 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA survey of bias in Machine Learning through the prism of Statistical Parity for the Adult Data Set
Paper and Code
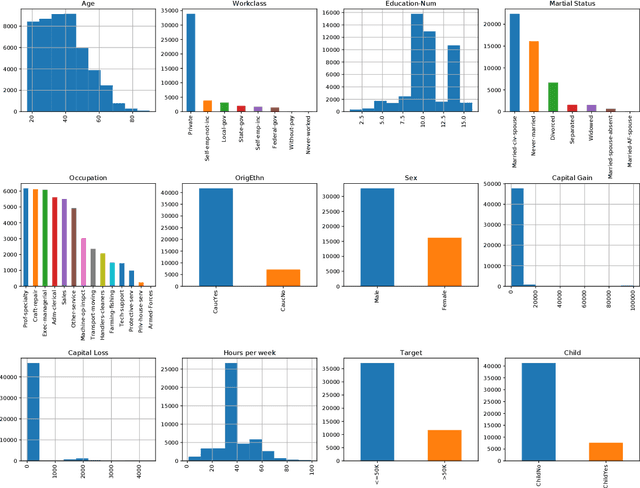

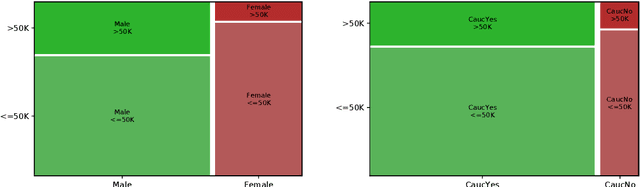
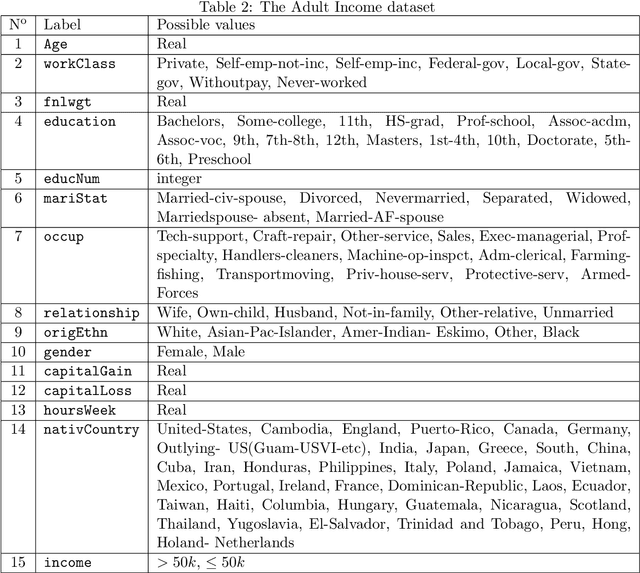
Applications based on Machine Learning models have now become an indispensable part of the everyday life and the professional world. A critical question then recently arised among the population: Do algorithmic decisions convey any type of discrimination against specific groups of population or minorities? In this paper, we show the importance of understanding how a bias can be introduced into automatic decisions. We first present a mathematical framework for the fair learning problem, specifically in the binary classification setting. We then propose to quantify the presence of bias by using the standard Disparate Impact index on the real and well-known Adult income data set. Finally, we check the performance of different approaches aiming to reduce the bias in binary classification outcomes. Importantly, we show that some intuitive methods are ineffective. This sheds light on the fact trying to make fair machine learning models may be a particularly challenging task, in particular when the training observations contain a bias.