 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTULiP: Test-time Uncertainty Estimation via Linearization and Weight Perturbation
May 22, 2025A reliable uncertainty estimation method is the foundation of many modern out-of-distribution (OOD) detectors, which are critical for safe deployments of deep learning models in the open world. In this work, we propose TULiP, a theoretically-driven post-hoc uncertainty estimator for OOD detection. Our approach considers a hypothetical perturbation applied to the network before convergence. Based on linearized training dynamics, we bound the effect of such perturbation, resulting in an uncertainty score computable by perturbing model parameters. Ultimately, our approach computes uncertainty from a set of sampled predictions. We visualize our bound on synthetic regression and classification datasets. Furthermore, we demonstrate the effectiveness of TULiP using large-scale OOD detection benchmarks for image classification. Our method exhibits state-of-the-art performance, particularly for near-distribution samples.
Robust VAEs via Generating Process of Noise Augmented Data
Jul 26, 2024


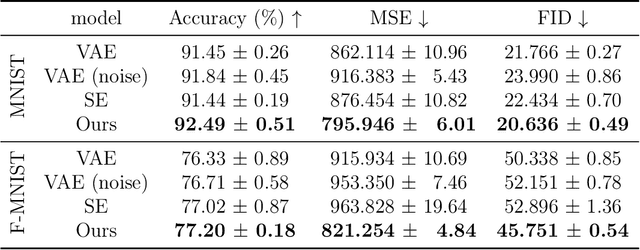
Advancing defensive mechanisms against adversarial attacks in generative models is a critical research topic in machine learning. Our study focuses on a specific type of generative models - Variational Auto-Encoders (VAEs). Contrary to common beliefs and existing literature which suggest that noise injection towards training data can make models more robust, our preliminary experiments revealed that naive usage of noise augmentation technique did not substantially improve VAE robustness. In fact, it even degraded the quality of learned representations, making VAEs more susceptible to adversarial perturbations. This paper introduces a novel framework that enhances robustness by regularizing the latent space divergence between original and noise-augmented data. Through incorporating a paired probabilistic prior into the standard variational lower bound, our method significantly boosts defense against adversarial attacks. Our empirical evaluations demonstrate that this approach, termed Robust Augmented Variational Auto-ENcoder (RAVEN), yields superior performance in resisting adversarial inputs on widely-recognized benchmark datasets.
Investigating Self-Supervised Image Denoising with Denaturation
May 02, 2024Self-supervised learning for image denoising problems in the presence of denaturation for noisy data is a crucial approach in machine learning. However, theoretical understanding of the performance of the approach that uses denatured data is lacking. To provide better understanding of the approach, in this paper, we analyze a self-supervised denoising algorithm that uses denatured data in depth through theoretical analysis and numerical experiments. Through the theoretical analysis, we discuss that the algorithm finds desired solutions to the optimization problem with the population risk, while the guarantee for the empirical risk depends on the hardness of the denoising task in terms of denaturation levels. We also conduct several experiments to investigate the performance of an extended algorithm in practice. The results indicate that the algorithm training with denatured images works, and the empirical performance aligns with the theoretical results. These results suggest several insights for further improvement of self-supervised image denoising that uses denatured data in future directions.
Denoising Cosine Similarity: A Theory-Driven Approach for Efficient Representation Learning
Apr 19, 2023



Representation learning has been increasing its impact on the research and practice of machine learning, since it enables to learn representations that can apply to various downstream tasks efficiently. However, recent works pay little attention to the fact that real-world datasets used during the stage of representation learning are commonly contaminated by noise, which can degrade the quality of learned representations. This paper tackles the problem to learn robust representations against noise in a raw dataset. To this end, inspired by recent works on denoising and the success of the cosine-similarity-based objective functions in representation learning, we propose the denoising Cosine-Similarity (dCS) loss. The dCS loss is a modified cosine-similarity loss and incorporates a denoising property, which is supported by both our theoretical and empirical findings. To make the dCS loss implementable, we also construct the estimators of the dCS loss with statistical guarantees. Finally, we empirically show the efficiency of the dCS loss over the baseline objective functions in vision and speech domains.
Towards Understanding the Mechanism of Contrastive Learning via Similarity Structure: A Theoretical Analysis
Apr 01, 2023



Contrastive learning is an efficient approach to self-supervised representation learning. Although recent studies have made progress in the theoretical understanding of contrastive learning, the investigation of how to characterize the clusters of the learned representations is still limited. In this paper, we aim to elucidate the characterization from theoretical perspectives. To this end, we consider a kernel-based contrastive learning framework termed Kernel Contrastive Learning (KCL), where kernel functions play an important role when applying our theoretical results to other frameworks. We introduce a formulation of the similarity structure of learned representations by utilizing a statistical dependency viewpoint. We investigate the theoretical properties of the kernel-based contrastive loss via this formulation. We first prove that the formulation characterizes the structure of representations learned with the kernel-based contrastive learning framework. We show a new upper bound of the classification error of a downstream task, which explains that our theory is consistent with the empirical success of contrastive learning. We also establish a generalization error bound of KCL. Finally, we show a guarantee for the generalization ability of KCL to the downstream classification task via a surrogate bound.
Fast and Multi-aspect Mining of Complex Time-stamped Event Streams
Mar 07, 2023



Given a huge, online stream of time-evolving events with multiple attributes, such as online shopping logs: (item, price, brand, time), and local mobility activities: (pick-up and drop-off locations, time), how can we summarize large, dynamic high-order tensor streams? How can we see any hidden patterns, rules, and anomalies? Our answer is to focus on two types of patterns, i.e., ''regimes'' and ''components'', for which we present CubeScope, an efficient and effective method over high-order tensor streams. Specifically, it identifies any sudden discontinuity and recognizes distinct dynamical patterns, ''regimes'' (e.g., weekday/weekend/holiday patterns). In each regime, it also performs multi-way summarization for all attributes (e.g., item, price, brand, and time) and discovers hidden ''components'' representing latent groups (e.g., item/brand groups) and their relationship. Thanks to its concise but effective summarization, CubeScope can also detect the sudden appearance of anomalies and identify the types of anomalies that occur in practice. Our proposed method has the following properties: (a) Effective: it captures dynamical multi-aspect patterns, i.e., regimes and components, and statistically summarizes all the events; (b) General: it is practical for successful application to data compression, pattern discovery, and anomaly detection on various types of tensor streams; (c) Scalable: our algorithm does not depend on the length of the data stream and its dimensionality. Extensive experiments on real datasets demonstrate that CubeScope finds meaningful patterns and anomalies correctly, and consistently outperforms the state-of-the-art methods as regards accuracy and execution speed.
Deep Clustering with a Constraint for Topological Invariance based on Symmetric InfoNCE
Mar 06, 2023We consider the scenario of deep clustering, in which the available prior knowledge is limited. In this scenario, few existing state-of-the-art deep clustering methods can perform well for both non-complex topology and complex topology datasets. To address the problem, we propose a constraint utilizing symmetric InfoNCE, which helps an objective of deep clustering method in the scenario train the model so as to be efficient for not only non-complex topology but also complex topology datasets. Additionally, we provide several theoretical explanations of the reason why the constraint can enhances performance of deep clustering methods. To confirm the effectiveness of the proposed constraint, we introduce a deep clustering method named MIST, which is a combination of an existing deep clustering method and our constraint. Our numerical experiments via MIST demonstrate that the constraint is effective. In addition, MIST outperforms other state-of-the-art deep clustering methods for most of the commonly used ten benchmark datasets.
Learning Domain Invariant Representations by Joint Wasserstein Distance Minimization
Jun 09, 2021
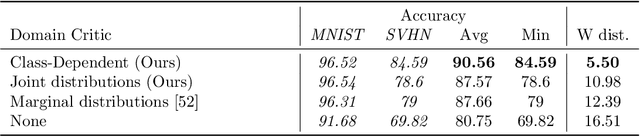


Domain shifts in the training data are common in practical applications of machine learning, they occur for instance when the data is coming from different sources. Ideally, a ML model should work well independently of these shifts, for example, by learning a domain-invariant representation. Moreover, privacy concerns regarding the source also require a domain-invariant representation. In this work, we provide theoretical results that link domain invariant representations -- measured by the Wasserstein distance on the joint distributions -- to a practical semi-supervised learning objective based on a cross-entropy classifier and a novel domain critic. Quantitative experiments demonstrate that the proposed approach is indeed able to practically learn such an invariant representation (between two domains), and the latter also supports models with higher predictive accuracy on both domains, comparing favorably to existing techniques.