 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust and High-Fidelity 3D Gaussian Splatting: Fusing Pose Priors and Geometry Constraints for Texture-Deficient Outdoor Scenes
Nov 10, 20253D Gaussian Splatting (3DGS) has emerged as a key rendering pipeline for digital asset creation due to its balance between efficiency and visual quality. To address the issues of unstable pose estimation and scene representation distortion caused by geometric texture inconsistency in large outdoor scenes with weak or repetitive textures, we approach the problem from two aspects: pose estimation and scene representation. For pose estimation, we leverage LiDAR-IMU Odometry to provide prior poses for cameras in large-scale environments. These prior pose constraints are incorporated into COLMAP's triangulation process, with pose optimization performed via bundle adjustment. Ensuring consistency between pixel data association and prior poses helps maintain both robustness and accuracy. For scene representation, we introduce normal vector constraints and effective rank regularization to enforce consistency in the direction and shape of Gaussian primitives. These constraints are jointly optimized with the existing photometric loss to enhance the map quality. We evaluate our approach using both public and self-collected datasets. In terms of pose optimization, our method requires only one-third of the time while maintaining accuracy and robustness across both datasets. In terms of scene representation, the results show that our method significantly outperforms conventional 3DGS pipelines. Notably, on self-collected datasets characterized by weak or repetitive textures, our approach demonstrates enhanced visualization capabilities and achieves superior overall performance. Codes and data will be publicly available at https://github.com/justinyeah/normal_shape.git.
Semi-distributed Cross-modal Air-Ground Relative Localization
Nov 10, 2025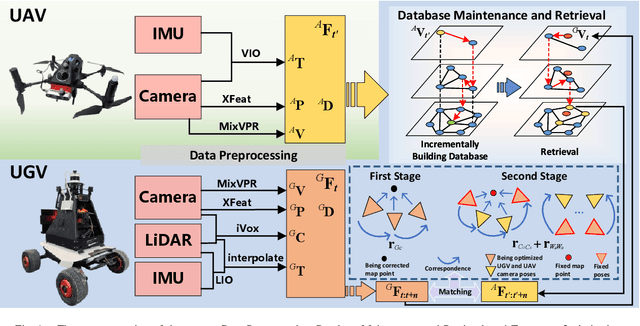
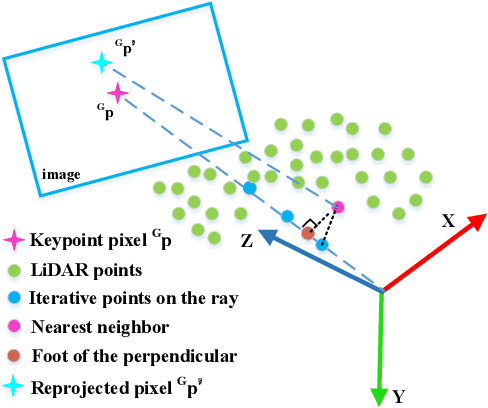

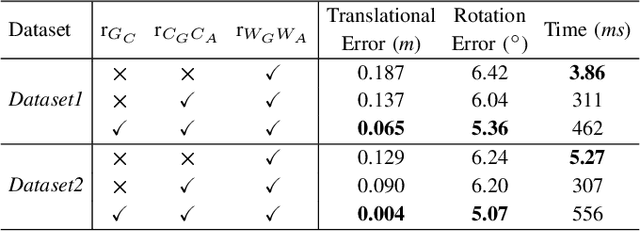
Efficient, accurate, and flexible relative localization is crucial in air-ground collaborative tasks. However, current approaches for robot relative localization are primarily realized in the form of distributed multi-robot SLAM systems with the same sensor configuration, which are tightly coupled with the state estimation of all robots, limiting both flexibility and accuracy. To this end, we fully leverage the high capacity of Unmanned Ground Vehicle (UGV) to integrate multiple sensors, enabling a semi-distributed cross-modal air-ground relative localization framework. In this work, both the UGV and the Unmanned Aerial Vehicle (UAV) independently perform SLAM while extracting deep learning-based keypoints and global descriptors, which decouples the relative localization from the state estimation of all agents. The UGV employs a local Bundle Adjustment (BA) with LiDAR, camera, and an IMU to rapidly obtain accurate relative pose estimates. The BA process adopts sparse keypoint optimization and is divided into two stages: First, optimizing camera poses interpolated from LiDAR-Inertial Odometry (LIO), followed by estimating the relative camera poses between the UGV and UAV. Additionally, we implement an incremental loop closure detection algorithm using deep learning-based descriptors to maintain and retrieve keyframes efficiently. Experimental results demonstrate that our method achieves outstanding performance in both accuracy and efficiency. Unlike traditional multi-robot SLAM approaches that transmit images or point clouds, our method only transmits keypoint pixels and their descriptors, effectively constraining the communication bandwidth under 0.3 Mbps. Codes and data will be publicly available on https://github.com/Ascbpiac/cross-model-relative-localization.git.
Efficient Collaborative Navigation through Perception Fusion for Multi-Robots in Unknown Environments
Nov 02, 2024For tasks conducted in unknown environments with efficiency requirements, real-time navigation of multi-robot systems remains challenging due to unfamiliarity with surroundings.In this paper, we propose a novel multi-robot collaborative planning method that leverages the perception of different robots to intelligently select search directions and improve planning efficiency. Specifically, a foundational planner is employed to ensure reliable exploration towards targets in unknown environments and we introduce Graph Attention Architecture with Information Gain Weight(GIWT) to synthesizes the information from the target robot and its teammates to facilitate effective navigation around obstacles.In GIWT, after regionally encoding the relative positions of the robots along with their perceptual features, we compute the shared attention scores and incorporate the information gain obtained from neighboring robots as a supplementary weight. We design a corresponding expert data generation scheme to simulate real-world decision-making conditions for network training. Simulation experiments and real robot tests demonstrates that the proposed method significantly improves efficiency and enables collaborative planning for multiple robots. Our method achieves approximately 82% accuracy on the expert dataset and reduces the average path length by about 8% and 6% across two types of tasks compared to the fundamental planner in ROS tests, and a path length reduction of over 6% in real-world experiments.
A Social Force Model for Multi-Agent Systems With Application to Robots Traversal in Cluttered Environments
Sep 16, 2024



This letter presents a model to address the collaborative effects in multi-agent systems from the perspective of microscopic mechanism. The model utilizes distributed control for robot swarms in traversal applications. Inspired by pedestrian planning dynamics, the model employs three types of forces to regulate the behavior of agents: intrinsic propulsion, interaction among agents, and repulsion from obstacles. These forces are able to balance the convergence, divergence and avoidance effects among agents. Additionally, we present a planning and decision method based on resultant forces to enable real-world deployment of the model. Experimental results demonstrate the effectiveness on system path optimization in unknown cluttered environments. The sensor data is swiftly digital filtered and the data transmitted is significantly compressed. Consequently, the model has low computation costs and minimal communication loads, thereby promoting environmental adaptability and system scalability.
Highly Efficient Observation Process based on FFT Filtering for Robot Swarm Collaborative Navigation in Unknown Environments
May 13, 2024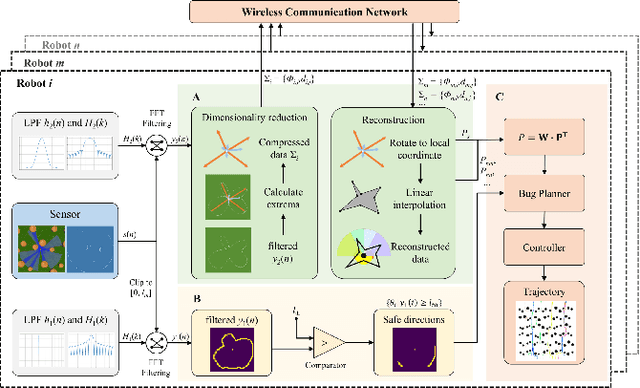
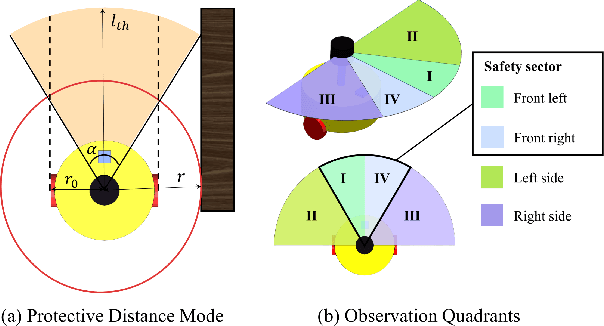
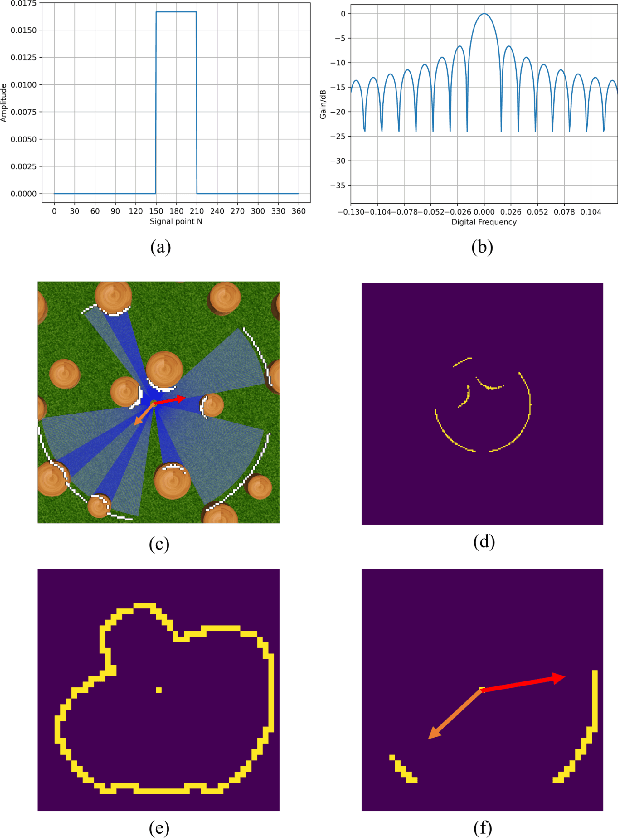
Collaborative path planning for robot swarms in complex, unknown environments without external positioning is a challenging problem. This requires robots to find safe directions based on real-time environmental observations, and to efficiently transfer and fuse these observations within the swarm. This study presents a filtering method based on Fast Fourier Transform (FFT) to address these two issues. We treat sensors' environmental observations as a digital sampling process. Then, we design two different types of filters for safe direction extraction, as well as for the compression and reconstruction of environmental data. The reconstructed data is mapped to probabilistic domain, achieving efficient fusion of swarm observations and planning decision. The computation time is only on the order of microseconds, and the transmission data in communication systems is in bit-level. The performance of our algorithm in sensor data processing was validated in real world experiments, and the effectiveness in swarm path optimization was demonstrated through extensive simulations.
Collaborative Goal Tracking of Multiple Mobile Robots Based on Geometric Graph Neural Network
Nov 13, 2023Multi-robot systems are widely used in spatially distributed tasks, and their collaborative path planning is of great significance for working efficiency. Currently, different multi-robot collaborative path planning methods have been proposed, but how to process the sensory information of neighboring robots at different locations from a local perception perspective in real environment to make better decisions is still a major difficulty. To address this problem, this paper proposes a multi-robot collaborative path planning method based on geometric graph neural network (GeoGNN). GeoGNN introduces the relative position information of neighboring robots into each interaction layer of the graph neural network to better integrate neighbor sensing information. An expert data generation method is designed for the robot to advance in a single step, by which expert data are generated in ROS to train the network. Experimental results show that the accuracy of the proposed method is improved by about 5% compared to the model based only on CNN on the expert data set. In ROS simulation environment path planning test, the success rate is improved by about 4% compared to CNN and flowtime increase is reduced about 8%, which outperforms other graph neural network models.
Transform-Equivariant Consistency Learning for Temporal Sentence Grounding
May 06, 2023



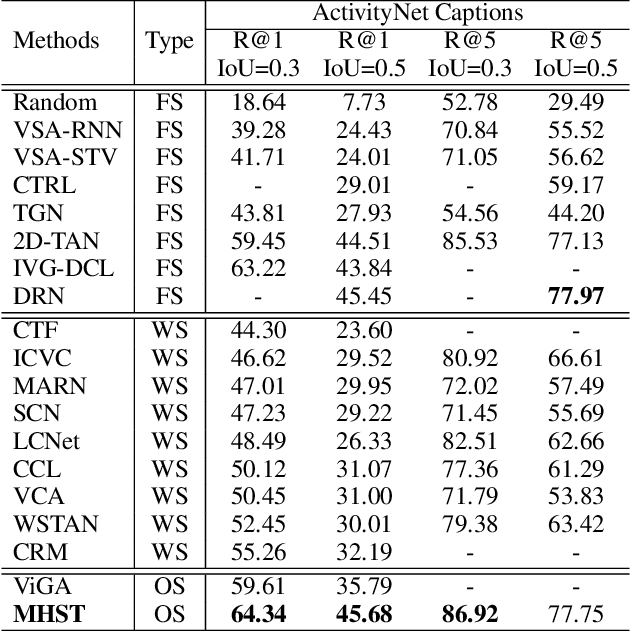
This paper addresses the temporal sentence grounding (TSG). Although existing methods have made decent achievements in this task, they not only severely rely on abundant video-query paired data for training, but also easily fail into the dataset distribution bias. To alleviate these limitations, we introduce a novel Equivariant Consistency Regulation Learning (ECRL) framework to learn more discriminative query-related frame-wise representations for each video, in a self-supervised manner. Our motivation comes from that the temporal boundary of the query-guided activity should be consistently predicted under various video-level transformations. Concretely, we first design a series of spatio-temporal augmentations on both foreground and background video segments to generate a set of synthetic video samples. In particular, we devise a self-refine module to enhance the completeness and smoothness of the augmented video. Then, we present a novel self-supervised consistency loss (SSCL) applied on the original and augmented videos to capture their invariant query-related semantic by minimizing the KL-divergence between the sequence similarity of two videos and a prior Gaussian distribution of timestamp distance. At last, a shared grounding head is introduced to predict the transform-equivariant query-guided segment boundaries for both the original and augmented videos. Extensive experiments on three challenging datasets (ActivityNet, TACoS, and Charades-STA) demonstrate both effectiveness and efficiency of our proposed ECRL framework.
Hypotheses Tree Building for One-Shot Temporal Sentence Localization
Jan 15, 2023
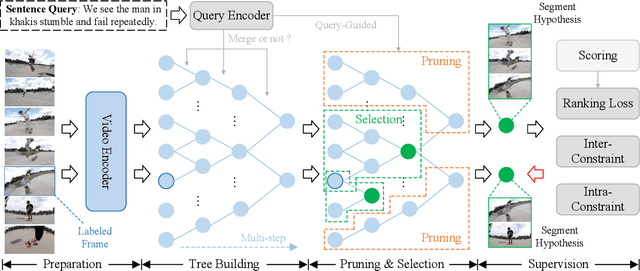
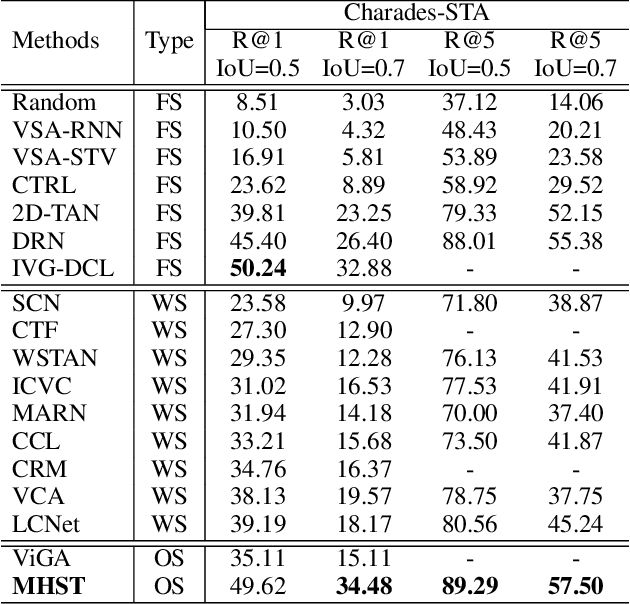
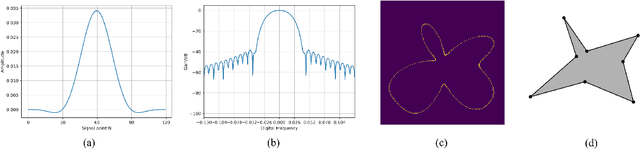
Given an untrimmed video, temporal sentence localization (TSL) aims to localize a specific segment according to a given sentence query. Though respectable works have made decent achievements in this task, they severely rely on dense video frame annotations, which require a tremendous amount of human effort to collect. In this paper, we target another more practical and challenging setting: one-shot temporal sentence localization (one-shot TSL), which learns to retrieve the query information among the entire video with only one annotated frame. Particularly, we propose an effective and novel tree-structure baseline for one-shot TSL, called Multiple Hypotheses Segment Tree (MHST), to capture the query-aware discriminative frame-wise information under the insufficient annotations. Each video frame is taken as the leaf-node, and the adjacent frames sharing the same visual-linguistic semantics will be merged into the upper non-leaf node for tree building. At last, each root node is an individual segment hypothesis containing the consecutive frames of its leaf-nodes. During the tree construction, we also introduce a pruning strategy to eliminate the interference of query-irrelevant nodes. With our designed self-supervised loss functions, our MHST is able to generate high-quality segment hypotheses for ranking and selection with the query. Experiments on two challenging datasets demonstrate that MHST achieves competitive performance compared to existing methods.
Doubly Convolutional Neural Networks
Oct 30, 2016
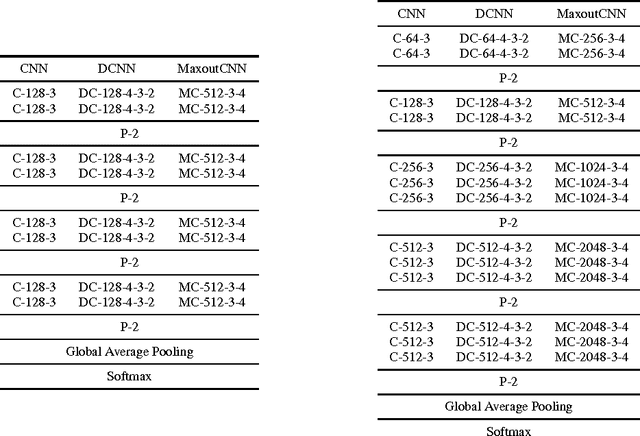

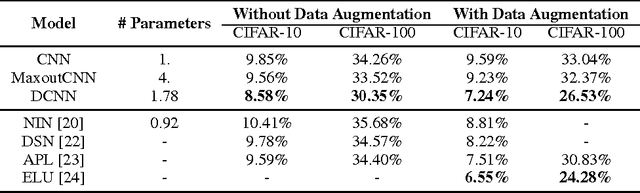
Building large models with parameter sharing accounts for most of the success of deep convolutional neural networks (CNNs). In this paper, we propose doubly convolutional neural networks (DCNNs), which significantly improve the performance of CNNs by further exploring this idea. In stead of allocating a set of convolutional filters that are independently learned, a DCNN maintains groups of filters where filters within each group are translated versions of each other. Practically, a DCNN can be easily implemented by a two-step convolution procedure, which is supported by most modern deep learning libraries. We perform extensive experiments on three image classification benchmarks: CIFAR-10, CIFAR-100 and ImageNet, and show that DCNNs consistently outperform other competing architectures. We have also verified that replacing a convolutional layer with a doubly convolutional layer at any depth of a CNN can improve its performance. Moreover, various design choices of DCNNs are demonstrated, which shows that DCNN can serve the dual purpose of building more accurate models and/or reducing the memory footprint without sacrificing the accuracy.
Deep Structured Energy Based Models for Anomaly Detection
Jun 16, 2016
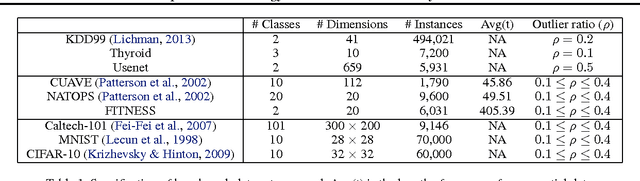
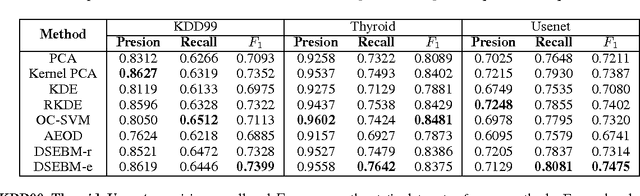
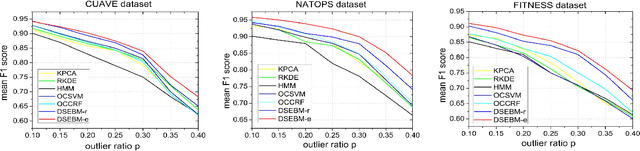
In this paper, we attack the anomaly detection problem by directly modeling the data distribution with deep architectures. We propose deep structured energy based models (DSEBMs), where the energy function is the output of a deterministic deep neural network with structure. We develop novel model architectures to integrate EBMs with different types of data such as static data, sequential data, and spatial data, and apply appropriate model architectures to adapt to the data structure. Our training algorithm is built upon the recent development of score matching \cite{sm}, which connects an EBM with a regularized autoencoder, eliminating the need for complicated sampling method. Statistically sound decision criterion can be derived for anomaly detection purpose from the perspective of the energy landscape of the data distribution. We investigate two decision criteria for performing anomaly detection: the energy score and the reconstruction error. Extensive empirical studies on benchmark tasks demonstrate that our proposed model consistently matches or outperforms all the competing methods.