 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTuning Algorithms and Generators for Efficient Edge Inference
Jul 31, 2019
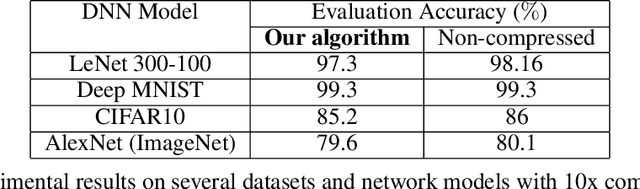


A surge in artificial intelligence and autonomous technologies have increased the demand toward enhanced edge-processing capabilities. Computational complexity and size of state-of-the-art Deep Neural Networks (DNNs) are rising exponentially with diverse network models and larger datasets. This growth limits the performance scaling and energy-efficiency of both distributed and embedded inference platforms. Embedded designs at the edge are constrained by energy and speed limitations of available processor substrates and processor to memory communication required to fetch the model coefficients. While many hardware accelerator and network deployment frameworks have been in development, a framework is needed to allow the variety of existing architectures, and those in development, to be expressed in critical parts of the flow that perform various optimization steps. Moreover, premature architecture-blind network selection and optimization diminish the effectiveness of schedule optimizations and hardware-specific mappings. In this paper, we address these issues by creating a cross-layer software-hardware design framework that encompasses network training and model compression that is aware of and tuned to the underlying hardware architecture. This approach leverages the available degrees of DNN structure and sparsity to create a converged network that can be partitioned and efficiently scheduled on the target hardware platform, minimizing data movement, and improving the overall throughput and energy. To further streamline the design, we leverage the high-level, flexible SoC generator platform based on RISC-V ROCC framework. This integration allows seamless extensions of the RISC-V instruction set and Chisel-based rapid generator design. Utilizing this approach, we implemented a silicon prototype in a 16 nm TSMC process node achieving record processing efficiency of up to 18 TOPS/W.