 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Importance of Balanced Data Sets: Analyzing a Vehicle Trajectory Prediction Model based on Neural Networks and Distributed Representations
Paper and Code
Sep 30, 2020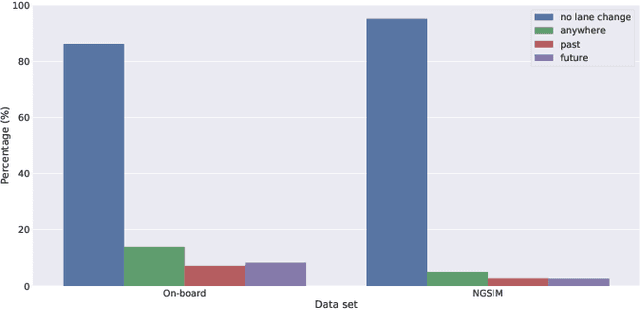

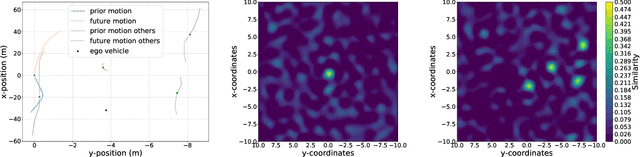

Predicting future behavior of other traffic participants is an essential task that needs to be solved by automated vehicles and human drivers alike to achieve safe and situationaware driving. Modern approaches to vehicles trajectory prediction typically rely on data-driven models like neural networks, in particular LSTMs (Long Short-Term Memorys), achieving promising results. However, the question of optimal composition of the underlying training data has received less attention. In this paper, we expand on previous work on vehicle trajectory prediction based on neural network models employing distributed representations to encode automotive scenes in a semantic vector substrate. We analyze the influence of variations in the training data on the performance of our prediction models. Thereby, we show that the models employing our semantic vector representation outperform the numerical model when trained on an adequate data set and thereby, that the composition of training data in vehicle trajectory prediction is crucial for successful training. We conduct our analysis on challenging real-world driving data.