 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniSymNet: A Unified Symbolic Network Guided by Transformer
May 09, 2025
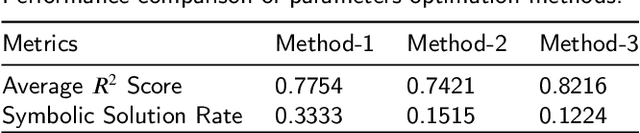
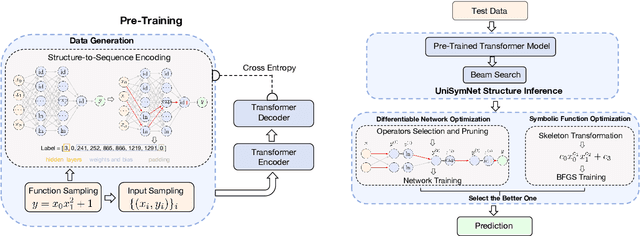
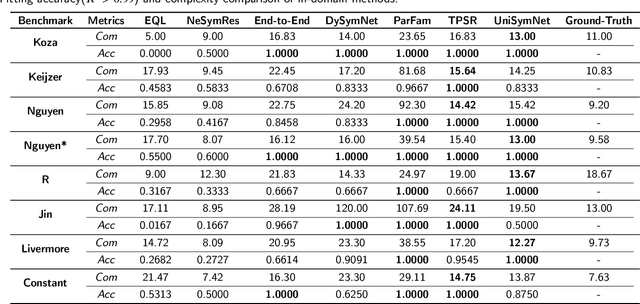
Symbolic Regression (SR) is a powerful technique for automatically discovering mathematical expressions from input data. Mainstream SR algorithms search for the optimal symbolic tree in a vast function space, but the increasing complexity of the tree structure limits their performance. Inspired by neural networks, symbolic networks have emerged as a promising new paradigm. However, most existing symbolic networks still face certain challenges: binary nonlinear operators $\{\times, \div\}$ cannot be naturally extended to multivariate operators, and training with fixed architecture often leads to higher complexity and overfitting. In this work, we propose a Unified Symbolic Network that unifies nonlinear binary operators into nested unary operators and define the conditions under which UniSymNet can reduce complexity. Moreover, we pre-train a Transformer model with a novel label encoding method to guide structural selection, and adopt objective-specific optimization strategies to learn the parameters of the symbolic network. UniSymNet shows high fitting accuracy, excellent symbolic solution rate, and relatively low expression complexity, achieving competitive performance on low-dimensional Standard Benchmarks and high-dimensional SRBench.
ViSymRe: Vision-guided Multimodal Symbolic Regression
Dec 15, 2024Symbolic regression automatically searches for mathematical equations to reveal underlying mechanisms within datasets, offering enhanced interpretability compared to black box models. Traditionally, symbolic regression has been considered to be purely numeric-driven, with insufficient attention given to the potential contributions of visual information in augmenting this process. When dealing with high-dimensional and complex datasets, existing symbolic regression models are often inefficient and tend to generate overly complex equations, making subsequent mechanism analysis complicated. In this paper, we propose the vision-guided multimodal symbolic regression model, called ViSymRe, that systematically explores how visual information can improve various metrics of symbolic regression. Compared to traditional models, our proposed model has the following innovations: (1) It integrates three modalities: vision, symbol and numeric to enhance symbolic regression, enabling the model to benefit from the strengths of each modality; (2) It establishes a meta-learning framework that can learn from historical experiences to efficiently solve new symbolic regression problems; (3) It emphasizes the simplicity and structural rationality of the equations rather than merely numerical fitting. Extensive experiments show that our proposed model exhibits strong generalization capability and noise resistance. The equations it generates outperform state-of-the-art numeric-only baselines in terms of fitting effect, simplicity and structural accuracy, thus being able to facilitate accurate mechanism analysis and the development of theoretical models.
A New Adaptive Balanced Augmented Lagrangian Method with Application to ISAC Beamforming Design
Oct 20, 2024
In this paper, we consider a class of convex programming problems with linear equality constraints, which finds broad applications in machine learning and signal processing. We propose a new adaptive balanced augmented Lagrangian (ABAL) method for solving these problems. The proposed ABAL method adaptively selects the stepsize parameter and enjoys a low per-iteration complexity, involving only the computation of a proximal mapping of the objective function and the solution of a linear equation. These features make the proposed method well-suited to large-scale problems. We then custom-apply the ABAL method to solve the ISAC beamforming design problem, which is formulated as a nonlinear semidefinite program in a previous work. This customized application requires careful exploitation of the problem's special structure such as the property that all of its signal-to-interference-and-noise-ratio (SINR) constraints hold with equality at the solution and an efficient computation of the proximal mapping of the objective function. Simulation results demonstrate the efficiency of the proposed ABAL method.
A semantic hierarchical graph neural network for text classification
Sep 15, 2022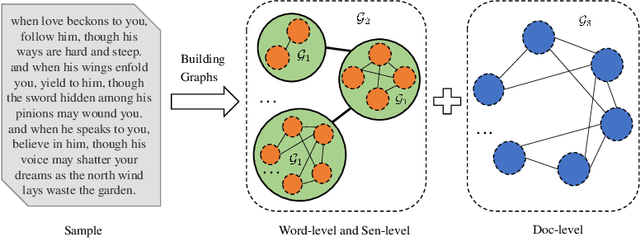
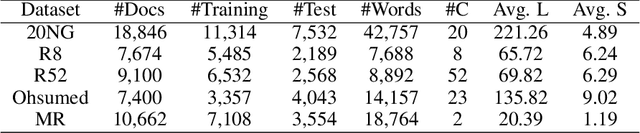

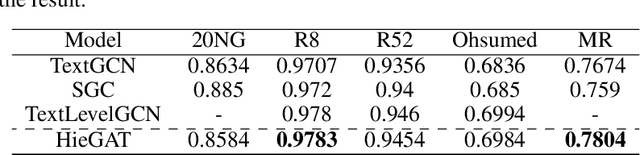
The key to the text classification task is language representation and important information extraction, and there are many related studies. In recent years, the research on graph neural network (GNN) in text classification has gradually emerged and shown its advantages, but the existing models mainly focus on directly inputting words as graph nodes into the GNN models ignoring the different levels of semantic structure information in the samples. To address the issue, we propose a new hierarchical graph neural network (HieGNN) which extracts corresponding information from word-level, sentence-level and document-level respectively. Experimental results on several benchmark datasets achieve better or similar results compared to several baseline methods, which demonstrate that our model is able to obtain more useful information for classification from samples.
Hotel2vec: Learning Attribute-Aware Hotel Embeddings with Self-Supervision
Sep 30, 2019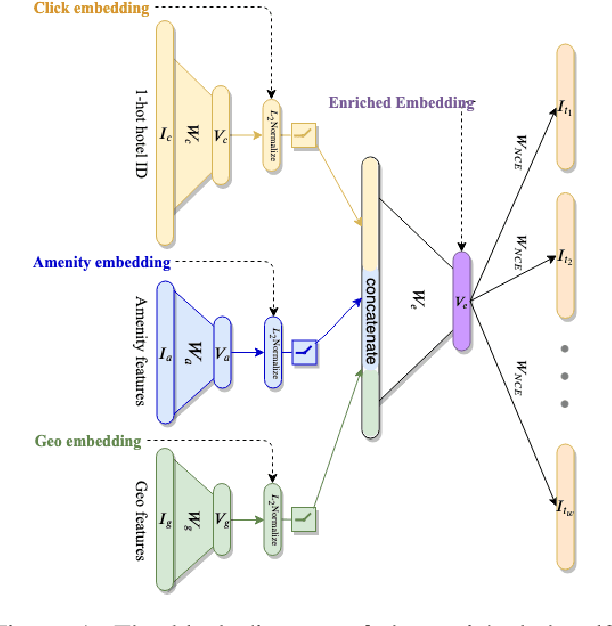
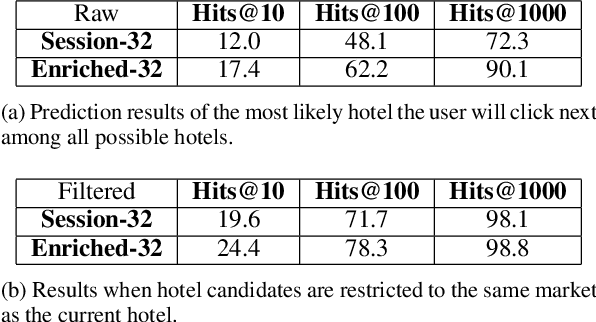

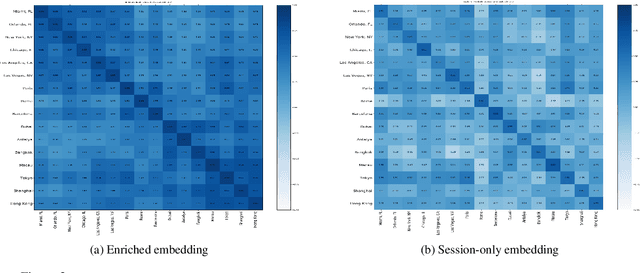
We propose a neural network architecture for learning vector representations of hotels. Unlike previous works, which typically only use user click information for learning item embeddings, we propose a framework that combines several sources of data, including user clicks, hotel attributes (e.g., property type, star rating, average user rating), amenity information (e.g., the hotel has free Wi-Fi or free breakfast), and geographic information. During model training, a joint embedding is learned from all of the above information. We show that including structured attributes about hotels enables us to make better predictions in a downstream task than when we rely exclusively on click data. We train our embedding model on more than 40 million user click sessions from a leading online travel platform and learn embeddings for more than one million hotels. Our final learned embeddings integrate distinct sub-embeddings for user clicks, hotel attributes, and geographic information, providing an interpretable representation that can be used flexibly depending on the application. We show empirically that our model generates high-quality representations that boost the performance of a hotel recommendation system in addition to other applications. An important advantage of the proposed neural model is that it addresses the cold-start problem for hotels with insufficient historical click information by incorporating additional hotel attributes which are available for all hotels.
Efficient Super Resolution For Large-Scale Images Using Attentional GAN
Jan 13, 2019

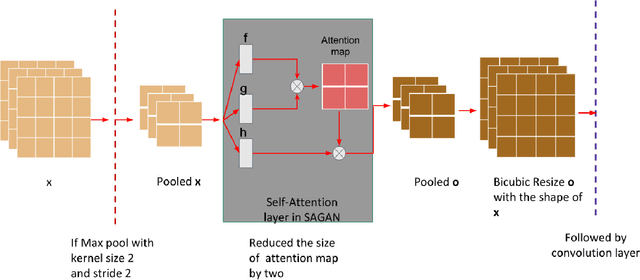
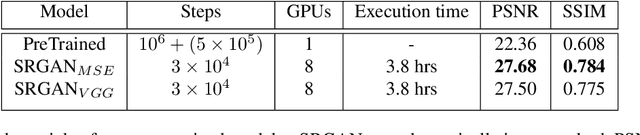
Single Image Super Resolution (SISR) is a well-researched problem with broad commercial relevance. However, most of the SISR literature focuses on small-size images under 500px, whereas business needs can mandate the generation of very high resolution images. At Expedia Group, we were tasked with generating images of at least 2000px for display on the website, four times greater than the sizes typically reported in the literature. This requirement poses a challenge that state-of-the-art models, validated on small images, have not been proven to handle. In this paper, we investigate solutions to the problem of generating high-quality images for large-scale super resolution in a commercial setting. We find that training a generative adversarial network (GAN) with attention from scratch using a large-scale lodging image data set generates images with high PSNR and SSIM scores. We describe a novel attentional SISR model for large-scale images, A-SRGAN, that uses a Flexible Self Attention layer to enable processing of large-scale images. We also describe a distributed algorithm which speeds up training by around a factor of five.