 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQifusion-Net: Layer-adapted Stream/Non-stream Model for End-to-End Multi-Accent Speech Recognition
Jul 03, 2024



Currently, end-to-end (E2E) speech recognition methods have achieved promising performance. However, auto speech recognition (ASR) models still face challenges in recognizing multi-accent speech accurately. We propose a layer-adapted fusion (LAF) model, called Qifusion-Net, which does not require any prior knowledge about the target accent. Based on dynamic chunk strategy, our approach enables streaming decoding and can extract frame-level acoustic feature, facilitating fine-grained information fusion. Experiment results demonstrate that our proposed methods outperform the baseline with relative reductions of 22.1$\%$ and 17.2$\%$ in character error rate (CER) across multi accent test datasets on KeSpeech and MagicData-RMAC.
Ms-senet: Enhancing Speech Emotion Recognition Through Multi-scale Feature Fusion With Squeeze-and-excitation Blocks
Dec 25, 2023



Speech Emotion Recognition (SER) has become a growing focus of research in human-computer interaction. Spatiotemporal features play a crucial role in SER, yet current research lacks comprehensive spatiotemporal feature learning. This paper focuses on addressing this gap by proposing a novel approach. In this paper, we employ Convolutional Neural Network (CNN) with varying kernel sizes for spatial and temporal feature extraction. Additionally, we introduce Squeeze-and-Excitation (SE) modules to capture and fuse multi-scale features, facilitating effective information fusion for improved emotion recognition and a deeper understanding of the temporal evolution of speech emotion. Moreover, we employ skip connections and Spatial Dropout (SD) layers to prevent overfitting and increase the model's depth. Our method outperforms the previous state-of-the-art method, achieving an average UAR and WAR improvement of 1.62% and 1.32%, respectively, across six benchmark SER datasets. Further experiments demonstrated that our method can fully extract spatiotemporal features in low-resource conditions.
Approximate Nearest Neighbor Search under Neural Similarity Metric for Large-Scale Recommendation
Feb 28, 2022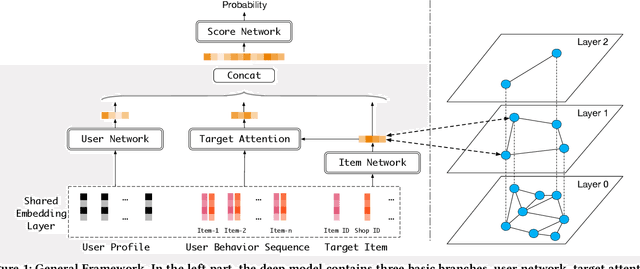

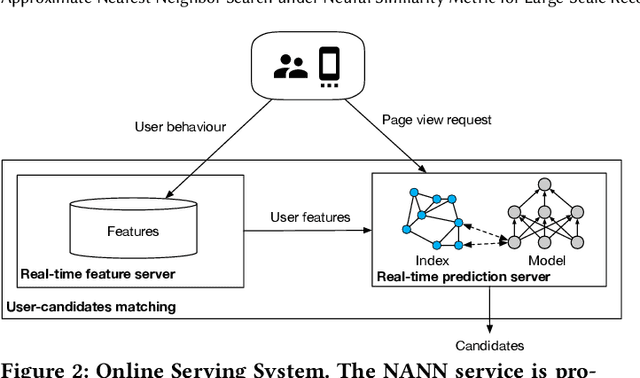
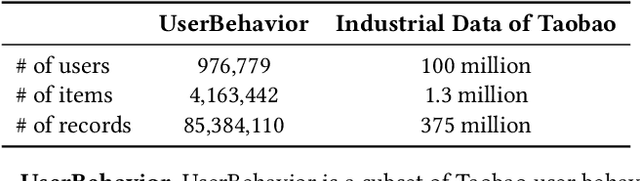
Model-based methods for recommender systems have been studied extensively for years. Modern recommender systems usually resort to 1) representation learning models which define user-item preference as the distance between their embedding representations, and 2) embedding-based Approximate Nearest Neighbor (ANN) search to tackle the efficiency problem introduced by large-scale corpus. While providing efficient retrieval, the embedding-based retrieval pattern also limits the model capacity since the form of user-item preference measure is restricted to the distance between their embedding representations. However, for other more precise user-item preference measures, e.g., preference scores directly derived from a deep neural network, they are computationally intractable because of the lack of an efficient retrieval method, and an exhaustive search for all user-item pairs is impractical. In this paper, we propose a novel method to extend ANN search to arbitrary matching functions, e.g., a deep neural network. Our main idea is to perform a greedy walk with a matching function in a similarity graph constructed from all items. To solve the problem that the similarity measures of graph construction and user-item matching function are heterogeneous, we propose a pluggable adversarial training task to ensure the graph search with arbitrary matching function can achieve fairly high precision. Experimental results in both open source and industry datasets demonstrate the effectiveness of our method. The proposed method has been fully deployed in the Taobao display advertising platform and brings a considerable advertising revenue increase. We also summarize our detailed experiences in deployment in this paper.