 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMythQA: Query-Based Large-Scale Check-Worthy Claim Detection through Multi-Answer Open-Domain Question Answering
Paper and Code

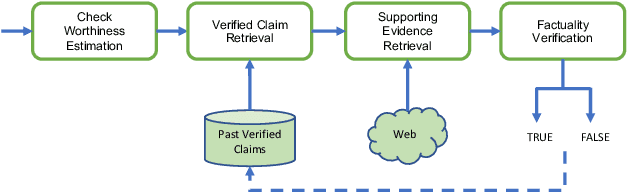
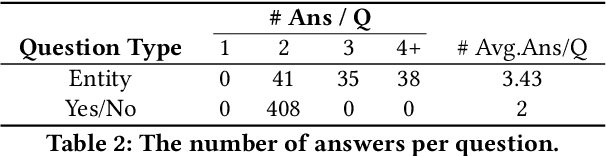
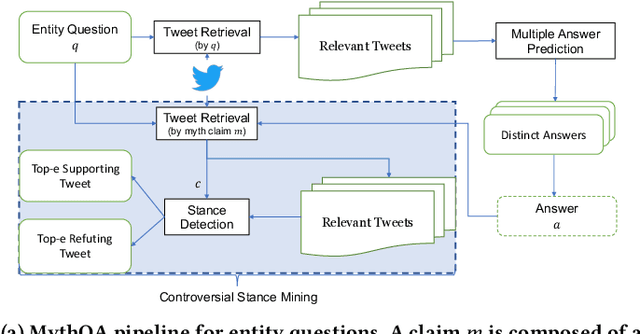
Check-worthy claim detection aims at providing plausible misinformation to downstream fact-checking systems or human experts to check. This is a crucial step toward accelerating the fact-checking process. Many efforts have been put into how to identify check-worthy claims from a small scale of pre-collected claims, but how to efficiently detect check-worthy claims directly from a large-scale information source, such as Twitter, remains underexplored. To fill this gap, we introduce MythQA, a new multi-answer open-domain question answering(QA) task that involves contradictory stance mining for query-based large-scale check-worthy claim detection. The idea behind this is that contradictory claims are a strong indicator of misinformation that merits scrutiny by the appropriate authorities. To study this task, we construct TweetMythQA, an evaluation dataset containing 522 factoid multi-answer questions based on controversial topics. Each question is annotated with multiple answers. Moreover, we collect relevant tweets for each distinct answer, then classify them into three categories: "Supporting", "Refuting", and "Neutral". In total, we annotated 5.3K tweets. Contradictory evidence is collected for all answers in the dataset. Finally, we present a baseline system for MythQA and evaluate existing NLP models for each system component using the TweetMythQA dataset. We provide initial benchmarks and identify key challenges for future models to improve upon. Code and data are available at: https://github.com/TonyBY/Myth-QA