 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA survey of bias in Machine Learning through the prism of Statistical Parity for the Adult Data Set
Apr 06, 2020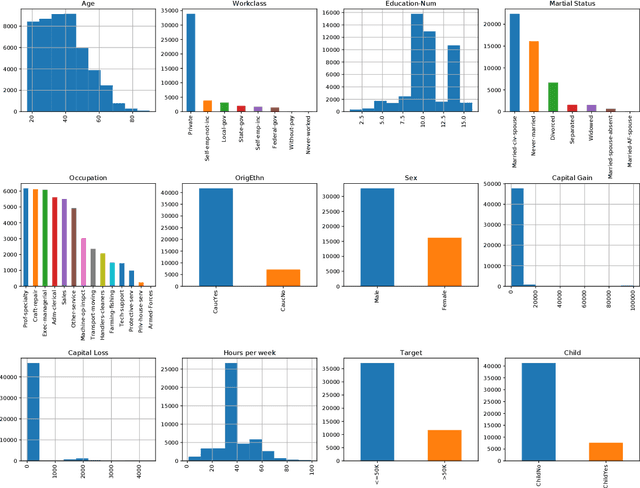

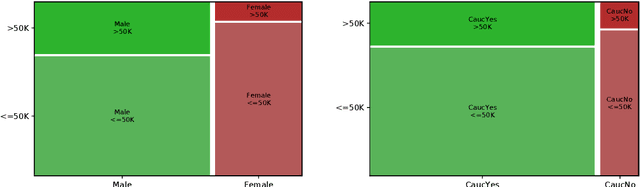
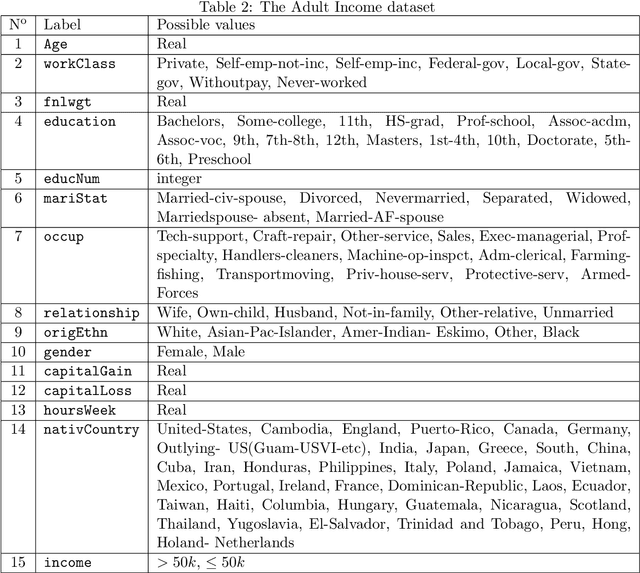
Applications based on Machine Learning models have now become an indispensable part of the everyday life and the professional world. A critical question then recently arised among the population: Do algorithmic decisions convey any type of discrimination against specific groups of population or minorities? In this paper, we show the importance of understanding how a bias can be introduced into automatic decisions. We first present a mathematical framework for the fair learning problem, specifically in the binary classification setting. We then propose to quantify the presence of bias by using the standard Disparate Impact index on the real and well-known Adult income data set. Finally, we check the performance of different approaches aiming to reduce the bias in binary classification outcomes. Importantly, we show that some intuitive methods are ineffective. This sheds light on the fact trying to make fair machine learning models may be a particularly challenging task, in particular when the training observations contain a bias.
Wikistat 2.0: Educational Resources for Artificial Intelligence
Oct 19, 2018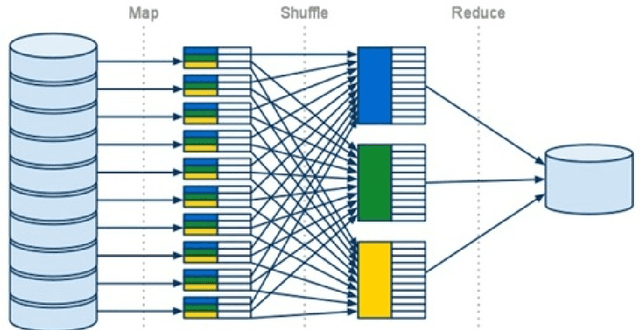
Big data, data science, deep learning, artificial intelligence are the key words of intense hype related with a job market in full evolution, that impose to adapt the contents of our university professional trainings. Which artificial intelligence is mostly concerned by the job offers? Which methodologies and technologies should be favored in the training programs? Which objectives, tools and educational resources do we needed to put in place to meet these pressing needs? We answer these questions in describing the contents and operational resources in the Data Science orientation of the specialty Applied Mathematics at INSA Toulouse. We focus on basic mathematics training (Optimization, Probability, Statistics), associated with the practical implementation of the most performing statistical learning algorithms, with the most appropriate technologies and on real examples. Considering the huge volatility of the technologies, it is imperative to train students in seft-training, this will be their technological watch tool when they will be in professional activity. This explains the structuring of the educational site github.com/wikistat into a set of tutorials. Finally, to motivate the thorough practice of these tutorials, a serious game is organized each year in the form of a prediction contest between students of Master degrees in Applied Mathematics for IA.
Can everyday AI be ethical. Fairness of Machine Learning Algorithms
Oct 03, 2018

Combining big data and machine learning algorithms, the power of automatic decision tools induces as much hope as fear. Many recently enacted European legislation (GDPR) and French laws attempt to regulate the use of these tools. Leaving aside the well-identified problems of data confidentiality and impediments to competition, we focus on the risks of discrimination, the problems of transparency and the quality of algorithmic decisions. The detailed perspective of the legal texts, faced with the complexity and opacity of the learning algorithms, reveals the need for important technological disruptions for the detection or reduction of the discrimination risk, and for addressing the right to obtain an explanation of the auto- matic decision. Since trust of the developers and above all of the users (citizens, litigants, customers) is essential, algorithms exploiting personal data must be deployed in a strict ethical framework. In conclusion, to answer this need, we list some ways of controls to be developed: institutional control, ethical charter, external audit attached to the issue of a label.
Confidence Intervals for Testing Disparate Impact in Fair Learning
Jul 17, 2018We provide the asymptotic distribution of the major indexes used in the statistical literature to quantify disparate treatment in machine learning. We aim at promoting the use of confidence intervals when testing the so-called group disparate impact. We illustrate on some examples the importance of using confidence intervals and not a single value.
Big Data analytics. Three use cases with R, Python and Spark
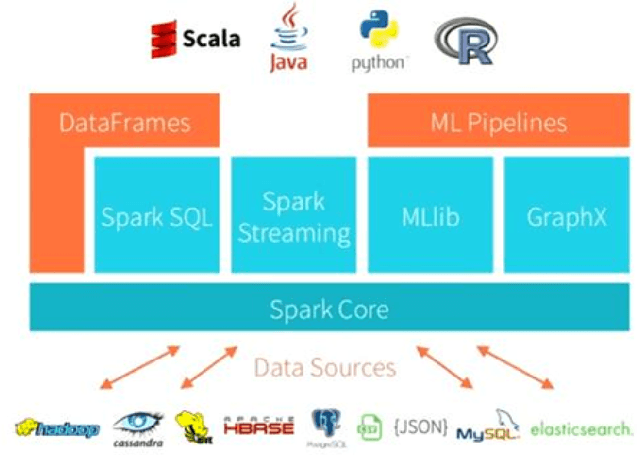
Sep 30, 2016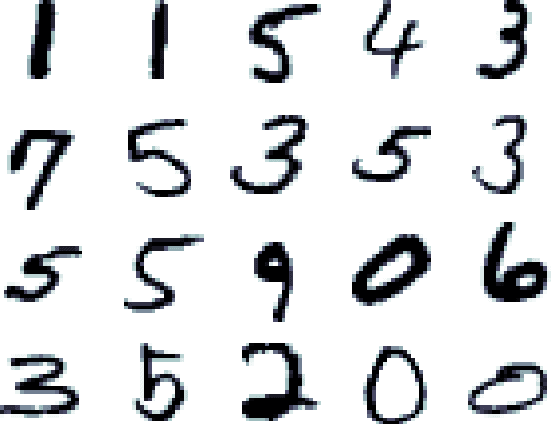
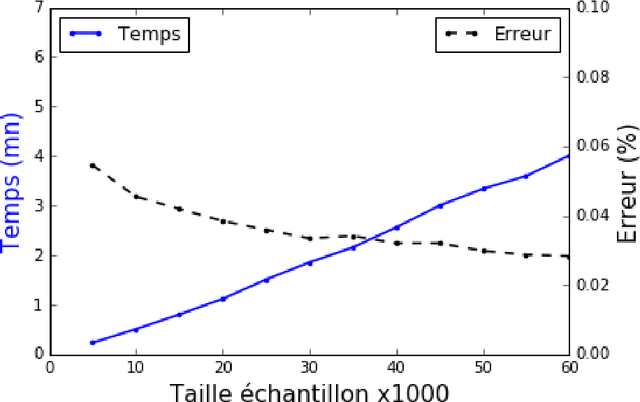
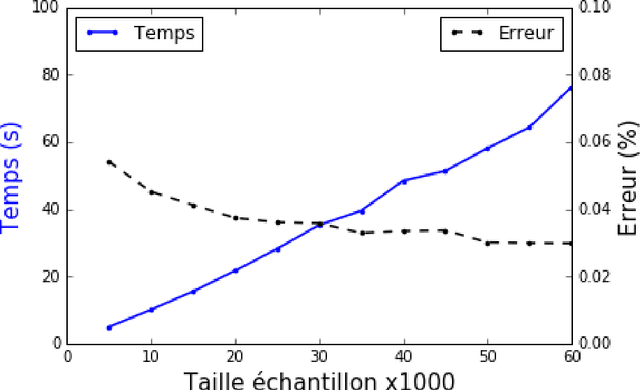
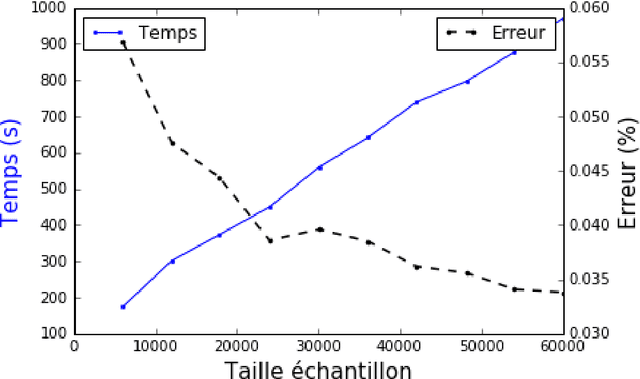
Management and analysis of big data are systematically associated with a data distributed architecture in the Hadoop and now Spark frameworks. This article offers an introduction for statisticians to these technologies by comparing the performance obtained by the direct use of three reference environments: R, Python Scikit-learn, Spark MLlib on three public use cases: character recognition, recommending films, categorizing products. As main result, it appears that, if Spark is very efficient for data munging and recommendation by collaborative filtering (non-negative factorization), current implementations of conventional learning methods (logistic regression, random forests) in MLlib or SparkML do not ou poorly compete habitual use of these methods (R, Python Scikit-learn) in an integrated or undistributed architecture
Review and Perspective for Distance Based Trajectory Clustering
Aug 20, 2015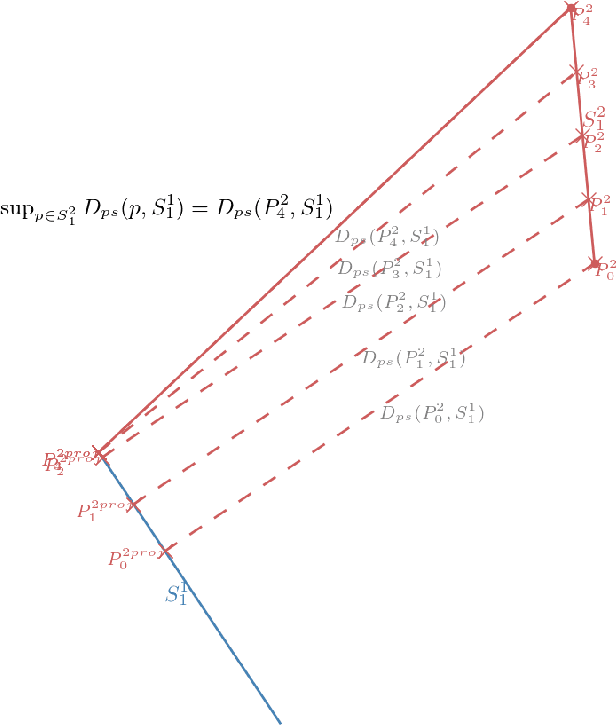
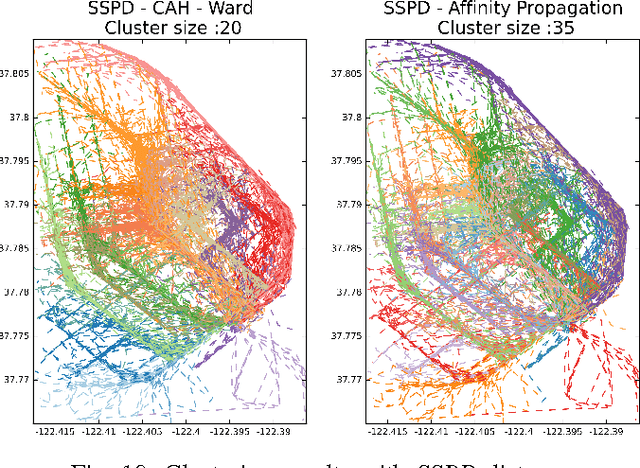

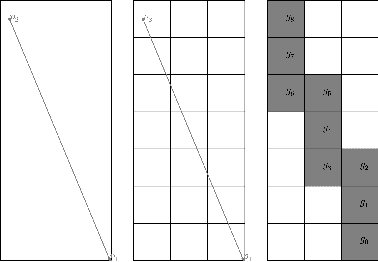
In this paper we tackle the issue of clustering trajectories of geolocalized observations. Using clustering technics based on the choice of a distance between the observations, we first provide a comprehensive review of the different distances used in the literature to compare trajectories. Then based on the limitations of these methods, we introduce a new distance : Symmetrized Segment-Path Distance (SSPD). We finally compare this new distance to the others according to their corresponding clustering results obtained using both hierarchical clustering and affinity propagation methods.
Statistique et Big Data Analytics; Volumétrie, L'Attaque des Clones
Oct 05, 2014
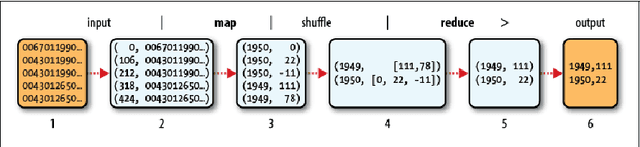
This article assumes acquired the skills and expertise of a statistician in unsupervised (NMF, k-means, SVD) and supervised learning (regression, CART, random forest). What skills and knowledge do a statistician must acquire to reach the "Volume" scale of big data? After a quick overview of the different strategies available and especially of those imposed by Hadoop, the algorithms of some available learning methods are outlined in order to understand how they are adapted to the strong stresses of the Map-Reduce functionalities