 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJUMBO: Scalable Multi-task Bayesian Optimization using Offline Data
Jun 02, 2021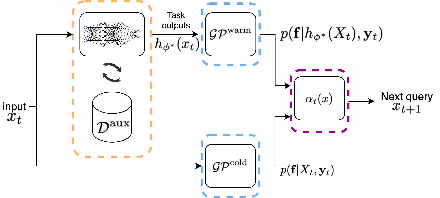

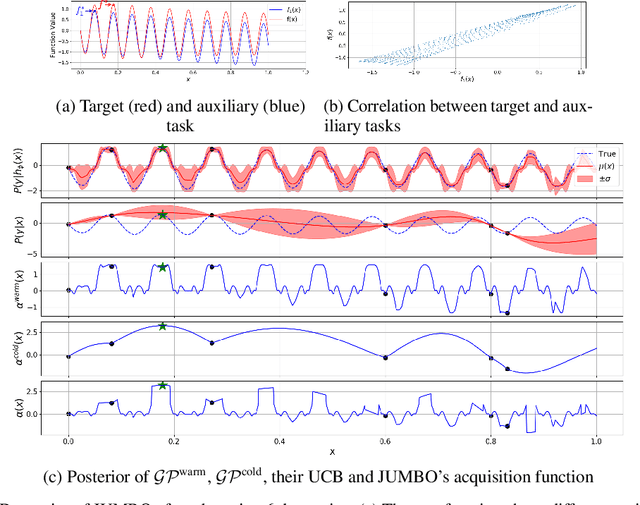
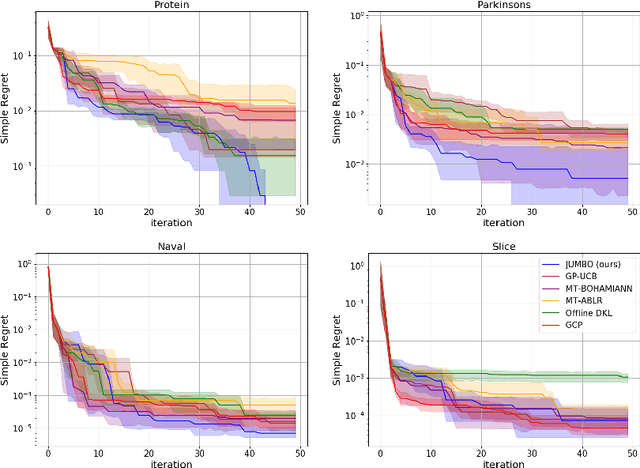
The goal of Multi-task Bayesian Optimization (MBO) is to minimize the number of queries required to accurately optimize a target black-box function, given access to offline evaluations of other auxiliary functions. When offline datasets are large, the scalability of prior approaches comes at the expense of expressivity and inference quality. We propose JUMBO, an MBO algorithm that sidesteps these limitations by querying additional data based on a combination of acquisition signals derived from training two Gaussian Processes (GP): a cold-GP operating directly in the input domain and a warm-GP that operates in the feature space of a deep neural network pretrained using the offline data. Such a decomposition can dynamically control the reliability of information derived from the online and offline data and the use of pretrained neural networks permits scalability to large offline datasets. Theoretically, we derive regret bounds for JUMBO and show that it achieves no-regret under conditions analogous to GP-UCB (Srinivas et. al. 2010). Empirically, we demonstrate significant performance improvements over existing approaches on two real-world optimization problems: hyper-parameter optimization and automated circuit design.
GACEM: Generalized Autoregressive Cross Entropy Method for Multi-Modal Black Box Constraint Satisfaction
Feb 17, 2020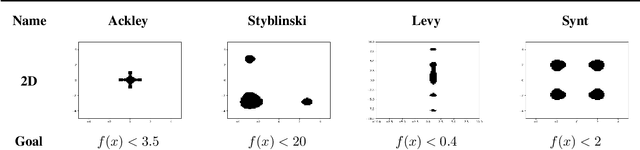
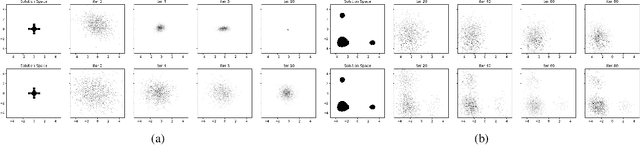
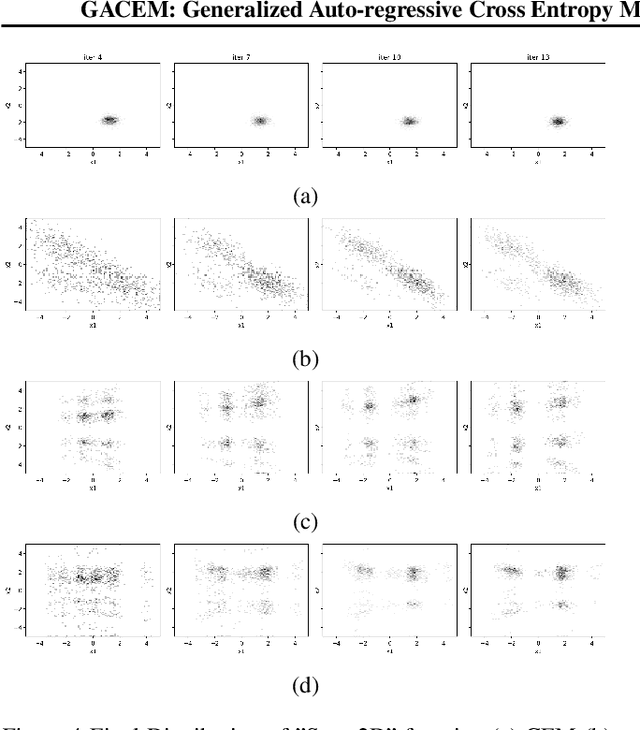
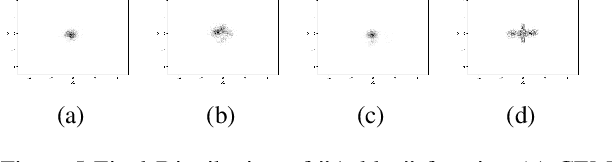
In this work we present a new method of black-box optimization and constraint satisfaction. Existing algorithms that have attempted to solve this problem are unable to consider multiple modes, and are not able to adapt to changes in environment dynamics. To address these issues, we developed a modified Cross-Entropy Method (CEM) that uses a masked auto-regressive neural network for modeling uniform distributions over the solution space. We train the model using maximum entropy policy gradient methods from Reinforcement Learning. Our algorithm is able to express complicated solution spaces, thus allowing it to track a variety of different solution regions. We empirically compare our algorithm with variations of CEM, including one with a Gaussian prior with fixed variance, and demonstrate better performance in terms of: number of diverse solutions, better mode discovery in multi-modal problems, and better sample efficiency in certain cases.
Tuning Algorithms and Generators for Efficient Edge Inference
Jul 31, 2019


A surge in artificial intelligence and autonomous technologies have increased the demand toward enhanced edge-processing capabilities. Computational complexity and size of state-of-the-art Deep Neural Networks (DNNs) are rising exponentially with diverse network models and larger datasets. This growth limits the performance scaling and energy-efficiency of both distributed and embedded inference platforms. Embedded designs at the edge are constrained by energy and speed limitations of available processor substrates and processor to memory communication required to fetch the model coefficients. While many hardware accelerator and network deployment frameworks have been in development, a framework is needed to allow the variety of existing architectures, and those in development, to be expressed in critical parts of the flow that perform various optimization steps. Moreover, premature architecture-blind network selection and optimization diminish the effectiveness of schedule optimizations and hardware-specific mappings. In this paper, we address these issues by creating a cross-layer software-hardware design framework that encompasses network training and model compression that is aware of and tuned to the underlying hardware architecture. This approach leverages the available degrees of DNN structure and sparsity to create a converged network that can be partitioned and efficiently scheduled on the target hardware platform, minimizing data movement, and improving the overall throughput and energy. To further streamline the design, we leverage the high-level, flexible SoC generator platform based on RISC-V ROCC framework. This integration allows seamless extensions of the RISC-V instruction set and Chisel-based rapid generator design. Utilizing this approach, we implemented a silicon prototype in a 16 nm TSMC process node achieving record processing efficiency of up to 18 TOPS/W.
BagNet: Berkeley Analog Generator with Layout Optimizer Boosted with Deep Neural Networks
Jul 23, 2019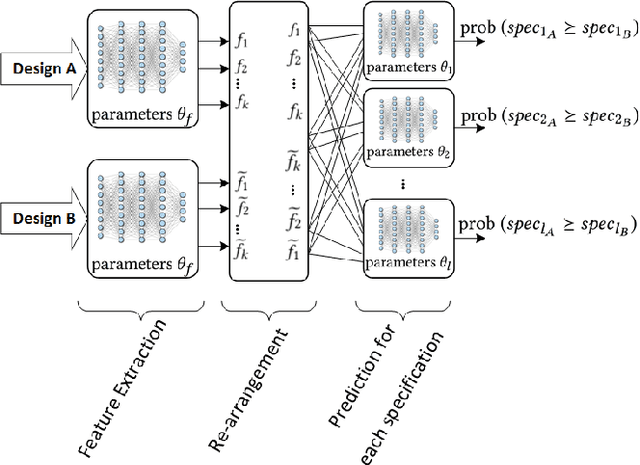
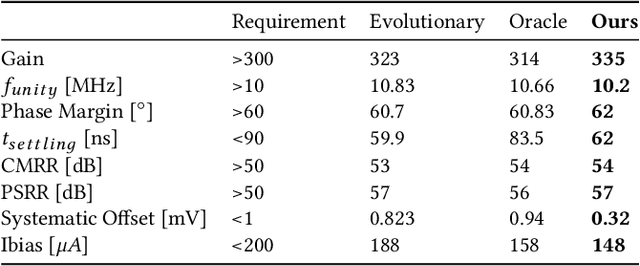
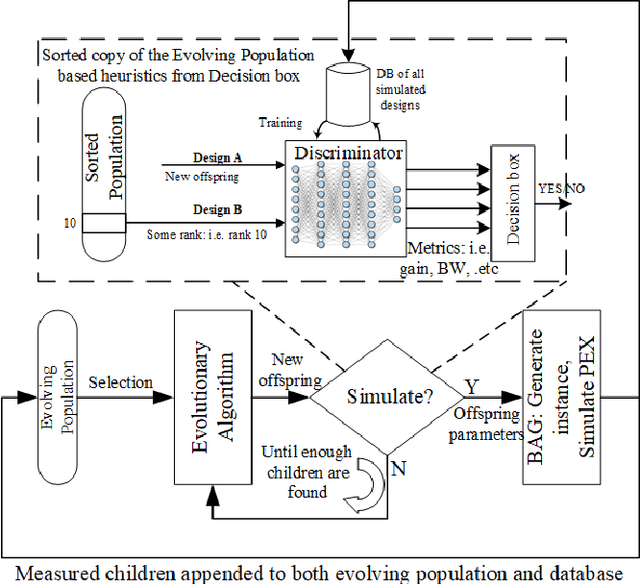

The discrepancy between post-layout and schematic simulation results continues to widen in analog design due in part to the domination of layout parasitics. This paradigm shift is forcing designers to adopt design methodologies that seamlessly integrate layout effects into the standard design flow. Hence, any simulation-based optimization framework should take into account time-consuming post-layout simulation results. This work presents a learning framework that learns to reduce the number of simulations of evolutionary-based combinatorial optimizers, using a DNN that discriminates against generated samples, before running simulations. Using this approach, the discriminator achieves at least two orders of magnitude improvement on sample efficiency for several large circuit examples including an optical link receiver layout.
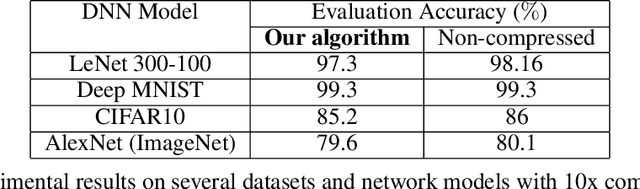
MPDCompress - Matrix Permutation Decomposition Algorithm for Deep Neural Network Compression
May 30, 2018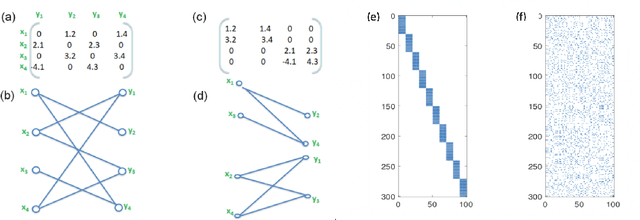
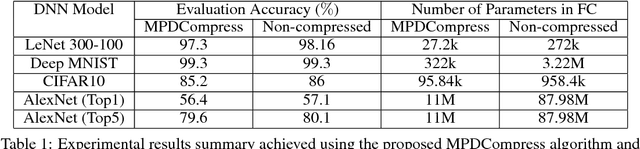
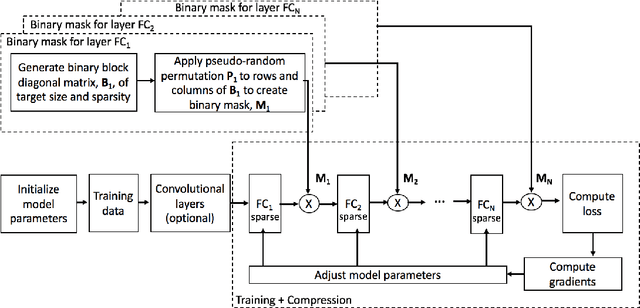

Deep neural networks (DNNs) have become the state-of-the-art technique for machine learning tasks in various applications. However, due to their size and the computational complexity, large DNNs are not readily deployable on edge devices in real-time. To manage complexity and accelerate computation, network compression techniques based on pruning and quantization have been proposed and shown to be effective in reducing network size. However, such network compression can result in irregular matrix structures that are mismatched with modern hardware-accelerated platforms, such as graphics processing units (GPUs) designed to perform the DNN matrix multiplications in a structured (block-based) way. We propose MPDCompress, a DNN compression algorithm based on matrix permutation decomposition via random mask generation. In-training application of the masks molds the synaptic weight connection matrix to a sub-graph separation format. Aided by the random permutations, a hardware-desirable block matrix is generated, allowing for a more efficient implementation and compression of the network. To show versatility, we empirically verify MPDCompress on several network models, compression rates, and image datasets. On the LeNet 300-100 model (MNIST dataset), Deep MNIST, and CIFAR10, we achieve 10 X network compression with less than 1% accuracy loss compared to non-compressed accuracy performance. On AlexNet for the full ImageNet ILSVRC-2012 dataset, we achieve 8 X network compression with less than 1% accuracy loss, with top-5 and top-1 accuracies of 79.6% and 56.4%, respectively. Finally, we observe that the algorithm can offer inference speedups across various hardware platforms, with 4 X faster operation achieved on several mobile GPUs.
Structured Deep Neural Network Pruning via Matrix Pivoting
Dec 01, 2017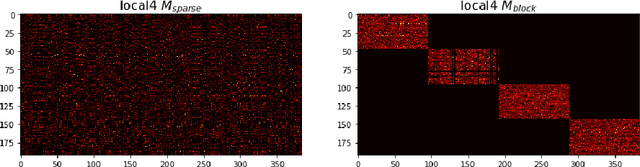
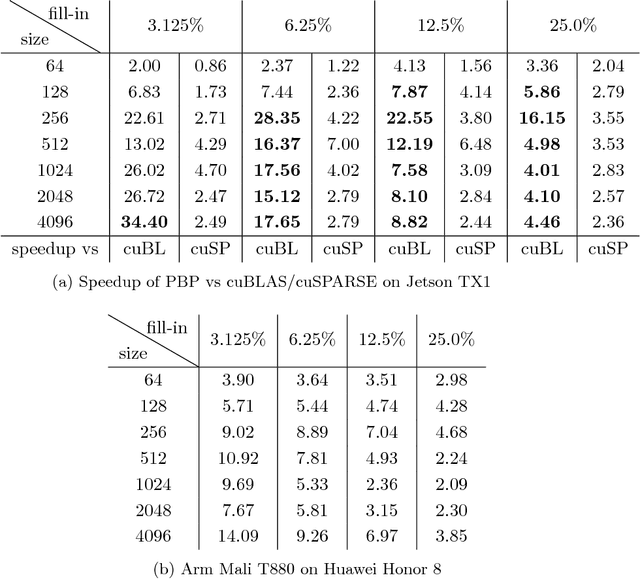
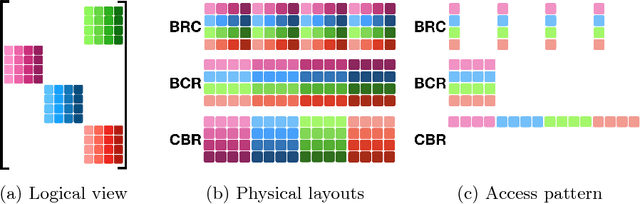
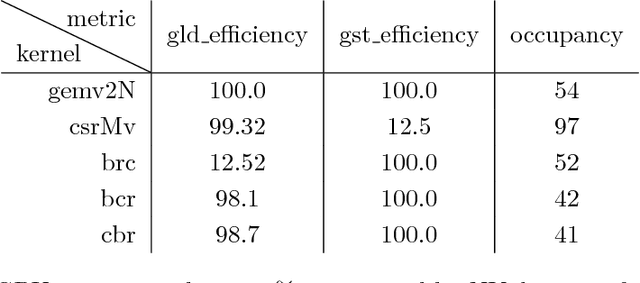
Deep Neural Networks (DNNs) are the key to the state-of-the-art machine vision, sensor fusion and audio/video signal processing. Unfortunately, their computation complexity and tight resource constraints on the Edge make them hard to leverage on mobile, embedded and IoT devices. Due to great diversity of Edge devices, DNN designers have to take into account the hardware platform and application requirements during network training. In this work we introduce pruning via matrix pivoting as a way to improve network pruning by compromising between the design flexibility of architecture-oblivious and performance efficiency of architecture-aware pruning, the two dominant techniques for obtaining resource-efficient DNNs. We also describe local and global network optimization techniques for efficient implementation of the resulting pruned networks. In combination, the proposed pruning and implementation result in close to linear speed up with the reduction of network coefficients during pruning.