 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWikistat 2.0: Educational Resources for Artificial Intelligence
Oct 19, 2018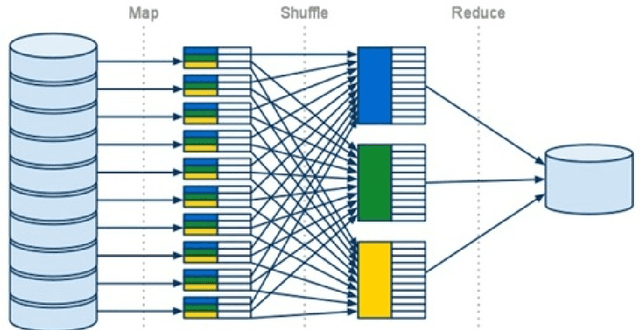
Big data, data science, deep learning, artificial intelligence are the key words of intense hype related with a job market in full evolution, that impose to adapt the contents of our university professional trainings. Which artificial intelligence is mostly concerned by the job offers? Which methodologies and technologies should be favored in the training programs? Which objectives, tools and educational resources do we needed to put in place to meet these pressing needs? We answer these questions in describing the contents and operational resources in the Data Science orientation of the specialty Applied Mathematics at INSA Toulouse. We focus on basic mathematics training (Optimization, Probability, Statistics), associated with the practical implementation of the most performing statistical learning algorithms, with the most appropriate technologies and on real examples. Considering the huge volatility of the technologies, it is imperative to train students in seft-training, this will be their technological watch tool when they will be in professional activity. This explains the structuring of the educational site github.com/wikistat into a set of tutorials. Finally, to motivate the thorough practice of these tutorials, a serious game is organized each year in the form of a prediction contest between students of Master degrees in Applied Mathematics for IA.
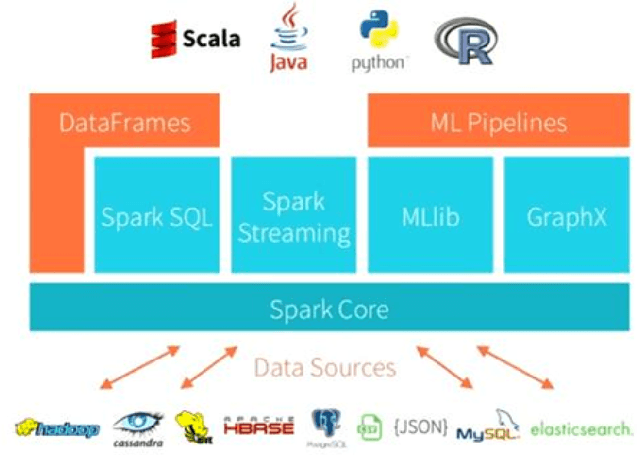
Big Data analytics. Three use cases with R, Python and Spark
Sep 30, 2016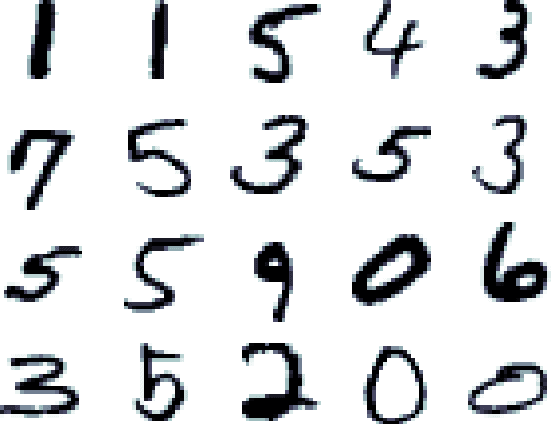
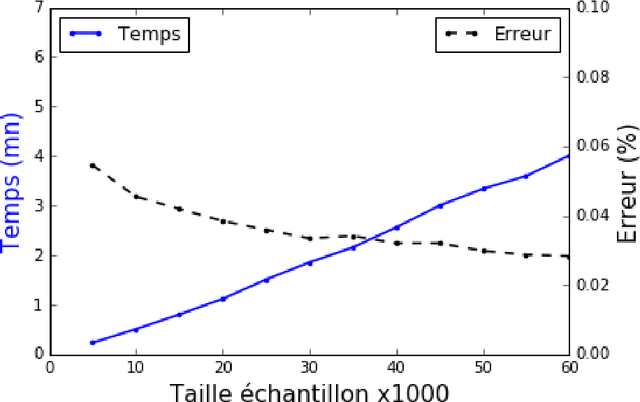
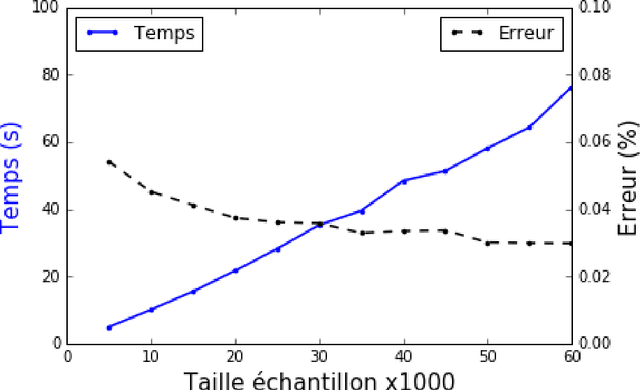
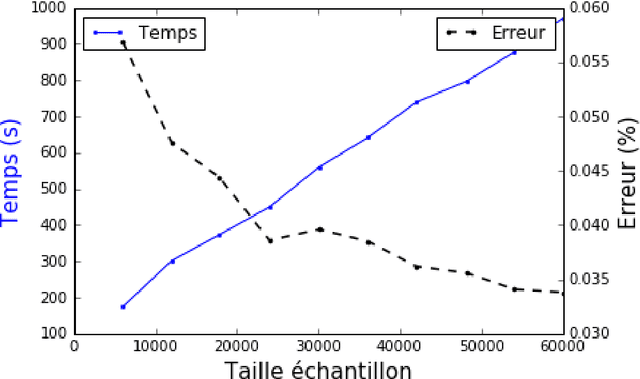
Management and analysis of big data are systematically associated with a data distributed architecture in the Hadoop and now Spark frameworks. This article offers an introduction for statisticians to these technologies by comparing the performance obtained by the direct use of three reference environments: R, Python Scikit-learn, Spark MLlib on three public use cases: character recognition, recommending films, categorizing products. As main result, it appears that, if Spark is very efficient for data munging and recommendation by collaborative filtering (non-negative factorization), current implementations of conventional learning methods (logistic regression, random forests) in MLlib or SparkML do not ou poorly compete habitual use of these methods (R, Python Scikit-learn) in an integrated or undistributed architecture
Destination Prediction by Trajectory Distribution Based Model
May 10, 2016
In this paper we propose a new method to predict the final destination of vehicle trips based on their initial partial trajectories. We first review how we obtained clustering of trajectories that describes user behaviour. Then, we explain how we model main traffic flow patterns by a mixture of 2d Gaussian distributions. This yielded a density based clustering of locations, which produces a data driven grid of similar points within each pattern. We present how this model can be used to predict the final destination of a new trajectory based on their first locations using a two step procedure: We first assign the new trajectory to the clusters it mot likely belongs. Secondly, we use characteristics from trajectories inside these clusters to predict the final destination. Finally, we present experimental results of our methods for classification of trajectories and final destination prediction on datasets of timestamped GPS-Location of taxi trips. We test our methods on two different datasets, to assess the capacity of our method to adapt automatically to different subsets.
Review and Perspective for Distance Based Trajectory Clustering
Aug 20, 2015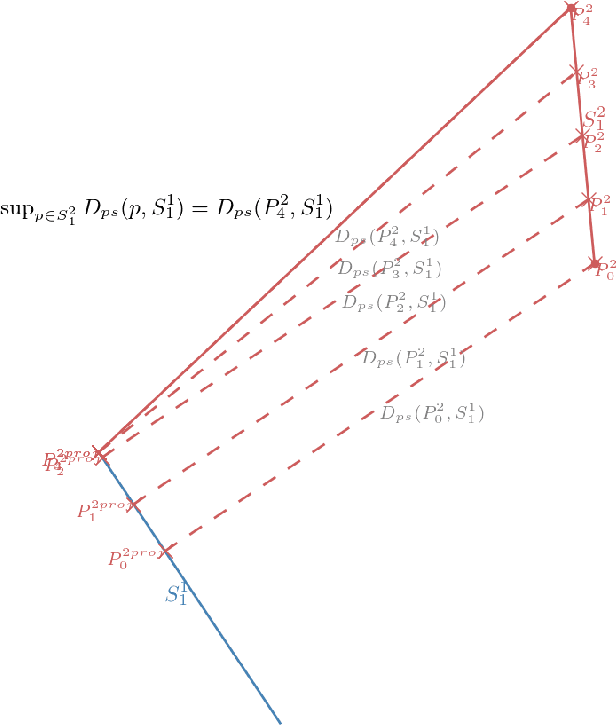
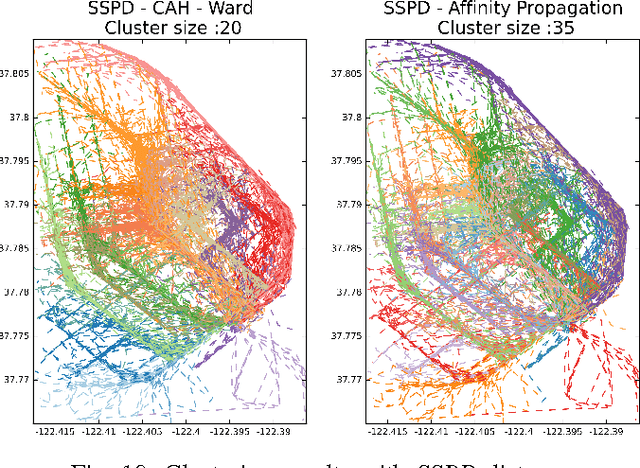

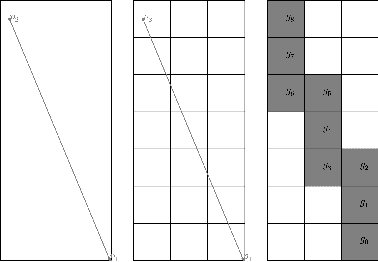
In this paper we tackle the issue of clustering trajectories of geolocalized observations. Using clustering technics based on the choice of a distance between the observations, we first provide a comprehensive review of the different distances used in the literature to compare trajectories. Then based on the limitations of these methods, we introduce a new distance : Symmetrized Segment-Path Distance (SSPD). We finally compare this new distance to the others according to their corresponding clustering results obtained using both hierarchical clustering and affinity propagation methods.