 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntelligent Fault Diagnosis of Type and Severity in Low-Frequency, Low Bit-Depth Signals
Nov 24, 2024
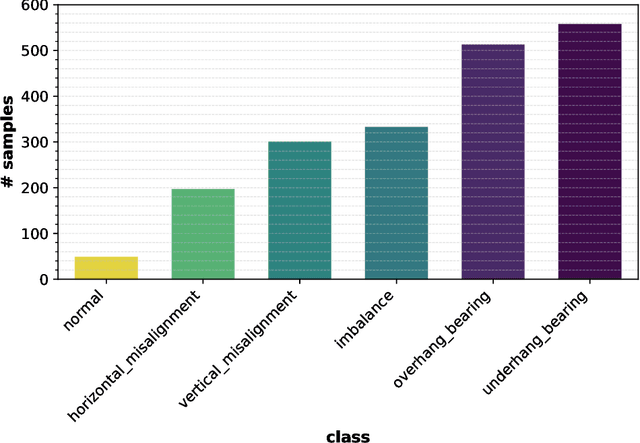
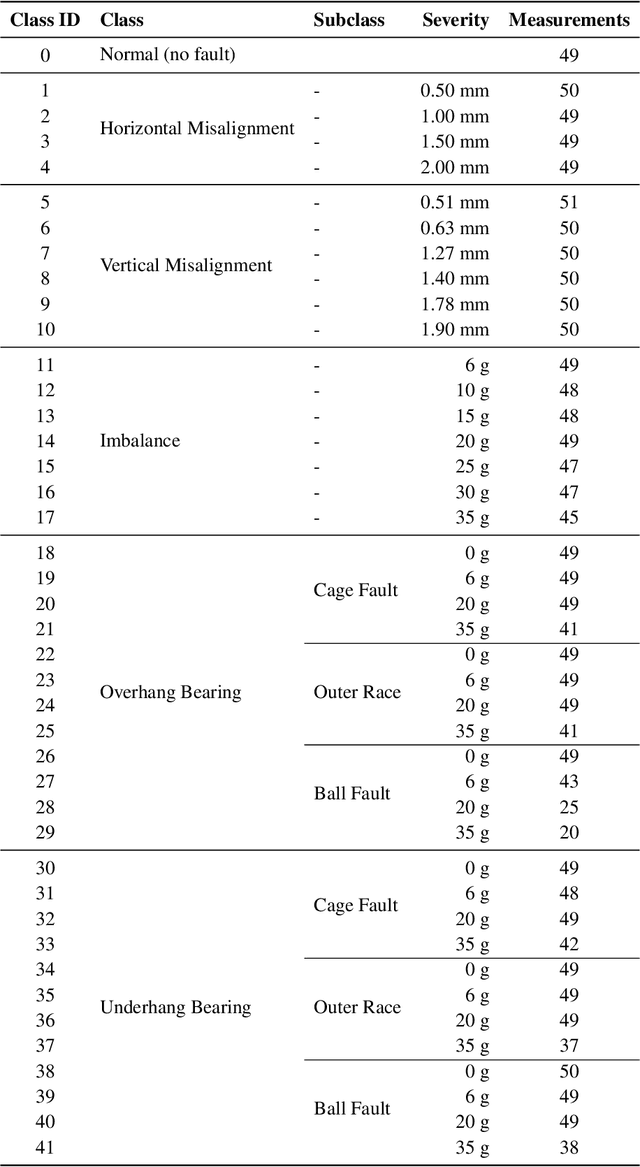
This study focuses on Intelligent Fault Diagnosis (IFD) in rotating machinery utilizing a single microphone and a data-driven methodology, effectively diagnosing 42 classes of fault types and severities. The research leverages sound data from the imbalanced MaFaulDa dataset, aiming to strike a balance between high performance and low resource consumption. The testing phase encompassed a variety of configurations, including sampling, quantization, signal normalization, silence removal, Wiener filtering, data scaling, windowing, augmentation, and classifier tuning using XGBoost. Through the analysis of time, frequency, mel-frequency, and statistical features, we achieved an impressive accuracy of 99.54% and an F-Beta score of 99.52% with just 6 boosting trees at an 8 kHz, 8-bit configuration. Moreover, when utilizing only MFCCs along with their first- and second-order deltas, we recorded an accuracy of 97.83% and an F-Beta score of 97.67%. Lastly, by implementing a greedy wrapper approach, we obtained a remarkable accuracy of 96.82% and an F-Beta score of 98.86% using 50 selected features, nearly all of which were first- and second-order deltas of the MFCCs.
Debiasing Machine Learning Models by Using Weakly Supervised Learning
Feb 23, 2024



We tackle the problem of bias mitigation of algorithmic decisions in a setting where both the output of the algorithm and the sensitive variable are continuous. Most of prior work deals with discrete sensitive variables, meaning that the biases are measured for subgroups of persons defined by a label, leaving out important algorithmic bias cases, where the sensitive variable is continuous. Typical examples are unfair decisions made with respect to the age or the financial status. In our work, we then propose a bias mitigation strategy for continuous sensitive variables, based on the notion of endogeneity which comes from the field of econometrics. In addition to solve this new problem, our bias mitigation strategy is a weakly supervised learning method which requires that a small portion of the data can be measured in a fair manner. It is model agnostic, in the sense that it does not make any hypothesis on the prediction model. It also makes use of a reasonably large amount of input observations and their corresponding predictions. Only a small fraction of the true output predictions should be known. This therefore limits the need for expert interventions. Results obtained on synthetic data show the effectiveness of our approach for examples as close as possible to real-life applications in econometrics.