrary to common beliefs and existing literature which suggest that noise injection towards training data can make models more robust, our preliminary experiments revealed that naive usage of noise augmentation technique did not substantially improve VAE robustness. In fact, it even degraded the quality of learned representations, making VAEs more susceptible to adversarial perturbations. This paper introduces a novel framework that enhances robustness by regularizing the latent space divergence between original and noise-augmented data. Through incorporating a paired probabilistic prior into the standard variational lower bound, our method significantly boosts defense against adversarial attacks. Our empirical evaluations demonstrate that this approach, termed Robust Augmented Variational Auto-ENcoder (RAVEN), yields superior performance in resisting adversarial inputs on widely-recognized benchmark datasets.
Investigating Self-Supervised Image Denoising with Denaturation
May 02, 2024Self-supervised learning for image denoising problems in the presence of denaturation for noisy data is a crucial approach in machine learning. However, theoretical understanding of the performance of the approach that uses denatured data is lacking. To provide better understanding of the approach, in this paper, we analyze a self-supervised denoising algorithm that uses denatured data in depth through theoretical analysis and numerical experiments. Through the theoretical analysis, we discuss that the algorithm finds desired solutions to the optimization problem with the population risk, while the guarantee for the empirical risk depends on the hardness of the denoising task in terms of denaturation levels. We also conduct several experiments to investigate the performance of an extended algorithm in practice. The results indicate that the algorithm training with denatured images works, and the empirical performance aligns with the theoretical results. These results suggest several insights for further improvement of self-supervised image denoising that uses denatured data in future directions.
Denoising Cosine Similarity: A Theory-Driven Approach for Efficient Representation Learning
Apr 19, 2023



Representation learning has been increasing its impact on the research and practice of machine learning, since it enables to learn representations that can apply to various downstream tasks efficiently. However, recent works pay little attention to the fact that real-world datasets used during the stage of representation learning are commonly contaminated by noise, which can degrade the quality of learned representations. This paper tackles the problem to learn robust representations against noise in a raw dataset. To this end, inspired by recent works on denoising and the success of the cosine-similarity-based objective functions in representation learning, we propose the denoising Cosine-Similarity (dCS) loss. The dCS loss is a modified cosine-similarity loss and incorporates a denoising property, which is supported by both our theoretical and empirical findings. To make the dCS loss implementable, we also construct the estimators of the dCS loss with statistical guarantees. Finally, we empirically show the efficiency of the dCS loss over the baseline objective functions in vision and speech domains.
Towards Understanding the Mechanism of Contrastive Learning via Similarity Structure: A Theoretical Analysis
Apr 01, 2023



Contrastive learning is an efficient approach to self-supervised representation learning. Although recent studies have made progress in the theoretical understanding of contrastive learning, the investigation of how to characterize the clusters of the learned representations is still limited. In this paper, we aim to elucidate the characterization from theoretical perspectives. To this end, we consider a kernel-based contrastive learning framework termed Kernel Contrastive Learning (KCL), where kernel functions play an important role when applying our theoretical results to other frameworks. We introduce a formulation of the similarity structure of learned representations by utilizing a statistical dependency viewpoint. We investigate the theoretical properties of the kernel-based contrastive loss via this formulation. We first prove that the formulation characterizes the structure of representations learned with the kernel-based contrastive learning framework. We show a new upper bound of the classification error of a downstream task, which explains that our theory is consistent with the empirical success of contrastive learning. We also establish a generalization error bound of KCL. Finally, we show a guarantee for the generalization ability of KCL to the downstream classification task via a surrogate bound.
Deep Clustering with a Constraint for Topological Invariance based on Symmetric InfoNCE
Mar 06, 2023We consider the scenario of deep clustering, in which the available prior knowledge is limited. In this scenario, few existing state-of-the-art deep clustering methods can perform well for both non-complex topology and complex topology datasets. To address the problem, we propose a constraint utilizing symmetric InfoNCE, which helps an objective of deep clustering method in the scenario train the model so as to be efficient for not only non-complex topology but also complex topology datasets. Additionally, we provide several theoretical explanations of the reason why the constraint can enhances performance of deep clustering methods. To confirm the effectiveness of the proposed constraint, we introduce a deep clustering method named MIST, which is a combination of an existing deep clustering method and our constraint. Our numerical experiments via MIST demonstrate that the constraint is effective. In addition, MIST outperforms other state-of-the-art deep clustering methods for most of the commonly used ten benchmark datasets.