 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Domain Invariant Representations by Joint Wasserstein Distance Minimization
Paper and Code

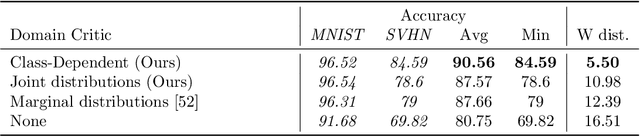


Domain shifts in the training data are common in practical applications of machine learning, they occur for instance when the data is coming from different sources. Ideally, a ML model should work well independently of these shifts, for example, by learning a domain-invariant representation. Moreover, privacy concerns regarding the source also require a domain-invariant representation. In this work, we provide theoretical results that link domain invariant representations -- measured by the Wasserstein distance on the joint distributions -- to a practical semi-supervised learning objective based on a cross-entropy classifier and a novel domain critic. Quantitative experiments demonstrate that the proposed approach is indeed able to practically learn such an invariant representation (between two domains), and the latter also supports models with higher predictive accuracy on both domains, comparing favorably to existing techniques.