 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntelligent Fault Diagnosis of Type and Severity in Low-Frequency, Low Bit-Depth Signals
Nov 24, 2024
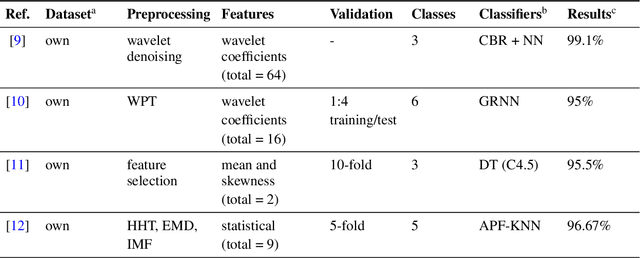
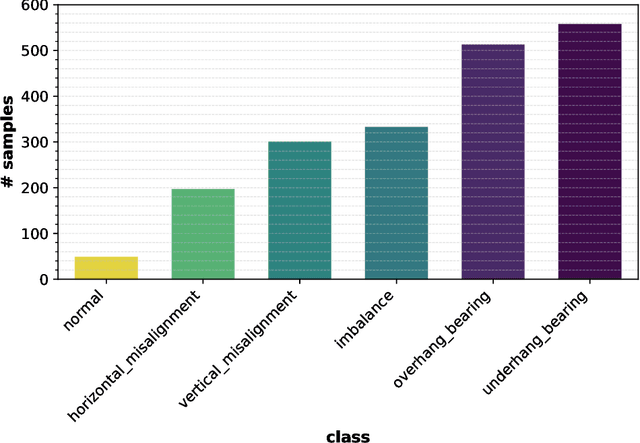
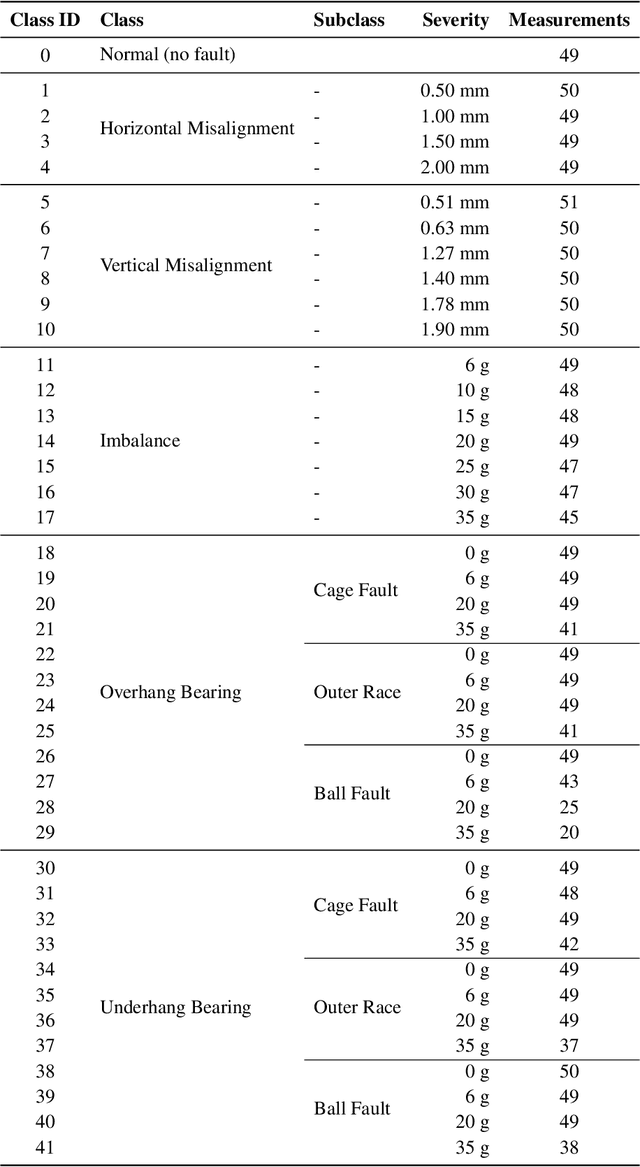
This study focuses on Intelligent Fault Diagnosis (IFD) in rotating machinery utilizing a single microphone and a data-driven methodology, effectively diagnosing 42 classes of fault types and severities. The research leverages sound data from the imbalanced MaFaulDa dataset, aiming to strike a balance between high performance and low resource consumption. The testing phase encompassed a variety of configurations, including sampling, quantization, signal normalization, silence removal, Wiener filtering, data scaling, windowing, augmentation, and classifier tuning using XGBoost. Through the analysis of time, frequency, mel-frequency, and statistical features, we achieved an impressive accuracy of 99.54% and an F-Beta score of 99.52% with just 6 boosting trees at an 8 kHz, 8-bit configuration. Moreover, when utilizing only MFCCs along with their first- and second-order deltas, we recorded an accuracy of 97.83% and an F-Beta score of 97.67%. Lastly, by implementing a greedy wrapper approach, we obtained a remarkable accuracy of 96.82% and an F-Beta score of 98.86% using 50 selected features, nearly all of which were first- and second-order deltas of the MFCCs.
Microphone Array Based Surveillance Audio Classification
May 22, 2020



The work assessed seven classical classifiers and two beamforming algorithms for detecting surveillance sound events. The tests included the use of AWGN with -10 dB to 30 dB SNR. Data Augmentation was also employed to improve algorithms' performance. The results showed that the combination of SVM and Delay-and-Sum (DaS) scored the best accuracy (up to 86.0\%), but had high computational cost ($\approx $ 402 ms), mainly due to DaS. The use of SGD also seems to be a good alternative since it has achieved good accuracy either (up to 85.3\%), but with quicker processing time ($\approx$ 165 ms).
Sound Event Recognition in a Smart City Surveillance Context
Oct 27, 2019


Due to the growing demand for improving surveillance capabilities in smart cities, systems need to be developed to provide better monitoring capabilities to competent authorities, agencies responsible for strategic resource management, and emergency call centers. This work assumes that, as a complementary monitoring solution, the use of a system capable of detecting the occurrence of sound events, performing the Sound Events Recognition (SER) task, is highly convenient. In order to contribute to the classification of such events, this paper explored several classifiers over the SESA dataset, composed of audios of three hazard classes (gunshots, explosions, and sirens) and a class of casual sounds that could be misinterpreted as some of the other sounds. The best result was obtained by SGD, with an accuracy of 72.13% with 6.81 ms classification time, reinforcing the viability of such an approach.
Comparative Study between Adversarial Networks and Classical Techniques for Speech Enhancement
Oct 21, 2019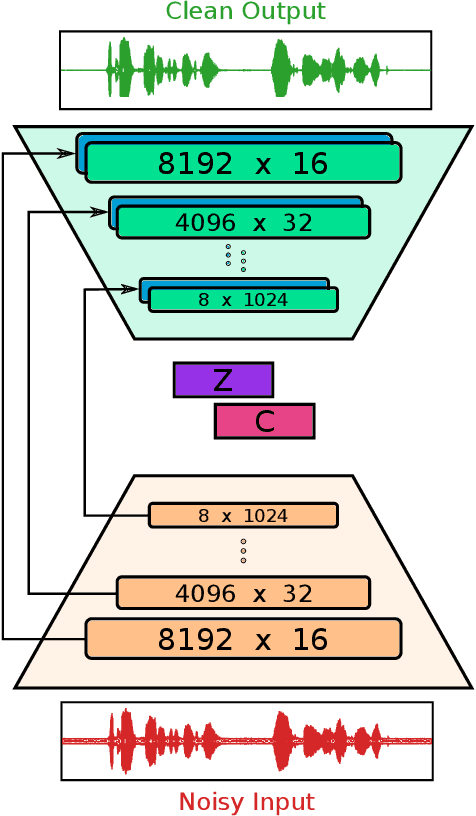
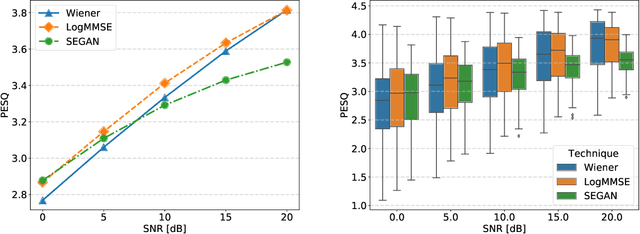
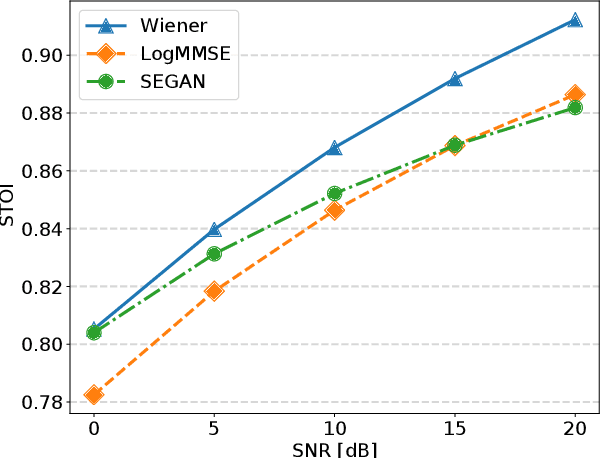
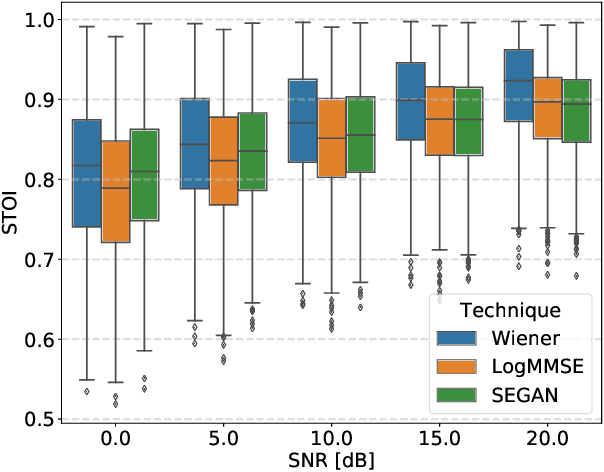
Speech enhancement is a crucial task for several applications. Among the most explored techniques are the Wiener filter and the LogMMSE, but approaches exploring deep learning adapted to this task, such as SEGAN, have presented relevant results. This study compared the performance of the mentioned techniques in 85 noise conditions regarding quality, intelligibility, and distortion; and concluded that classical techniques continue to exhibit superior results for most scenarios, but, in severe noise scenarios, SEGAN performed better and with lower variance.