 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeight Sparsity Complements Activity Sparsity in Neuromorphic Language Models
Paper and Code
May 01, 2024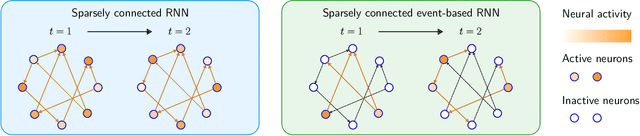
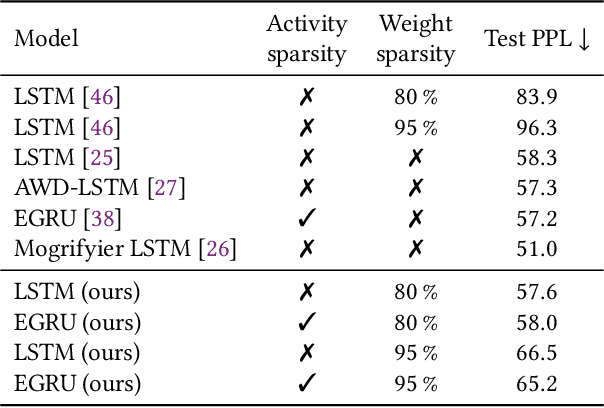
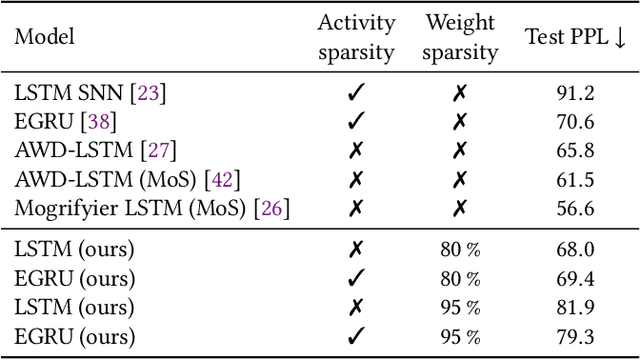
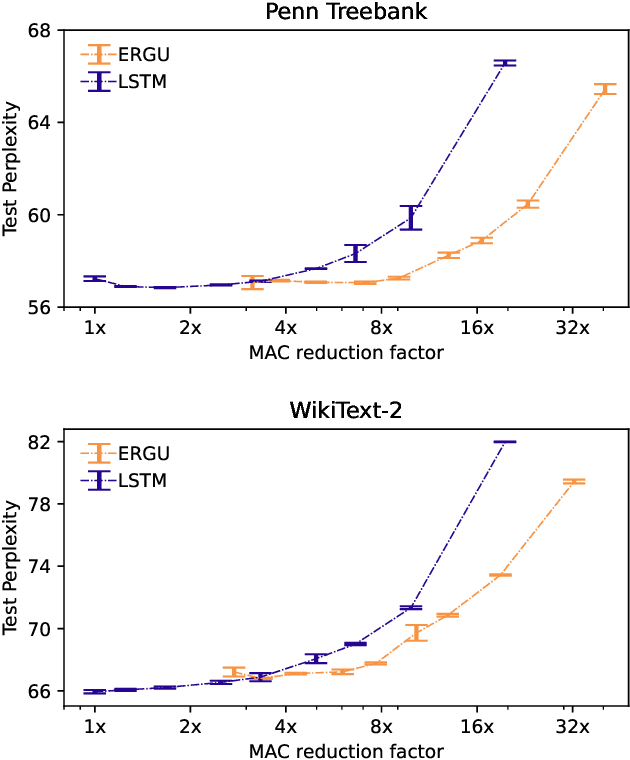
Activity and parameter sparsity are two standard methods of making neural networks computationally more efficient. Event-based architectures such as spiking neural networks (SNNs) naturally exhibit activity sparsity, and many methods exist to sparsify their connectivity by pruning weights. While the effect of weight pruning on feed-forward SNNs has been previously studied for computer vision tasks, the effects of pruning for complex sequence tasks like language modeling are less well studied since SNNs have traditionally struggled to achieve meaningful performance on these tasks. Using a recently published SNN-like architecture that works well on small-scale language modeling, we study the effects of weight pruning when combined with activity sparsity. Specifically, we study the trade-off between the multiplicative efficiency gains the combination affords and its effect on task performance for language modeling. To dissect the effects of the two sparsities, we conduct a comparative analysis between densely activated models and sparsely activated event-based models across varying degrees of connectivity sparsity. We demonstrate that sparse activity and sparse connectivity complement each other without a proportional drop in task performance for an event-based neural network trained on the Penn Treebank and WikiText-2 language modeling datasets. Our results suggest sparsely connected event-based neural networks are promising candidates for effective and efficient sequence modeling.