 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructured Deep Neural Network Pruning via Matrix Pivoting
Dec 01, 2017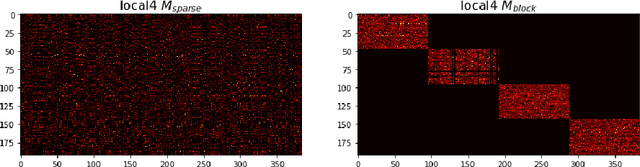
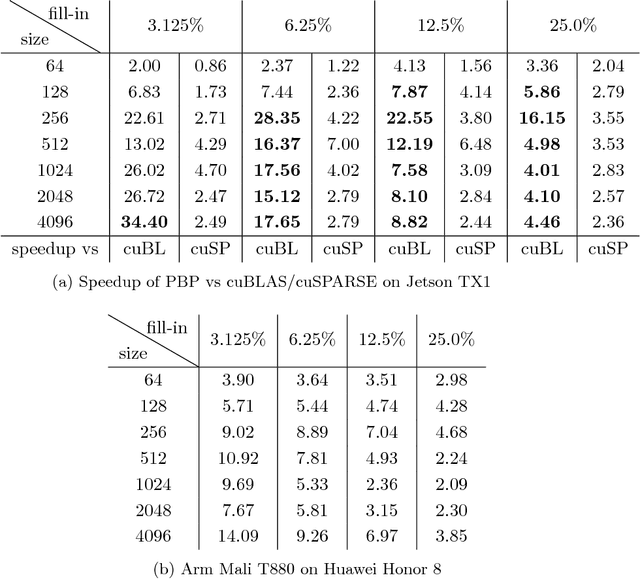
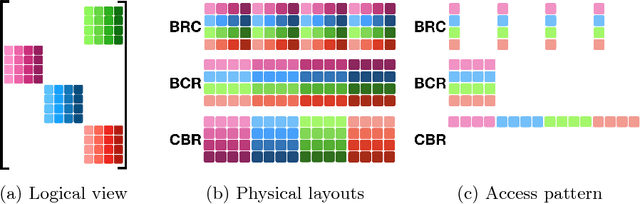
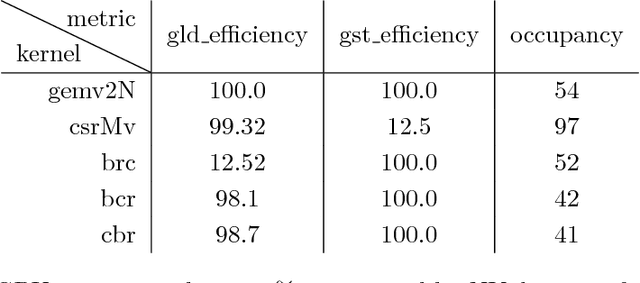
Deep Neural Networks (DNNs) are the key to the state-of-the-art machine vision, sensor fusion and audio/video signal processing. Unfortunately, their computation complexity and tight resource constraints on the Edge make them hard to leverage on mobile, embedded and IoT devices. Due to great diversity of Edge devices, DNN designers have to take into account the hardware platform and application requirements during network training. In this work we introduce pruning via matrix pivoting as a way to improve network pruning by compromising between the design flexibility of architecture-oblivious and performance efficiency of architecture-aware pruning, the two dominant techniques for obtaining resource-efficient DNNs. We also describe local and global network optimization techniques for efficient implementation of the resulting pruned networks. In combination, the proposed pruning and implementation result in close to linear speed up with the reduction of network coefficients during pruning.