 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTight Gap-Dependent Memory-Regret Trade-Off for Single-Pass Streaming Stochastic Multi-Armed Bandits
Paper and Code
Mar 04, 2025
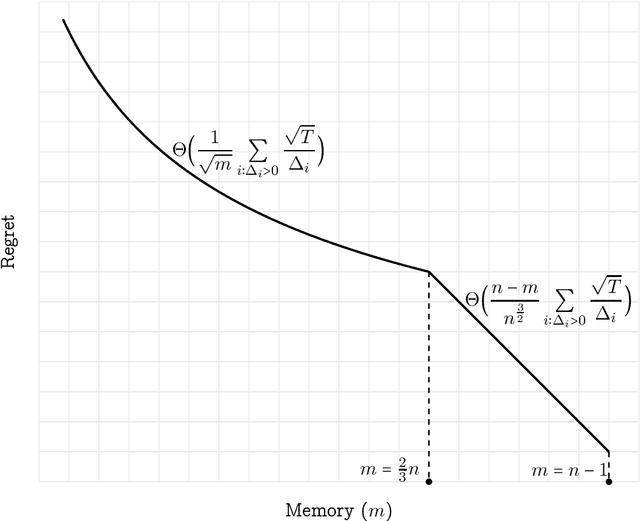
We study the problem of minimizing gap-dependent regret for single-pass streaming stochastic multi-armed bandits (MAB). In this problem, the $n$ arms are present in a stream, and at most $m<n$ arms and their statistics can be stored in the memory. We establish tight non-asymptotic regret bounds regarding all relevant parameters, including the number of arms $n$, the memory size $m$, the number of rounds $T$ and $(\Delta_i)_{i\in [n]}$ where $\Delta_i$ is the reward mean gap between the best arm and the $i$-th arm. These gaps are not known in advance by the player. Specifically, for any constant $\alpha \ge 1$, we present two algorithms: one applicable for $m\ge \frac{2}{3}n$ with regret at most $O_\alpha\Big(\frac{(n-m)T^{\frac{1}{\alpha + 1}}}{n^{1 + {\frac{1}{\alpha + 1}}}}\displaystyle\sum_{i:\Delta_i > 0}\Delta_i^{1 - 2\alpha}\Big)$ and another applicable for $m<\frac{2}{3}n$ with regret at most $O_\alpha\Big(\frac{T^{\frac{1}{\alpha+1}}}{m^{\frac{1}{\alpha+1}}}\displaystyle\sum_{i:\Delta_i > 0}\Delta_i^{1 - 2\alpha}\Big)$. We also prove matching lower bounds for both cases by showing that for any constant $\alpha\ge 1$ and any $m\leq k < n$, there exists a set of hard instances on which the regret of any algorithm is $\Omega_\alpha\Big(\frac{(k-m+1) T^{\frac{1}{\alpha+1}}}{k^{1 + \frac{1}{\alpha+1}}} \sum_{i:\Delta_i > 0}\Delta_i^{1-2\alpha}\Big)$. This is the first tight gap-dependent regret bound for streaming MAB. Prior to our work, an $O\Big(\sum_{i\colon\Delta>0} \frac{\sqrt{T}\log T}{\Delta_i}\Big)$ upper bound for the special case of $\alpha=1$ and $m=O(1)$ was established by Agarwal, Khanna and Patil (COLT'22). In contrast, our results provide the correct order of regret as $\Theta\Big(\frac{1}{\sqrt{m}}\sum_{i\colon\Delta>0}\frac{\sqrt{T}}{\Delta_i}\Big)$.