 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePiano Transcription by Hierarchical Language Modeling with Pretrained Roll-based Encoders
Jan 07, 2025



Automatic Music Transcription (AMT), aiming to get musical notes from raw audio, typically uses frame-level systems with piano-roll outputs or language model (LM)-based systems with note-level predictions. However, frame-level systems require manual thresholding, while the LM-based systems struggle with long sequences. In this paper, we propose a hybrid method combining pre-trained roll-based encoders with an LM decoder to leverage the strengths of both methods. Besides, our approach employs a hierarchical prediction strategy, first predicting onset and pitch, then velocity, and finally offset. The hierarchical prediction strategy reduces computational costs by breaking down long sequences into different hierarchies. Evaluated on two benchmark roll-based encoders, our method outperforms traditional piano-roll outputs 0.01 and 0.022 in onset-offset-velocity F1 score, demonstrating its potential as a performance-enhancing plug-in for arbitrary roll-based music transcription encoder.
Ms-senet: Enhancing Speech Emotion Recognition Through Multi-scale Feature Fusion With Squeeze-and-excitation Blocks
Dec 25, 2023



Speech Emotion Recognition (SER) has become a growing focus of research in human-computer interaction. Spatiotemporal features play a crucial role in SER, yet current research lacks comprehensive spatiotemporal feature learning. This paper focuses on addressing this gap by proposing a novel approach. In this paper, we employ Convolutional Neural Network (CNN) with varying kernel sizes for spatial and temporal feature extraction. Additionally, we introduce Squeeze-and-Excitation (SE) modules to capture and fuse multi-scale features, facilitating effective information fusion for improved emotion recognition and a deeper understanding of the temporal evolution of speech emotion. Moreover, we employ skip connections and Spatial Dropout (SD) layers to prevent overfitting and increase the model's depth. Our method outperforms the previous state-of-the-art method, achieving an average UAR and WAR improvement of 1.62% and 1.32%, respectively, across six benchmark SER datasets. Further experiments demonstrated that our method can fully extract spatiotemporal features in low-resource conditions.
MERTech: Instrument Playing Technique Detection Using Self-Supervised Pretrained Model With Multi-Task Finetuning
Oct 15, 2023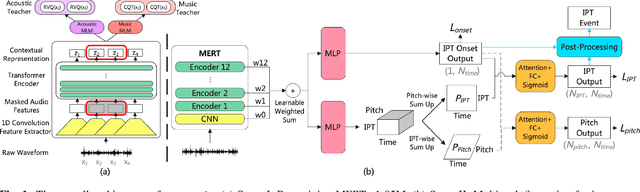
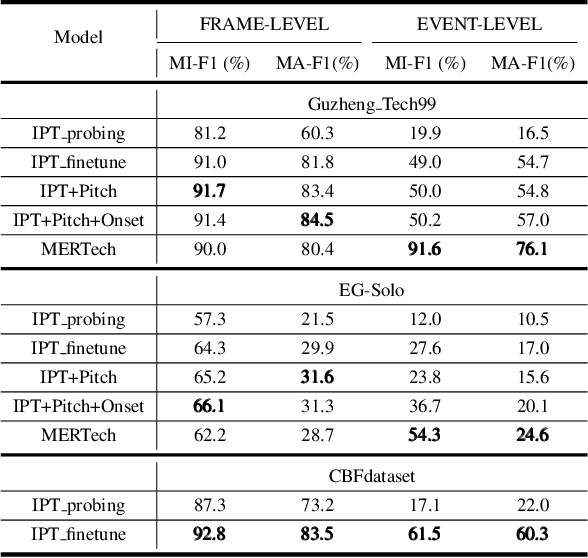
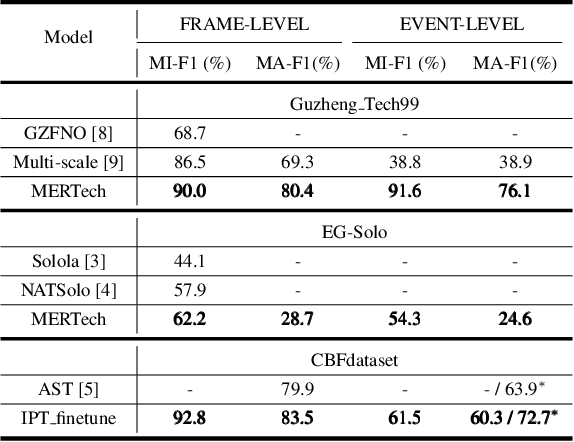
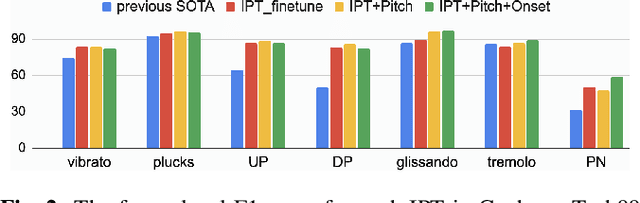
Instrument playing techniques (IPTs) constitute a pivotal component of musical expression. However, the development of automatic IPT detection methods suffers from limited labeled data and inherent class imbalance issues. In this paper, we propose to apply a self-supervised learning model pre-trained on large-scale unlabeled music data and finetune it on IPT detection tasks. This approach addresses data scarcity and class imbalance challenges. Recognizing the significance of pitch in capturing the nuances of IPTs and the importance of onset in locating IPT events, we investigate multi-task finetuning with pitch and onset detection as auxiliary tasks. Additionally, we apply a post-processing approach for event-level prediction, where an IPT activation initiates an event only if the onset output confirms an onset in that frame. Our method outperforms prior approaches in both frame-level and event-level metrics across multiple IPT benchmark datasets. Further experiments demonstrate the efficacy of multi-task finetuning on each IPT class.
Frame-Level Multi-Label Playing Technique Detection Using Multi-Scale Network and Self-Attention Mechanism
Mar 23, 2023Instrument playing technique (IPT) is a key element of musical presentation. However, most of the existing works for IPT detection only concern monophonic music signals, yet little has been done to detect IPTs in polyphonic instrumental solo pieces with overlapping IPTs or mixed IPTs. In this paper, we formulate it as a frame-level multi-label classification problem and apply it to Guzheng, a Chinese plucked string instrument. We create a new dataset, Guzheng\_Tech99, containing Guzheng recordings and onset, offset, pitch, IPT annotations of each note. Because different IPTs vary a lot in their lengths, we propose a new method to solve this problem using multi-scale network and self-attention. The multi-scale network extracts features from different scales, and the self-attention mechanism applied to the feature maps at the coarsest scale further enhances the long-range feature extraction. Our approach outperforms existing works by a large margin, indicating its effectiveness in IPT detection.
Playing Technique Detection by Fusing Note Onset Information in Guzheng Performance
Sep 19, 2022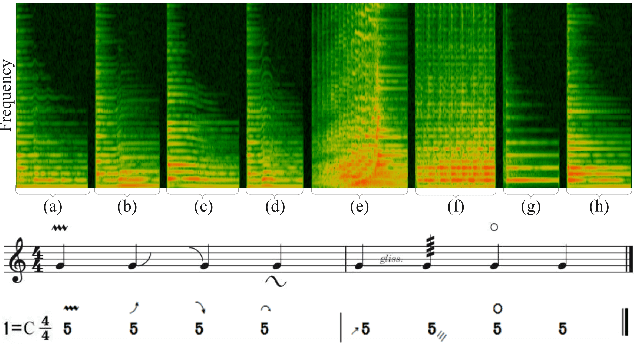
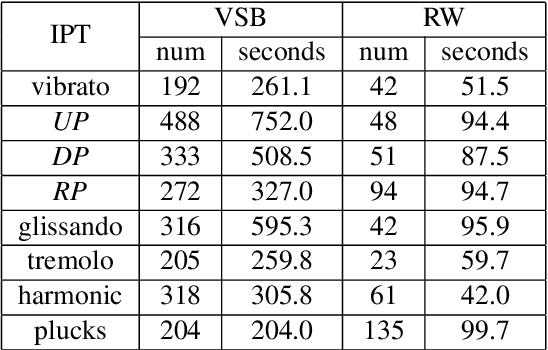
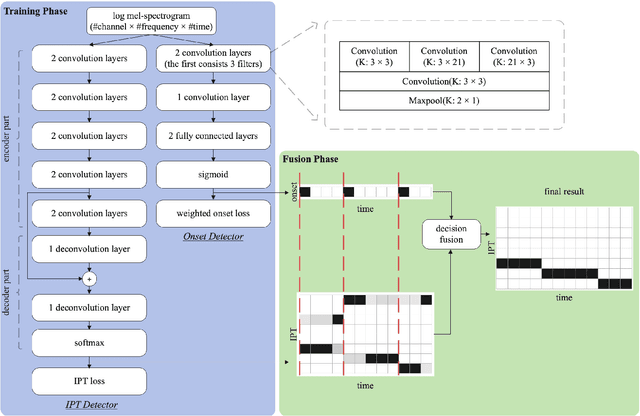

The Guzheng is a kind of traditional Chinese instruments with diverse playing techniques. Instrument playing techniques (IPT) play an important role in musical performance. However, most of the existing works for IPT detection show low efficiency for variable-length audio and provide no assurance in the generalization as they rely on a single sound bank for training and testing. In this study, we propose an end-to-end Guzheng playing technique detection system using Fully Convolutional Networks that can be applied to variable-length audio. Because each Guzheng playing technique is applied to a note, a dedicated onset detector is trained to divide an audio into several notes and its predictions are fused with frame-wise IPT predictions. During fusion, we add the IPT predictions frame by frame inside each note and get the IPT with the highest probability within each note as the final output of that note. We create a new dataset named GZ_IsoTech from multiple sound banks and real-world recordings for Guzheng performance analysis. Our approach achieves 87.97% in frame-level accuracy and 80.76% in note-level F1-score, outperforming existing works by a large margin, which indicates the effectiveness of our proposed method in IPT detection.