 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExposing the Illusion of Fairness: Auditing Vulnerabilities to Distributional Manipulation Attacks
Jul 28, 2025Proving the compliance of AI algorithms has become an important challenge with the growing deployment of such algorithms for real-life applications. Inspecting possible biased behaviors is mandatory to satisfy the constraints of the regulations of the EU Artificial Intelligence's Act. Regulation-driven audits increasingly rely on global fairness metrics, with Disparate Impact being the most widely used. Yet such global measures depend highly on the distribution of the sample on which the measures are computed. We investigate first how to manipulate data samples to artificially satisfy fairness criteria, creating minimally perturbed datasets that remain statistically indistinguishable from the original distribution while satisfying prescribed fairness constraints. Then we study how to detect such manipulation. Our analysis (i) introduces mathematically sound methods for modifying empirical distributions under fairness constraints using entropic or optimal transport projections, (ii) examines how an auditee could potentially circumvent fairness inspections, and (iii) offers recommendations to help auditors detect such data manipulations. These results are validated through experiments on classical tabular datasets in bias detection.
IMITATE: Image Registration with Context for unknown time frame recovery
May 15, 2025In this paper, we formulate a novel image registration formalism dedicated to the estimation of unknown condition-related images, based on two or more known images and their associated conditions. We show how to practically model this formalism by using a new conditional U-Net architecture, which fully takes into account the conditional information and does not need any fixed image. Our formalism is then applied to image moving tumors for radiotherapy treatment at different breathing amplitude using 4D-CT (3D+t) scans in thoracoabdominal regions. This driving application is particularly complex as it requires to stitch a collection of sequential 2D slices into several 3D volumes at different organ positions. Movement interpolation with standard methods then generates well known reconstruction artefacts in the assembled volumes due to irregular patient breathing, hysteresis and poor correlation of breathing signal to internal motion. Results obtained on 4D-CT clinical data showcase artefact-free volumes achieved through real-time latencies. The code is publicly available at https://github.com/Kheil-Z/IMITATE .
* IEEE ISBI 2025
Biomechanical Constraints Assimilation in Deep-Learning Image Registration: Application to sliding and locally rigid deformations
Apr 07, 2025Regularization strategies in medical image registration often take a one-size-fits-all approach by imposing uniform constraints across the entire image domain. Yet biological structures are anything but regular. Lacking structural awareness, these strategies may fail to consider a panoply of spatially inhomogeneous deformation properties, which would faithfully account for the biomechanics of soft and hard tissues, especially in poorly contrasted structures. To bridge this gap, we propose a learning-based image registration approach in which the inferred deformation properties can locally adapt themselves to trained biomechanical characteristics. Specifically, we first enforce in the training process local rigid displacements, shearing motions or pseudo-elastic deformations using regularization losses inspired from the field of solid-mechanics. We then show on synthetic and real 3D thoracic and abdominal images that these mechanical properties of different nature are well generalized when inferring the deformations between new image pairs. Our approach enables neural-networks to infer tissue-specific deformation patterns directly from input images, ensuring mechanically plausible motion. These networks preserve rigidity within hard tissues while allowing controlled sliding in regions where tissues naturally separate, more faithfully capturing physiological motion. The code is publicly available at https://github.com/Kheil-Z/biomechanical_DLIR .
Debiasing Machine Learning Models by Using Weakly Supervised Learning
Feb 23, 2024



We tackle the problem of bias mitigation of algorithmic decisions in a setting where both the output of the algorithm and the sensitive variable are continuous. Most of prior work deals with discrete sensitive variables, meaning that the biases are measured for subgroups of persons defined by a label, leaving out important algorithmic bias cases, where the sensitive variable is continuous. Typical examples are unfair decisions made with respect to the age or the financial status. In our work, we then propose a bias mitigation strategy for continuous sensitive variables, based on the notion of endogeneity which comes from the field of econometrics. In addition to solve this new problem, our bias mitigation strategy is a weakly supervised learning method which requires that a small portion of the data can be measured in a fair manner. It is model agnostic, in the sense that it does not make any hypothesis on the prediction model. It also makes use of a reasonably large amount of input observations and their corresponding predictions. Only a small fraction of the true output predictions should be known. This therefore limits the need for expert interventions. Results obtained on synthetic data show the effectiveness of our approach for examples as close as possible to real-life applications in econometrics.
TaCo: Targeted Concept Removal in Output Embeddings for NLP via Information Theory and Explainability
Dec 11, 2023
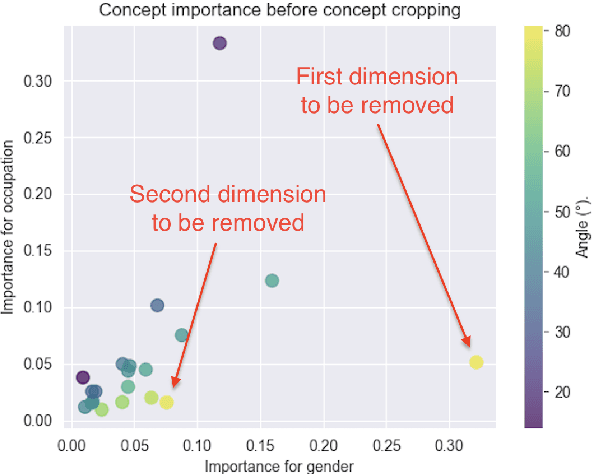
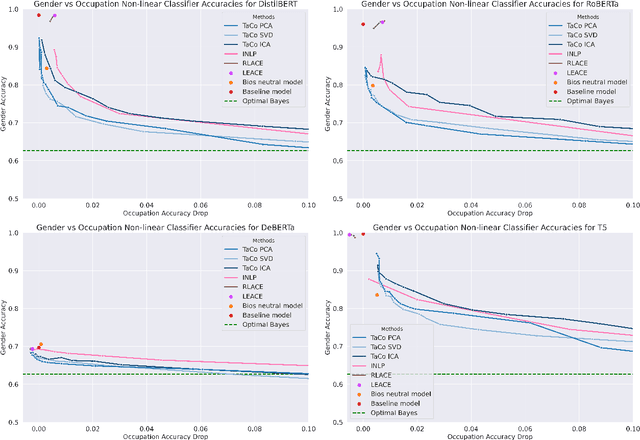
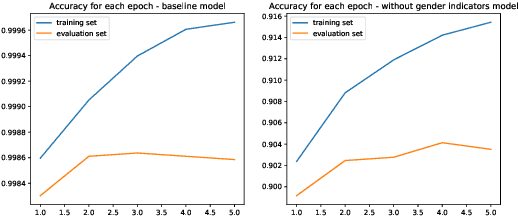
The fairness of Natural Language Processing (NLP) models has emerged as a crucial concern. Information theory indicates that to achieve fairness, a model should not be able to predict sensitive variables, such as gender, ethnicity, and age. However, information related to these variables often appears implicitly in language, posing a challenge in identifying and mitigating biases effectively. To tackle this issue, we present a novel approach that operates at the embedding level of an NLP model, independent of the specific architecture. Our method leverages insights from recent advances in XAI techniques and employs an embedding transformation to eliminate implicit information from a selected variable. By directly manipulating the embeddings in the final layer, our approach enables a seamless integration into existing models without requiring significant modifications or retraining. In evaluation, we show that the proposed post-hoc approach significantly reduces gender-related associations in NLP models while preserving the overall performance and functionality of the models. An implementation of our method is available: https://github.com/fanny-jourdan/TaCo
Toulouse Hyperspectral Data Set: a benchmark data set to assess semi-supervised spectral representation learning and pixel-wise classification techniques
Nov 15, 2023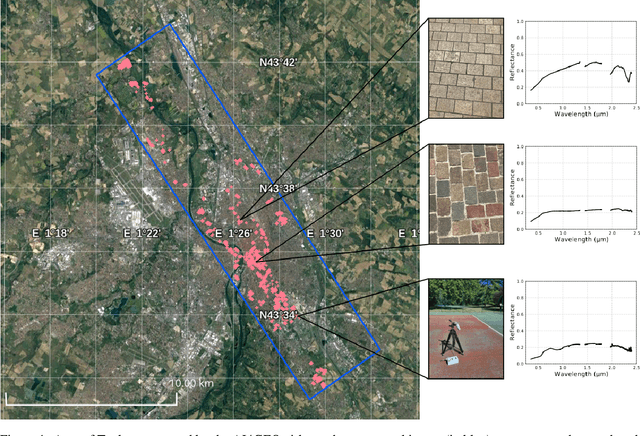



Airborne hyperspectral images can be used to map the land cover in large urban areas, thanks to their very high spatial and spectral resolutions on a wide spectral domain. While the spectral dimension of hyperspectral images is highly informative of the chemical composition of the land surface, the use of state-of-the-art machine learning algorithms to map the land cover has been dramatically limited by the availability of training data. To cope with the scarcity of annotations, semi-supervised and self-supervised techniques have lately raised a lot of interest in the community. Yet, the publicly available hyperspectral data sets commonly used to benchmark machine learning models are not totally suited to evaluate their generalization performances due to one or several of the following properties: a limited geographical coverage (which does not reflect the spectral diversity in metropolitan areas), a small number of land cover classes and a lack of appropriate standard train / test splits for semi-supervised and self-supervised learning. Therefore, we release in this paper the Toulouse Hyperspectral Data Set that stands out from other data sets in the above-mentioned respects in order to meet key issues in spectral representation learning and classification over large-scale hyperspectral images with very few labeled pixels. Besides, we discuss and experiment the self-supervised task of Masked Autoencoders and establish a baseline for pixel-wise classification based on a conventional autoencoder combined with a Random Forest classifier achieving 82% overall accuracy and 74% F1 score. The Toulouse Hyperspectral Data Set and our code are publicly available at https://www.toulouse-hyperspectral-data-set.com and https://www.github.com/Romain3Ch216/tlse-experiments, respectively.
Are fairness metric scores enough to assess discrimination biases in machine learning?
Jun 08, 2023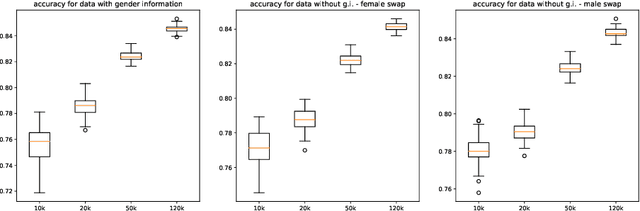
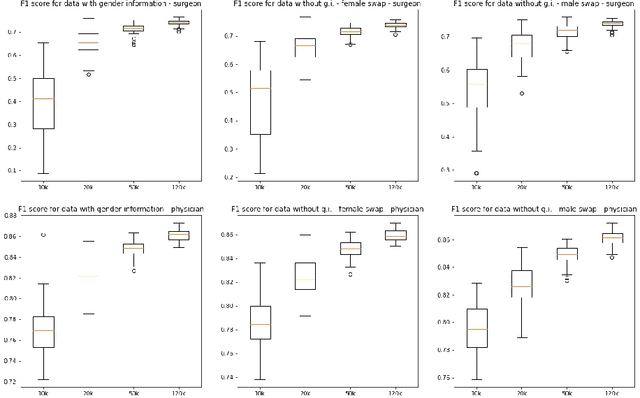
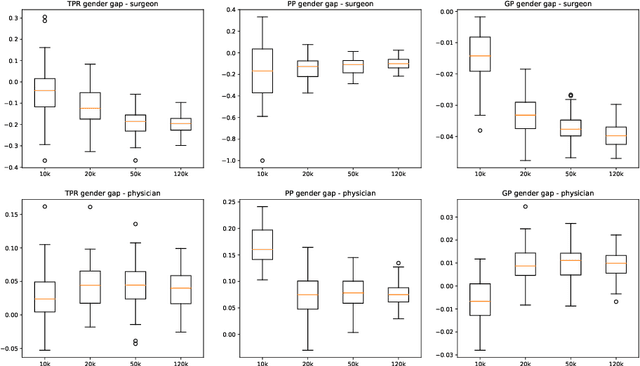
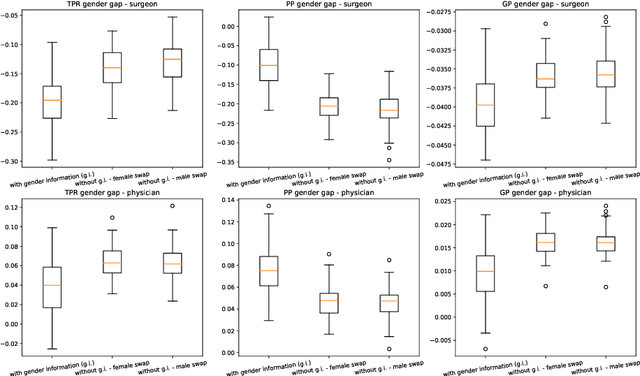
This paper presents novel experiments shedding light on the shortcomings of current metrics for assessing biases of gender discrimination made by machine learning algorithms on textual data. We focus on the Bios dataset, and our learning task is to predict the occupation of individuals, based on their biography. Such prediction tasks are common in commercial Natural Language Processing (NLP) applications such as automatic job recommendations. We address an important limitation of theoretical discussions dealing with group-wise fairness metrics: they focus on large datasets, although the norm in many industrial NLP applications is to use small to reasonably large linguistic datasets for which the main practical constraint is to get a good prediction accuracy. We then question how reliable are different popular measures of bias when the size of the training set is simply sufficient to learn reasonably accurate predictions. Our experiments sample the Bios dataset and learn more than 200 models on different sample sizes. This allows us to statistically study our results and to confirm that common gender bias indices provide diverging and sometimes unreliable results when applied to relatively small training and test samples. This highlights the crucial importance of variance calculations for providing sound results in this field.
COCKATIEL: COntinuous Concept ranKed ATtribution with Interpretable ELements for explaining neural net classifiers on NLP tasks
May 14, 2023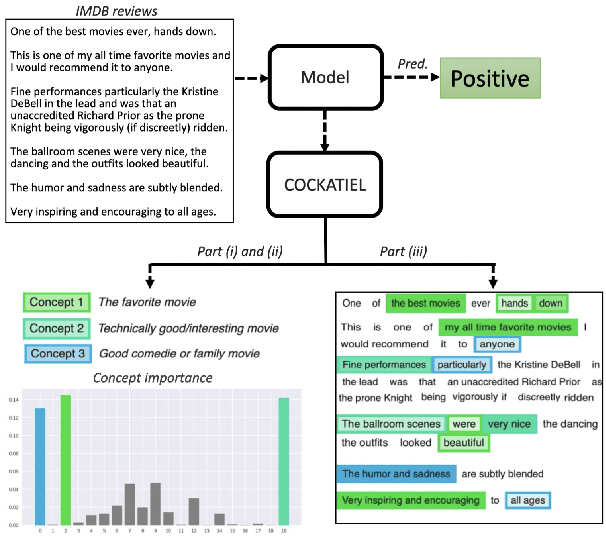
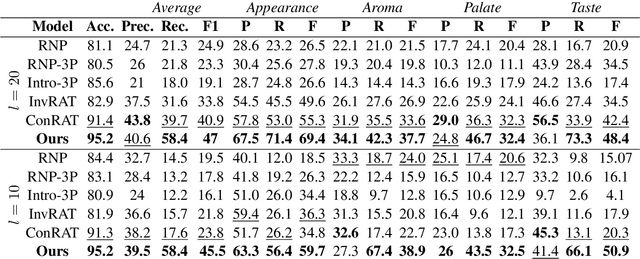
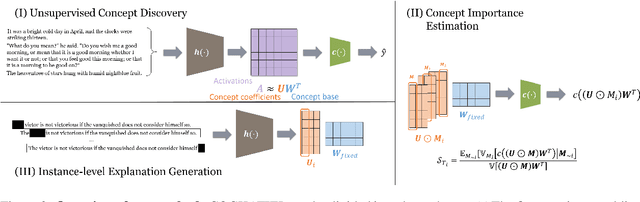
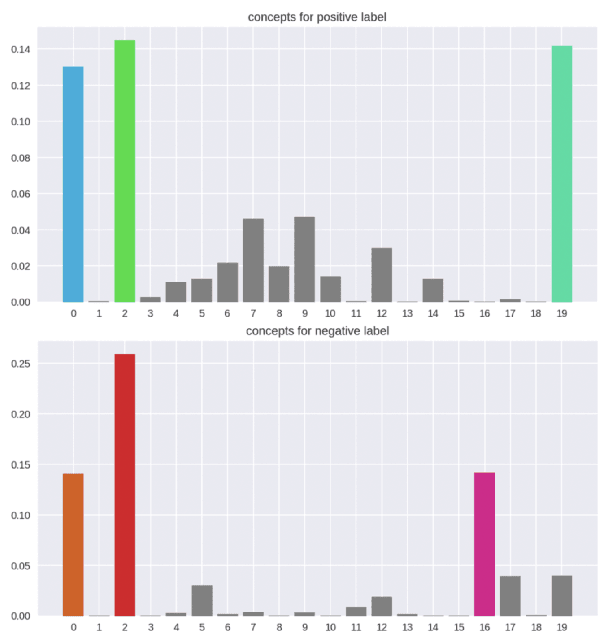
Transformer architectures are complex and their use in NLP, while it has engendered many successes, makes their interpretability or explainability challenging. Recent debates have shown that attention maps and attribution methods are unreliable (Pruthi et al., 2019; Brunner et al., 2019). In this paper, we present some of their limitations and introduce COCKATIEL, which successfully addresses some of them. COCKATIEL is a novel, post-hoc, concept-based, model-agnostic XAI technique that generates meaningful explanations from the last layer of a neural net model trained on an NLP classification task by using Non-Negative Matrix Factorization (NMF) to discover the concepts the model leverages to make predictions and by exploiting a Sensitivity Analysis to estimate accurately the importance of each of these concepts for the model. It does so without compromising the accuracy of the underlying model or requiring a new one to be trained. We conduct experiments in single and multi-aspect sentiment analysis tasks and we show COCKATIEL's superior ability to discover concepts that align with humans' on Transformer models without any supervision, we objectively verify the faithfulness of its explanations through fidelity metrics, and we showcase its ability to provide meaningful explanations in two different datasets.
How optimal transport can tackle gender biases in multi-class neural-network classifiers for job recommendations?
Feb 27, 2023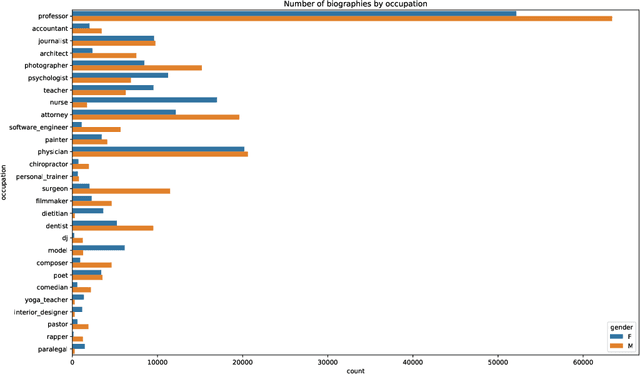
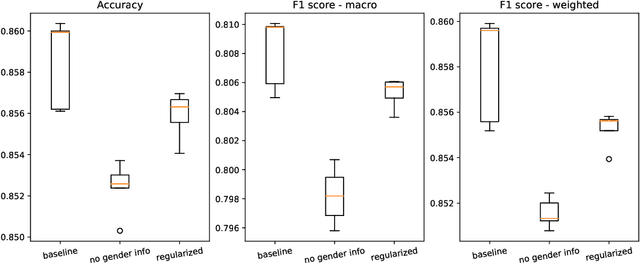
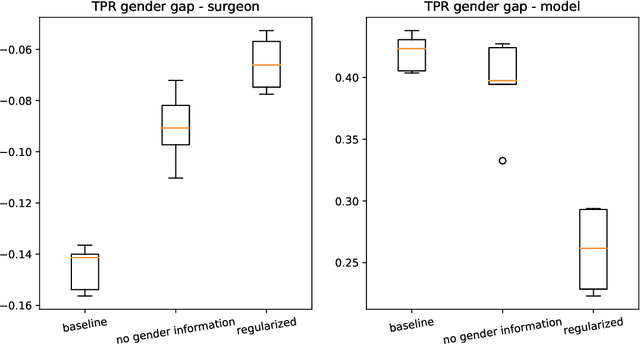
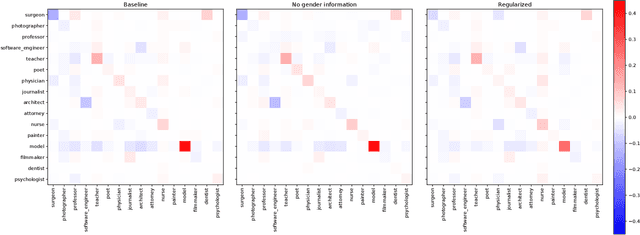
Automatic recommendation systems based on deep neural networks have become extremely popular during the last decade. Some of these systems can however be used for applications which are ranked as High Risk by the European Commission in the A.I. act, as for instance for online job candidate recommendation. When used in the European Union, commercial AI systems for this purpose will then be required to have to proper statistical properties with regard to potential discrimination they could engender. This motivated our contribution, where we present a novel optimal transport strategy to mitigate undesirable algorithmic biases in multi-class neural-network classification. Our stratey is model agnostic and can be used on any multi-class classification neural-network model. To anticipate the certification of recommendation systems using textual data, we then used it on the Bios dataset, for which the learning task consists in predicting the occupation of female and male individuals, based on their LinkedIn biography. Results show that it can reduce undesired algorithmic biases in this context to lower levels than a standard strategy.
p$^3$VAE: a physics-integrated generative model. Application to the semantic segmentation of optical remote sensing images
Oct 19, 2022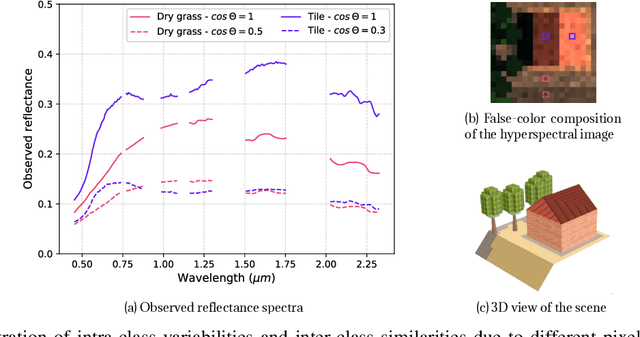
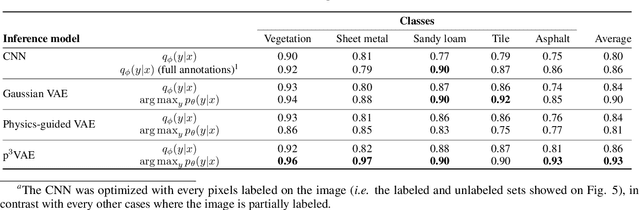
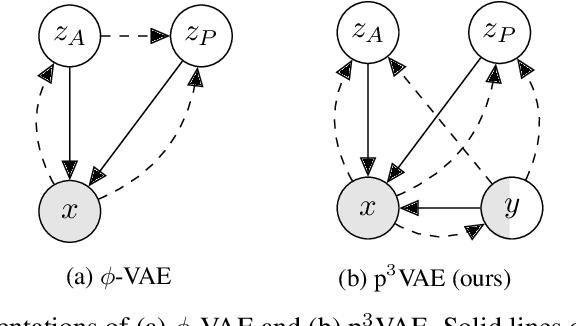
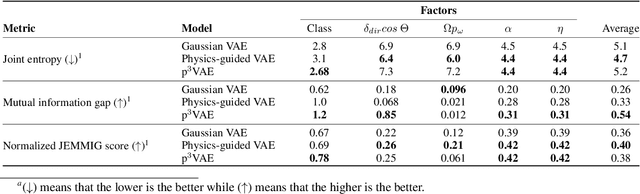
The combination of machine learning models with physical models is a recent research path to learn robust data representations. In this paper, we introduce p$^3$VAE, a generative model that integrates a perfect physical model which partially explains the true underlying factors of variation in the data. To fully leverage our hybrid design, we propose a semi-supervised optimization procedure and an inference scheme that comes along meaningful uncertainty estimates. We apply p$^3$VAE to the semantic segmentation of high-resolution hyperspectral remote sensing images. Our experiments on a simulated data set demonstrated the benefits of our hybrid model against conventional machine learning models in terms of extrapolation capabilities and interpretability. In particular, we show that p$^3$VAE naturally has high disentanglement capabilities. Our code and data have been made publicly available at https://github.com/Romain3Ch216/p3VAE.