 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApproximate Nearest Neighbor Search under Neural Similarity Metric for Large-Scale Recommendation
Feb 28, 2022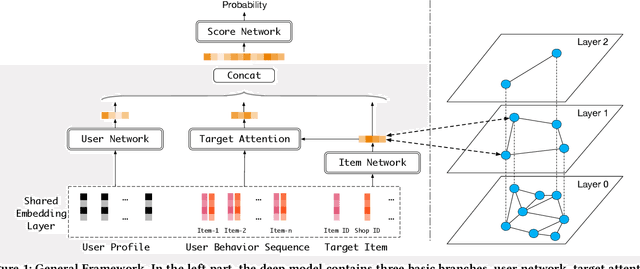

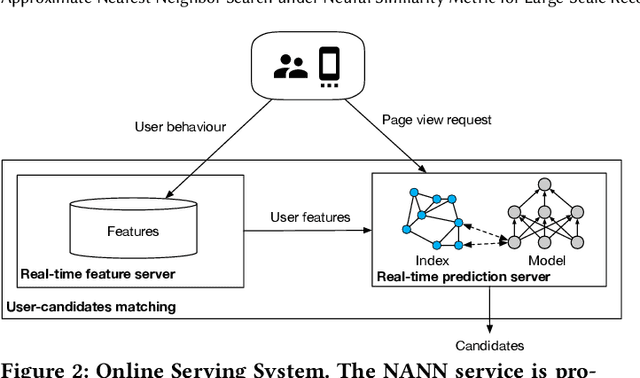
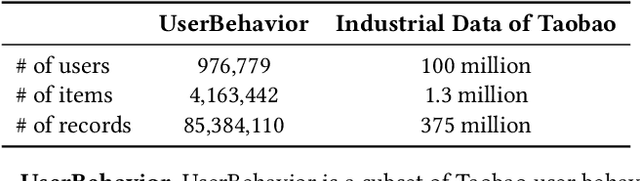
Model-based methods for recommender systems have been studied extensively for years. Modern recommender systems usually resort to 1) representation learning models which define user-item preference as the distance between their embedding representations, and 2) embedding-based Approximate Nearest Neighbor (ANN) search to tackle the efficiency problem introduced by large-scale corpus. While providing efficient retrieval, the embedding-based retrieval pattern also limits the model capacity since the form of user-item preference measure is restricted to the distance between their embedding representations. However, for other more precise user-item preference measures, e.g., preference scores directly derived from a deep neural network, they are computationally intractable because of the lack of an efficient retrieval method, and an exhaustive search for all user-item pairs is impractical. In this paper, we propose a novel method to extend ANN search to arbitrary matching functions, e.g., a deep neural network. Our main idea is to perform a greedy walk with a matching function in a similarity graph constructed from all items. To solve the problem that the similarity measures of graph construction and user-item matching function are heterogeneous, we propose a pluggable adversarial training task to ensure the graph search with arbitrary matching function can achieve fairly high precision. Experimental results in both open source and industry datasets demonstrate the effectiveness of our method. The proposed method has been fully deployed in the Taobao display advertising platform and brings a considerable advertising revenue increase. We also summarize our detailed experiences in deployment in this paper.
DCAF: A Dynamic Computation Allocation Framework for Online Serving System
Jun 17, 2020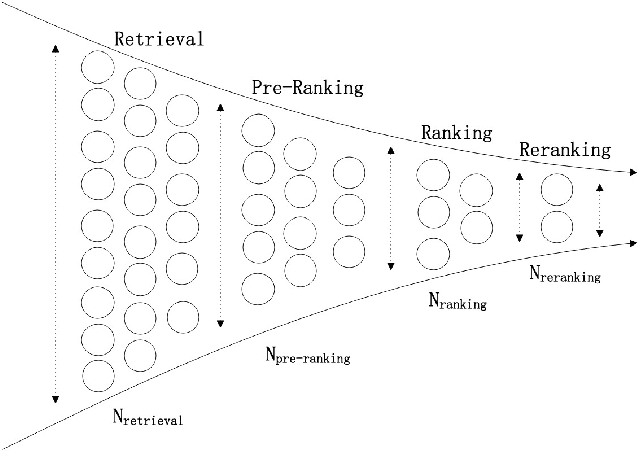
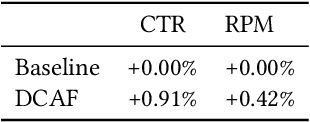
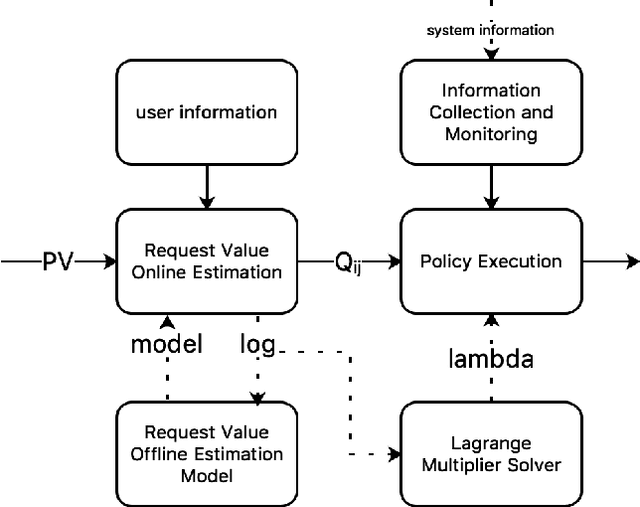

Modern large-scale systems such as recommender system and online advertising system are built upon computation-intensive infrastructure. The typical objective in these applications is to maximize the total revenue, e.g. GMV~(Gross Merchandise Volume), under a limited computation resource. Usually, the online serving system follows a multi-stage cascade architecture, which consists of several stages including retrieval, pre-ranking, ranking, etc. These stages usually allocate resource manually with specific computing power budgets, which requires the serving configuration to adapt accordingly. As a result, the existing system easily falls into suboptimal solutions with respect to maximizing the total revenue. The limitation is due to the face that, although the value of traffic requests vary greatly, online serving system still spends equal computing power among them. In this paper, we introduce a novel idea that online serving system could treat each traffic request differently and allocate "personalized" computation resource based on its value. We formulate this resource allocation problem as a knapsack problem and propose a Dynamic Computation Allocation Framework~(DCAF). Under some general assumptions, DCAF can theoretically guarantee that the system can maximize the total revenue within given computation budget. DCAF brings significant improvement and has been deployed in the display advertising system of Taobao for serving the main traffic. With DCAF, we are able to maintain the same business performance with 20\% computation resource reduction.