 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnANet: Modeling Association and Alignment for Cross-modal Correlation Classification
Paper and Code

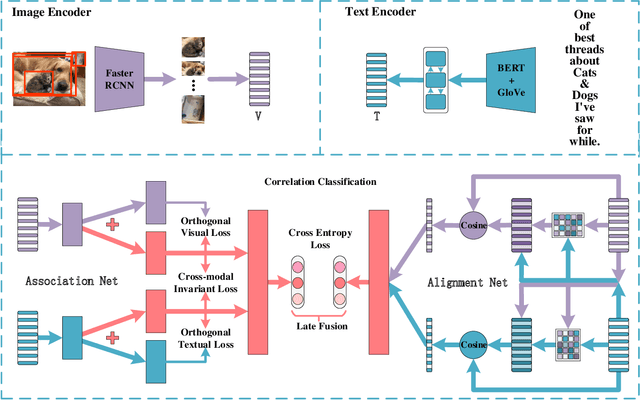

The explosive increase of multimodal data makes a great demand in many cross-modal applications that follow the strict prior related assumption. Thus researchers study the definition of cross-modal correlation category and construct various classification systems and predictive models. However, those systems pay more attention to the fine-grained relevant types of cross-modal correlation, ignoring lots of implicit relevant data which are often divided into irrelevant types. What's worse is that none of previous predictive models manifest the essence of cross-modal correlation according to their definition at the modeling stage. In this paper, we present a comprehensive analysis of the image-text correlation and redefine a new classification system based on implicit association and explicit alignment. To predict the type of image-text correlation, we propose the Association and Alignment Network according to our proposed definition (namely AnANet) which implicitly represents the global discrepancy and commonality between image and text and explicitly captures the cross-modal local relevance. The experimental results on our constructed new image-text correlation dataset show the effectiveness of our model.