Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStatistique et Big Data Analytics; Volumétrie, L'Attaque des Clones
Paper and Code

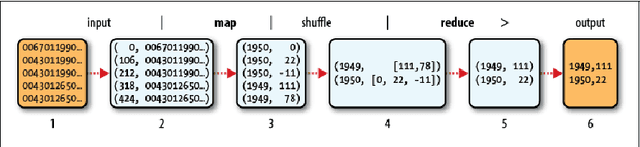
This article assumes acquired the skills and expertise of a statistician in unsupervised (NMF, k-means, SVD) and supervised learning (regression, CART, random forest). What skills and knowledge do a statistician must acquire to reach the "Volume" scale of big data? After a quick overview of the different strategies available and especially of those imposed by Hadoop, the algorithms of some available learning methods are outlined in order to understand how they are adapted to the strong stresses of the Map-Reduce functionalities
* in French
View paper on