 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn In-Depth Study of Filter-Agnostic Vector Search on a PostgreSQL Database System: [Experiments and Analysis]
Mar 24, 2026Filtered Vector Search (FVS) is critical for supporting semantic search and GenAI applications in modern database systems. However, existing research most often evaluates algorithms in specialized libraries, making optimistic assumptions that do not align with enterprise-grade database systems. Our work challenges this premise by demonstrating that in a production-grade database system, commonly made assumptions do not hold, leading to performance characteristics and algorithmic trade-offs that are fundamentally different from those observed in isolated library settings. This paper presents the first in-depth analysis of filter-agnostic FVS algorithms within a production PostgreSQL-compatible system. We systematically evaluate post-filtering and inline-filtering strategies across a wide range of selectivities and correlations. Our central finding is that the optimal algorithm is not dictated by the cost of distance computations alone, but that system-level overheads that come from both distance computations and filter operations (like page accesses and data retrieval) play a significant role. We demonstrate that graph-based approaches (such as NaviX/ACORN) can incur prohibitive numbers of filter checks and system-level overheads, compared with clustering-based indexes such as ScaNN, often canceling out their theoretical benefits in real-world database environments. Ultimately, our findings provide the database community with crucial insights and practical guidelines, demonstrating that the optimal choice for a filter-agnostic FVS algorithm is not absolute, but rather a system-aware decision contingent on the interplay between workload characteristics and the underlying costs of data access in a real-world database architecture.
Neuromorphic hardware for sustainable AI data centers
Feb 04, 2024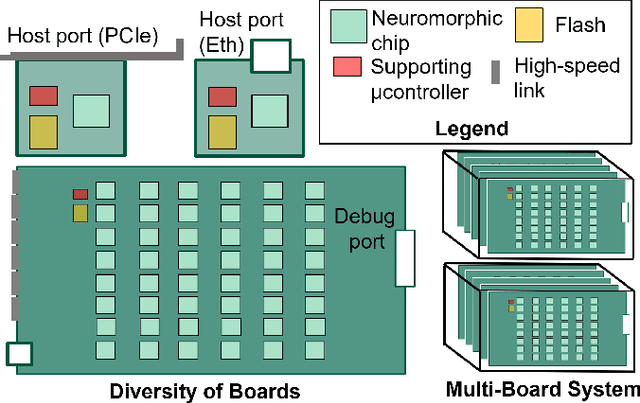
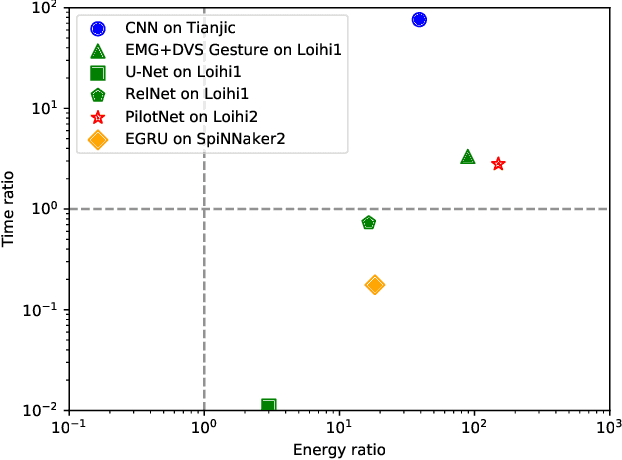
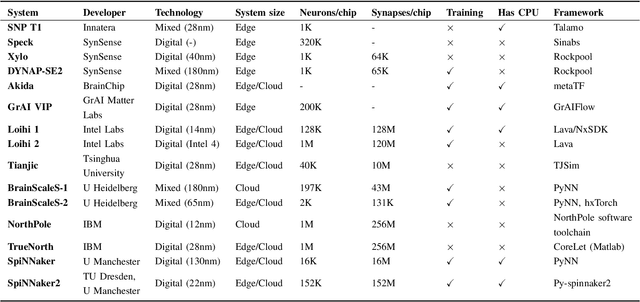

As humans advance toward a higher level of artificial intelligence, it is always at the cost of escalating computational resource consumption, which requires developing novel solutions to meet the exponential growth of AI computing demand. Neuromorphic hardware takes inspiration from how the brain processes information and promises energy-efficient computing of AI workloads. Despite its potential, neuromorphic hardware has not found its way into commercial AI data centers. In this article, we try to analyze the underlying reasons for this and derive requirements and guidelines to promote neuromorphic systems for efficient and sustainable cloud computing: We first review currently available neuromorphic hardware systems and collect examples where neuromorphic solutions excel conventional AI processing on CPUs and GPUs. Next, we identify applications, models and algorithms which are commonly deployed in AI data centers as further directions for neuromorphic algorithms research. Last, we derive requirements and best practices for the hardware and software integration of neuromorphic systems into data centers. With this article, we hope to increase awareness of the challenges of integrating neuromorphic hardware into data centers and to guide the community to enable sustainable and energy-efficient AI at scale.
GloVeInit at SemEval-2020 Task 1: Using GloVe Vector Initialization for Unsupervised Lexical Semantic Change Detection
Jul 10, 2020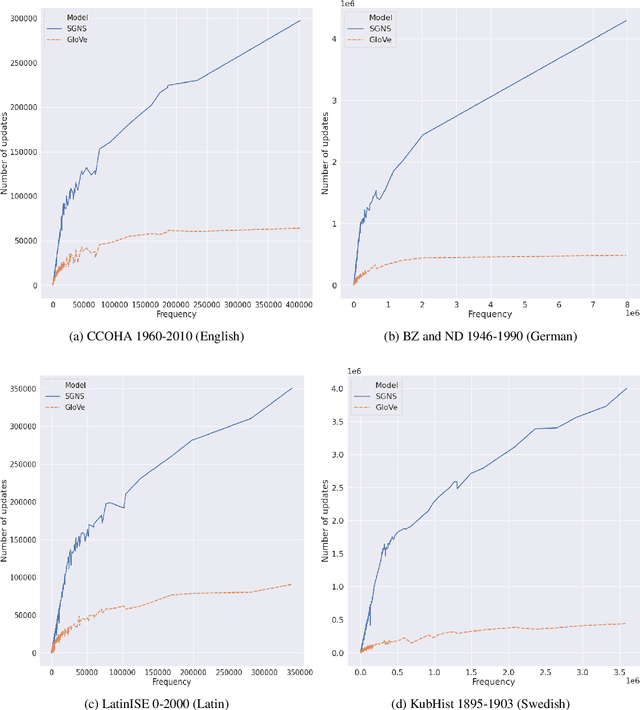
This paper presents a vector initialization approach for the SemEval2020 Task 1: Unsupervised Lexical Semantic Change Detection. Given two corpora belonging to different time periods and a set of target words, this task requires us to classify whether a word gained or lost a sense over time (subtask 1) and to rank them on the basis of the changes in their word senses (subtask 2). The proposed approach is based on using Vector Initialization method to align GloVe embeddings. The idea is to consecutively train GloVe embeddings for both corpora, while using the first model to initialize the second one. This paper is based on the hypothesis that GloVe embeddings are more suited for the Vector Initialization method than SGNS embeddings. It presents an intuitive reasoning behind this hypothesis, and also talks about the impact of various factors and hyperparameters on the performance of the proposed approach. Our model ranks 13th and 10th among 33 teams in the two subtasks. The implementation has been shared publicly.
Cross-Domain Ambiguity Detection using Linear Transformation of Word Embedding Spaces
Oct 28, 2019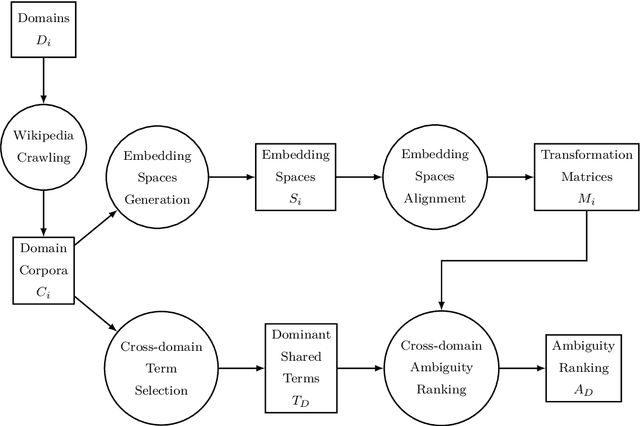
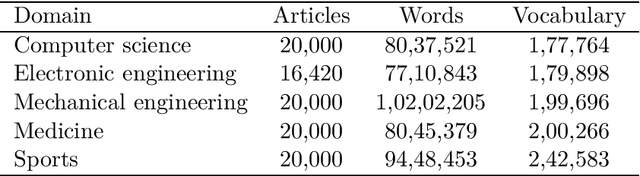

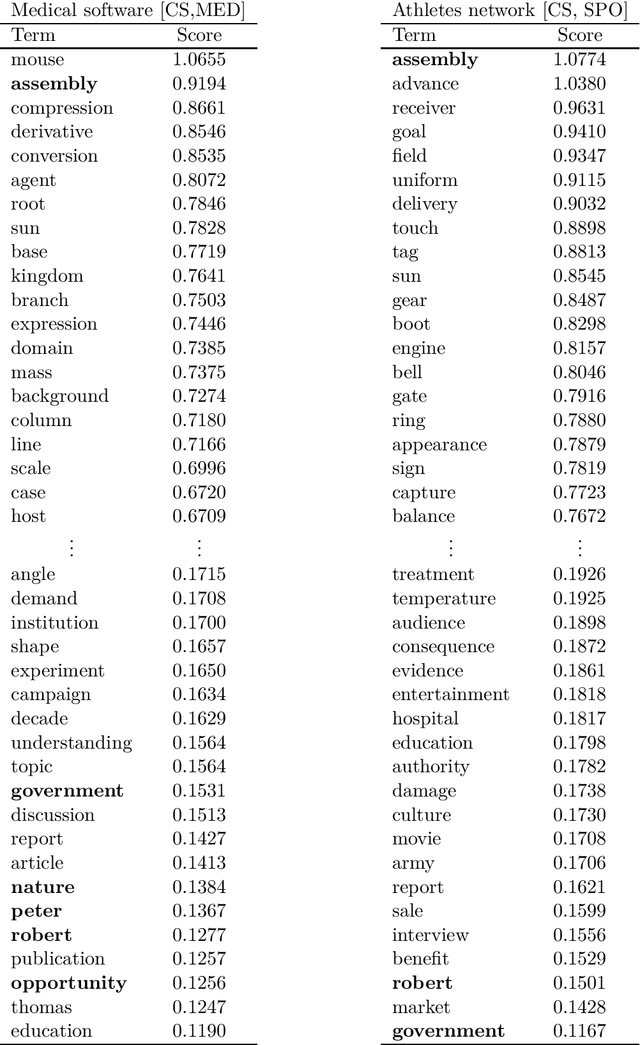
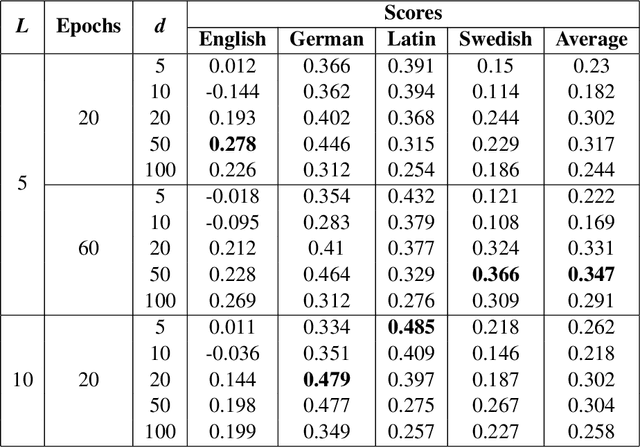
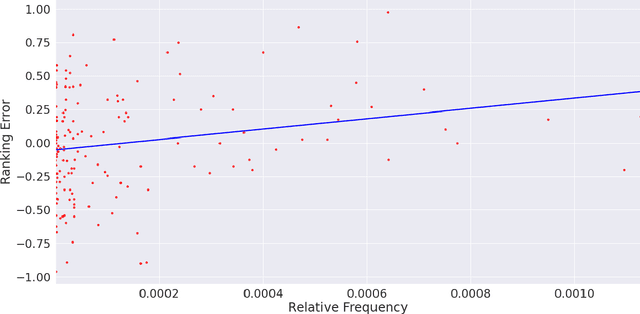
The requirements engineering process is a crucial stage of the software development life cycle. It involves various stakeholders from different professional backgrounds, particularly in the requirements elicitation phase. Each stakeholder carries distinct domain knowledge, causing them to differently interpret certain words, leading to cross-domain ambiguity. This can result in misunderstanding amongst them and jeopardize the entire project. We propose a computationally cheap natural language processing approach to find potentially ambiguous words for a given set of domains. The idea is to apply linear transformations on word embedding models trained on different domain corpora, to bring them into a unified embedding space. We then find words with divergent embeddings as they signify a variation in the meaning across the domains. Applying the approach to a set of hypothetical scenarios produces promising results. It can help a requirements analyst in preventing misunderstandings during elicitation interviews and meetings by defining a set of potentially ambiguous terms in advance.