 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformer-based Models for Long-Form Document Matching: Challenges and Empirical Analysis
Feb 07, 2023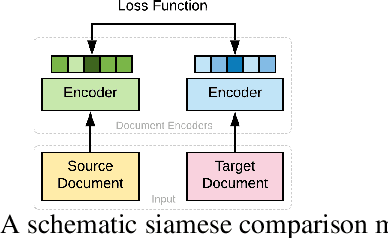
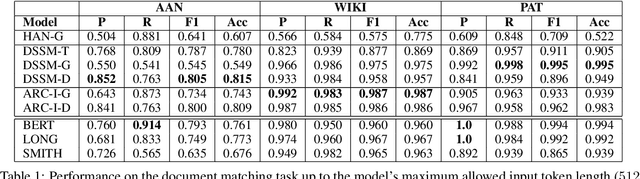
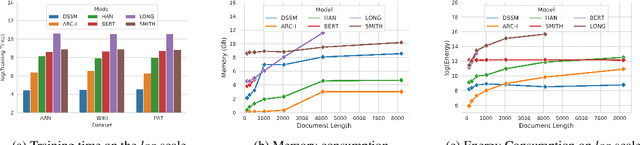

Recent advances in the area of long document matching have primarily focused on using transformer-based models for long document encoding and matching. There are two primary challenges associated with these models. Firstly, the performance gain provided by transformer-based models comes at a steep cost - both in terms of the required training time and the resource (memory and energy) consumption. The second major limitation is their inability to handle more than a pre-defined input token length at a time. In this work, we empirically demonstrate the effectiveness of simple neural models (such as feed-forward networks, and CNNs) and simple embeddings (like GloVe, and Paragraph Vector) over transformer-based models on the task of document matching. We show that simple models outperform the more complex BERT-based models while taking significantly less training time, energy, and memory. The simple models are also more robust to variations in document length and text perturbations.