 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToulouse Hyperspectral Data Set: a benchmark data set to assess semi-supervised spectral representation learning and pixel-wise classification techniques
Nov 15, 2023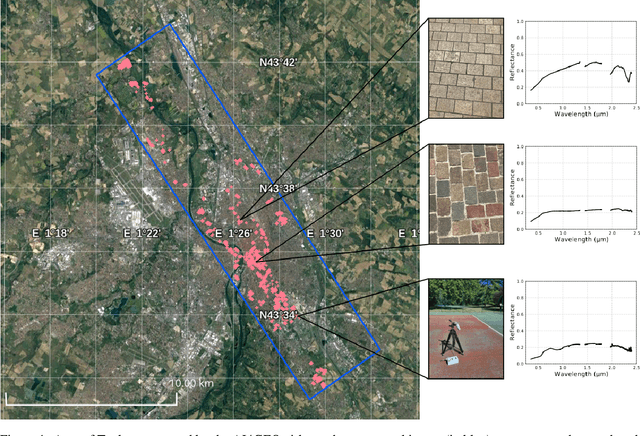



Airborne hyperspectral images can be used to map the land cover in large urban areas, thanks to their very high spatial and spectral resolutions on a wide spectral domain. While the spectral dimension of hyperspectral images is highly informative of the chemical composition of the land surface, the use of state-of-the-art machine learning algorithms to map the land cover has been dramatically limited by the availability of training data. To cope with the scarcity of annotations, semi-supervised and self-supervised techniques have lately raised a lot of interest in the community. Yet, the publicly available hyperspectral data sets commonly used to benchmark machine learning models are not totally suited to evaluate their generalization performances due to one or several of the following properties: a limited geographical coverage (which does not reflect the spectral diversity in metropolitan areas), a small number of land cover classes and a lack of appropriate standard train / test splits for semi-supervised and self-supervised learning. Therefore, we release in this paper the Toulouse Hyperspectral Data Set that stands out from other data sets in the above-mentioned respects in order to meet key issues in spectral representation learning and classification over large-scale hyperspectral images with very few labeled pixels. Besides, we discuss and experiment the self-supervised task of Masked Autoencoders and establish a baseline for pixel-wise classification based on a conventional autoencoder combined with a Random Forest classifier achieving 82% overall accuracy and 74% F1 score. The Toulouse Hyperspectral Data Set and our code are publicly available at https://www.toulouse-hyperspectral-data-set.com and https://www.github.com/Romain3Ch216/tlse-experiments, respectively.
p$^3$VAE: a physics-integrated generative model. Application to the semantic segmentation of optical remote sensing images
Oct 19, 2022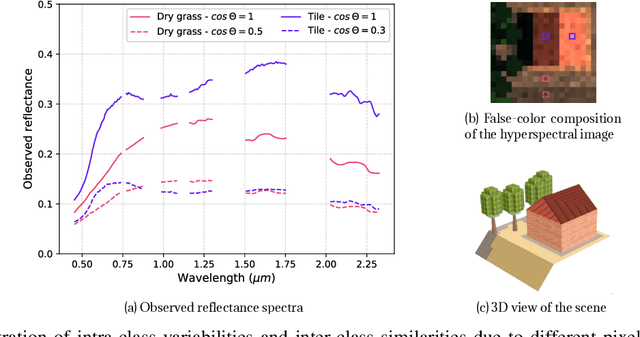
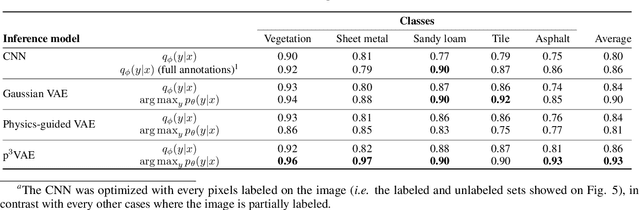
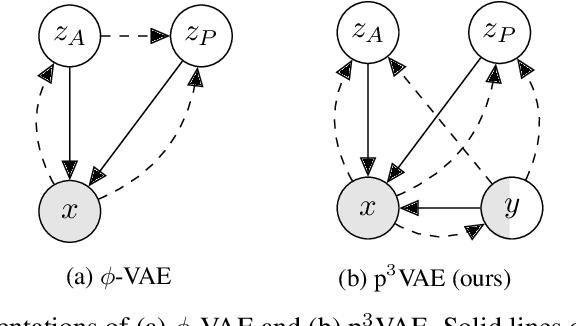
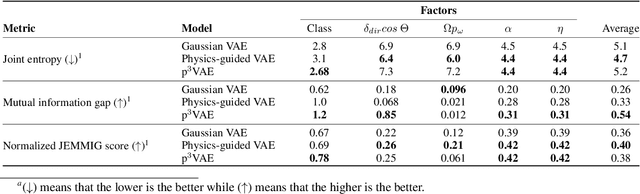
The combination of machine learning models with physical models is a recent research path to learn robust data representations. In this paper, we introduce p$^3$VAE, a generative model that integrates a perfect physical model which partially explains the true underlying factors of variation in the data. To fully leverage our hybrid design, we propose a semi-supervised optimization procedure and an inference scheme that comes along meaningful uncertainty estimates. We apply p$^3$VAE to the semantic segmentation of high-resolution hyperspectral remote sensing images. Our experiments on a simulated data set demonstrated the benefits of our hybrid model against conventional machine learning models in terms of extrapolation capabilities and interpretability. In particular, we show that p$^3$VAE naturally has high disentanglement capabilities. Our code and data have been made publicly available at https://github.com/Romain3Ch216/p3VAE.
Inertia-Constrained Pixel-by-Pixel Nonnegative Matrix Factorisation: a Hyperspectral Unmixing Method Dealing with Intra-class Variability
Feb 24, 2017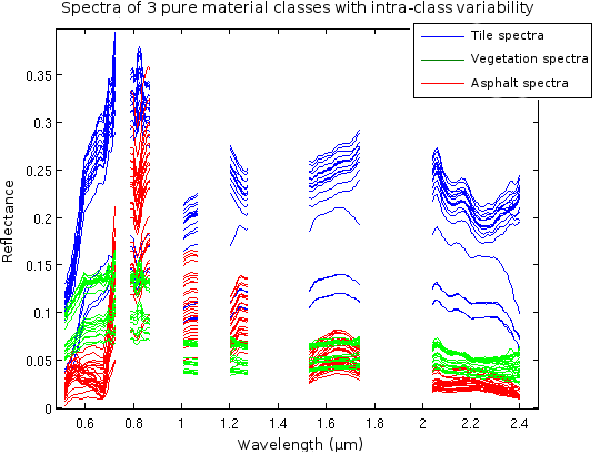

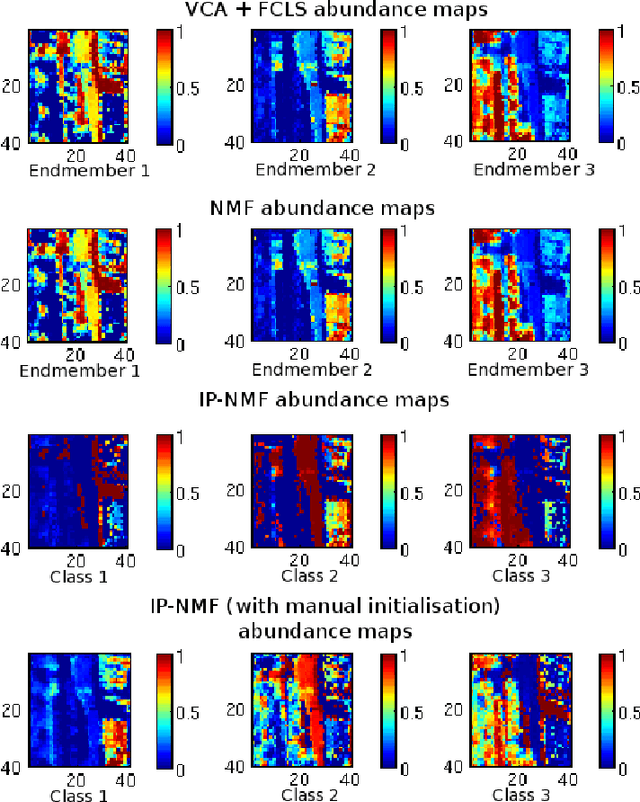
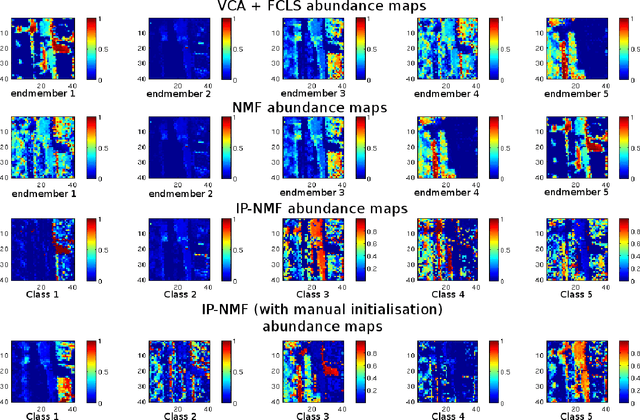
Blind source separation is a common processing tool to analyse the constitution of pixels of hyperspectral images. Such methods usually suppose that pure pixel spectra (endmembers) are the same in all the image for each class of materials. In the framework of remote sensing, such an assumption is no more valid in the presence of intra-class variabilities due to illumination conditions, weathering, slight variations of the pure materials, etc... In this paper, we first describe the results of investigations highlighting intra-class variability measured in real images. Considering these results, a new formulation of the linear mixing model is presented leading to two new methods. Unconstrained Pixel-by-pixel NMF (UP-NMF) is a new blind source separation method based on the assumption of a linear mixing model, which can deal with intra-class variability. To overcome UP-NMF limitations an extended method is proposed, named Inertia-constrained Pixel-by-pixel NMF (IP-NMF). For each sensed spectrum, these extended versions of NMF extract a corresponding set of source spectra. A constraint is set to limit the spreading of each source's estimates in IP-NMF. The methods are tested on a semi-synthetic data set built with spectra extracted from a real hyperspectral image and then numerically mixed. We thus demonstrate the interest of our methods for realistic source variabilities. Finally, IP-NMF is tested on a real data set and it is shown to yield better performance than state of the art methods.