 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTaCo: Targeted Concept Removal in Output Embeddings for NLP via Information Theory and Explainability
Paper and Code

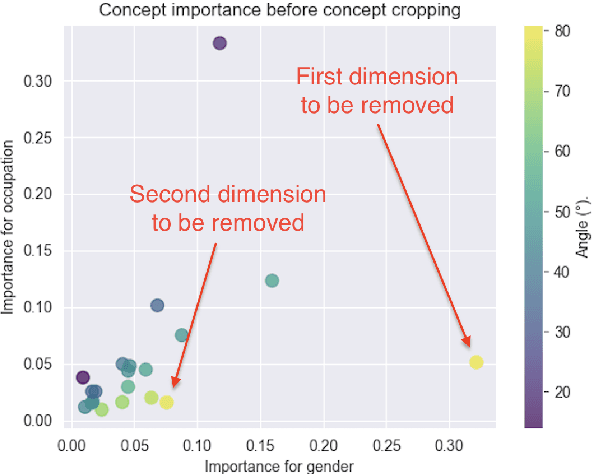
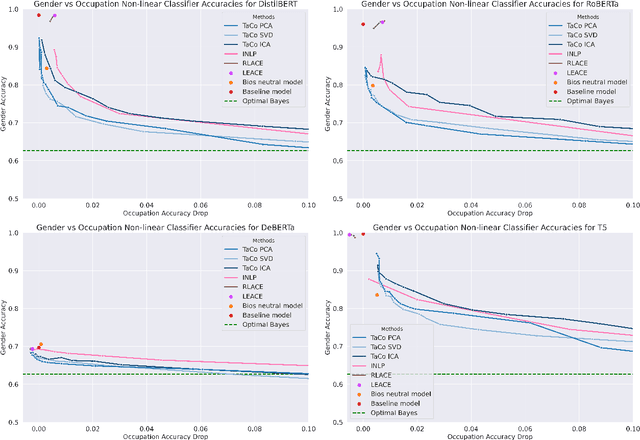
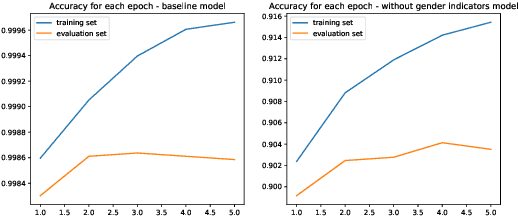
The fairness of Natural Language Processing (NLP) models has emerged as a crucial concern. Information theory indicates that to achieve fairness, a model should not be able to predict sensitive variables, such as gender, ethnicity, and age. However, information related to these variables often appears implicitly in language, posing a challenge in identifying and mitigating biases effectively. To tackle this issue, we present a novel approach that operates at the embedding level of an NLP model, independent of the specific architecture. Our method leverages insights from recent advances in XAI techniques and employs an embedding transformation to eliminate implicit information from a selected variable. By directly manipulating the embeddings in the final layer, our approach enables a seamless integration into existing models without requiring significant modifications or retraining. In evaluation, we show that the proposed post-hoc approach significantly reduces gender-related associations in NLP models while preserving the overall performance and functionality of the models. An implementation of our method is available: https://github.com/fanny-jourdan/TaCo