 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaster's Thesis : Deep Learning for Visual Recognition
Paper and Code
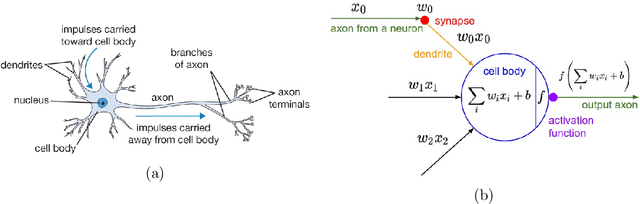



The goal of our research is to develop methods advancing automatic visual recognition. In order to predict the unique or multiple labels associated to an image, we study different kind of Deep Neural Networks architectures and methods for supervised features learning. We first draw up a state-of-the-art review of the Convolutional Neural Networks aiming to understand the history behind this family of statistical models, the limit of modern architectures and the novel techniques currently used to train deep CNNs. The originality of our work lies in our approach focusing on tasks with a low amount of data. We introduce different models and techniques to achieve the best accuracy on several kind of datasets, such as a medium dataset of food recipes (100k images) for building a web API, or a small dataset of satellite images (6,000) for the DSG online challenge that we've won. We also draw up the state-of-the-art in Weakly Supervised Learning, introducing different kind of CNNs able to localize regions of interest. Our last contribution is a framework, build on top of Torch7, for training and testing deep models on any visual recognition tasks and on datasets of any scale.