 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Modular Spatial Clustering Algorithm with Noise Specification
Sep 18, 2023
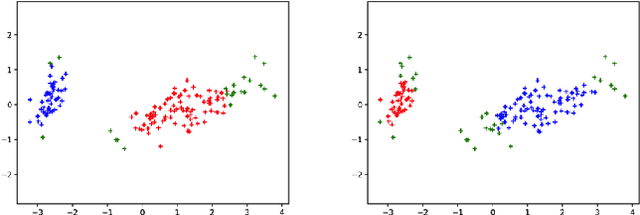
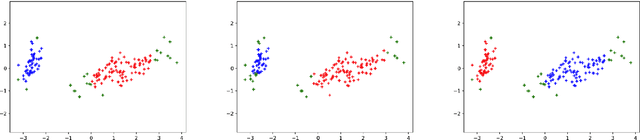
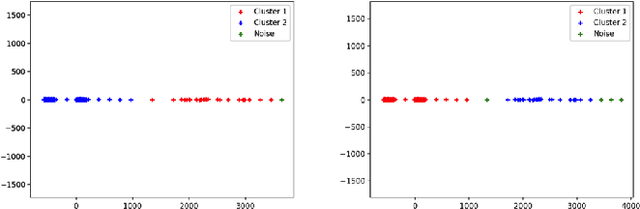
Clustering techniques have been the key drivers of data mining, machine learning and pattern recognition for decades. One of the most popular clustering algorithms is DBSCAN due to its high accuracy and noise tolerance. Many superior algorithms such as DBSCAN have input parameters that are hard to estimate. Therefore, finding those parameters is a time consuming process. In this paper, we propose a novel clustering algorithm Bacteria-Farm, which balances the performance and ease of finding the optimal parameters for clustering. Bacteria- Farm algorithm is inspired by the growth of bacteria in closed experimental farms - their ability to consume food and grow - which closely represents the ideal cluster growth desired in clustering algorithms. In addition, the algorithm features a modular design to allow the creation of versions of the algorithm for specific tasks / distributions of data. In contrast with other clustering algorithms, our algorithm also has a provision to specify the amount of noise to be excluded during clustering.
Cross-domain Variational Capsules for Information Extraction
Oct 13, 2022In this paper, we present a characteristic extraction algorithm and the Multi-domain Image Characteristics Dataset of characteristic-tagged images to simulate the way a human brain classifies cross-domain information and generates insight. The intent was to identify prominent characteristics in data and use this identification mechanism to auto-generate insight from data in other unseen domains. An information extraction algorithm is proposed which is a combination of Variational Autoencoders (VAEs) and Capsule Networks. Capsule Networks are used to decompose images into their individual features and VAEs are used to explore variations on these decomposed features. Thus, making the model robust in recognizing characteristics from variations of the data. A noteworthy point is that the algorithm uses efficient hierarchical decoding of data which helps in richer output interpretation. Noticing a dearth in the number of datasets that contain visible characteristics in images belonging to various domains, the Multi-domain Image Characteristics Dataset was created and made publicly available. It consists of thousands of images across three domains. This dataset was created with the intent of introducing a new benchmark for fine-grained characteristic recognition tasks in the future.
* This paper was originally written in 2020