 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBig Data analytics. Three use cases with R, Python and Spark
Paper and Code
Sep 30, 2016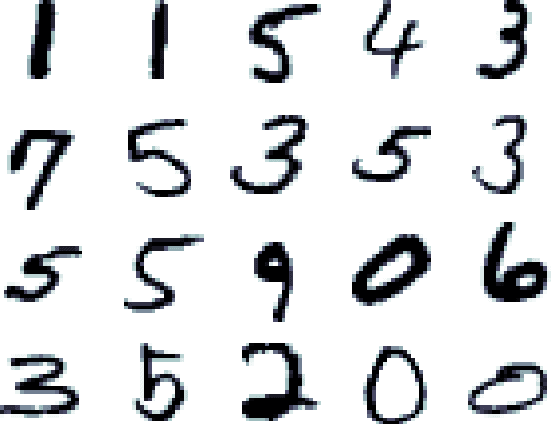
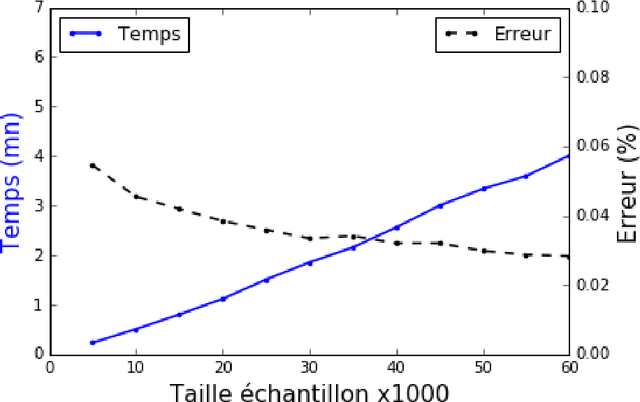
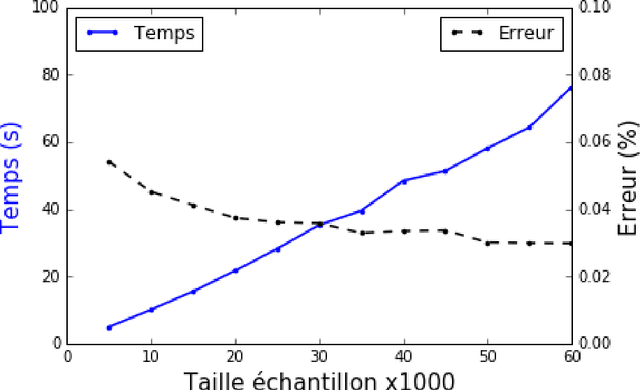
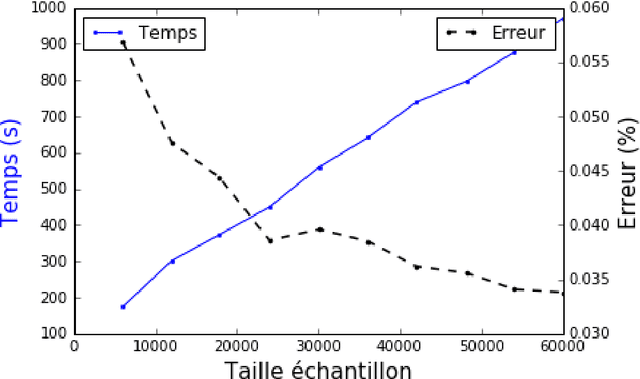
Management and analysis of big data are systematically associated with a data distributed architecture in the Hadoop and now Spark frameworks. This article offers an introduction for statisticians to these technologies by comparing the performance obtained by the direct use of three reference environments: R, Python Scikit-learn, Spark MLlib on three public use cases: character recognition, recommending films, categorizing products. As main result, it appears that, if Spark is very efficient for data munging and recommendation by collaborative filtering (non-negative factorization), current implementations of conventional learning methods (logistic regression, random forests) in MLlib or SparkML do not ou poorly compete habitual use of these methods (R, Python Scikit-learn) in an integrated or undistributed architecture