 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA New Adaptive Balanced Augmented Lagrangian Method with Application to ISAC Beamforming Design
Oct 20, 2024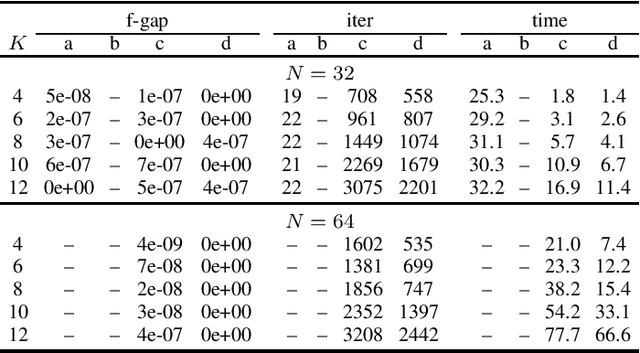
In this paper, we consider a class of convex programming problems with linear equality constraints, which finds broad applications in machine learning and signal processing. We propose a new adaptive balanced augmented Lagrangian (ABAL) method for solving these problems. The proposed ABAL method adaptively selects the stepsize parameter and enjoys a low per-iteration complexity, involving only the computation of a proximal mapping of the objective function and the solution of a linear equation. These features make the proposed method well-suited to large-scale problems. We then custom-apply the ABAL method to solve the ISAC beamforming design problem, which is formulated as a nonlinear semidefinite program in a previous work. This customized application requires careful exploitation of the problem's special structure such as the property that all of its signal-to-interference-and-noise-ratio (SINR) constraints hold with equality at the solution and an efficient computation of the proximal mapping of the objective function. Simulation results demonstrate the efficiency of the proposed ABAL method.
Interference Management in MIMO-ISAC Systems: A Transceiver Design Approach
Jul 07, 2024
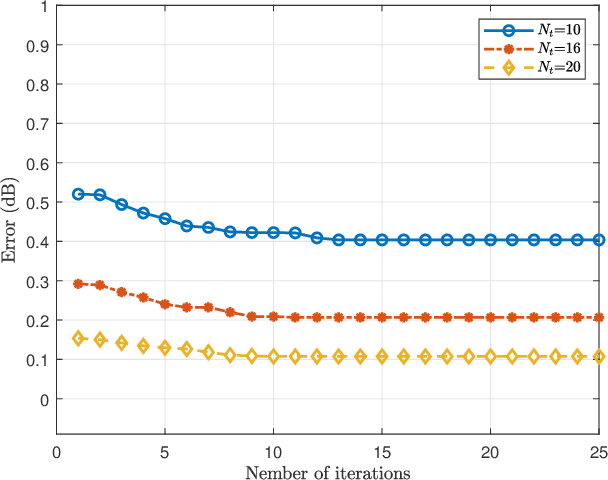
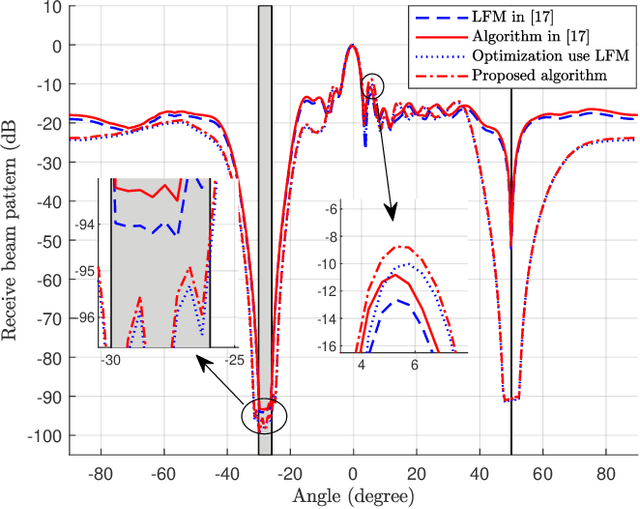
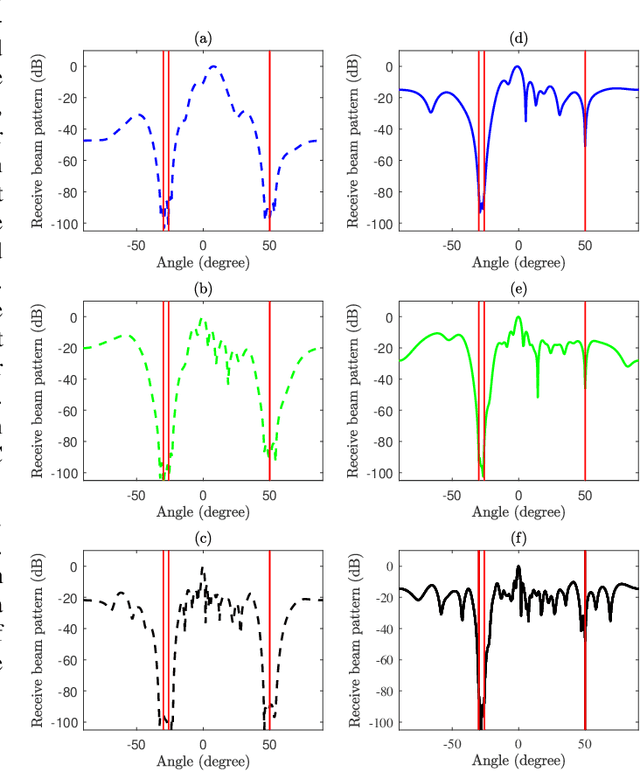
The integrated sensing and communication (ISAC) system under multi-input multi-output (MIMO) architecture achieves dual functionalities of sensing and communication on the same platform by utilizing spatial gain, which provides a feasible paradigm facing spectrum congestion. However, the dual functionalities of sensing and communication operating simultaneously in the same platform bring severe interference in the ISAC systems. Facing this challenge, we propose a joint optimization framework for transmit beamforming and receive filter design for ISAC systems with MIMO architecture. We aim to maximize the signal-to-clutter-plus-noise ratio (SCNR) at the receiver while considering various constraints such as waveform similarity, power budget, and communication performance requirements to ensure the integration of the dual functionalities. In particular, the overall transmit beamforming is refined into sensing beamforming and communication beamforming, and a quadratic transformation (QT) is introduced to relax and convert the complex non-convex optimization objective. An efficient algorithm based on covariance matrix tapers (CMT) is proposed to restructure the clutter covariance matrix considering the mismatched steering vector, thereby improving the robustness of the ISAC transceiver design. Numerical simulations are provided to demonstrate the effectiveness of the proposed algorithm.
Debiasing Stance Detection Models with Counterfactual Reasoning and Adversarial Bias Learning
Dec 20, 2022Stance detection models may tend to rely on dataset bias in the text part as a shortcut and thus fail to sufficiently learn the interaction between the targets and texts. Recent debiasing methods usually treated features learned by small models or big models at earlier steps as bias features and proposed to exclude the branch learning those bias features during inference. However, most of these methods fail to disentangle the ``good'' stance features and ``bad'' bias features in the text part. In this paper, we investigate how to mitigate dataset bias in stance detection. Motivated by causal effects, we leverage a novel counterfactual inference framework, which enables us to capture the dataset bias in the text part as the direct causal effect of the text on stances and reduce the dataset bias in the text part by subtracting the direct text effect from the total causal effect. We novelly model bias features as features that correlate with the stance labels but fail on intermediate stance reasoning subtasks and propose an adversarial bias learning module to model the bias more accurately. To verify whether our model could better model the interaction between texts and targets, we test our model on recently proposed test sets to evaluate the understanding of the task from various aspects. Experiments demonstrate that our proposed method (1) could better model the bias features, and (2) outperforms existing debiasing baselines on both the original dataset and most of the newly constructed test sets.
Zero-shot Aspect-level Sentiment Classification via Explicit Utilization of Aspect-to-Document Sentiment Composition
Sep 06, 2022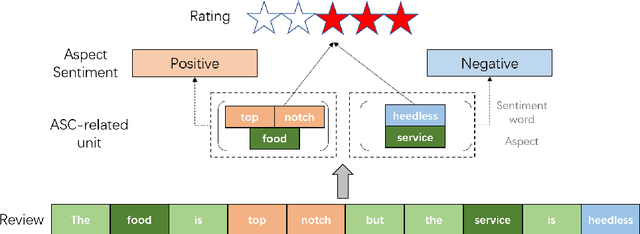
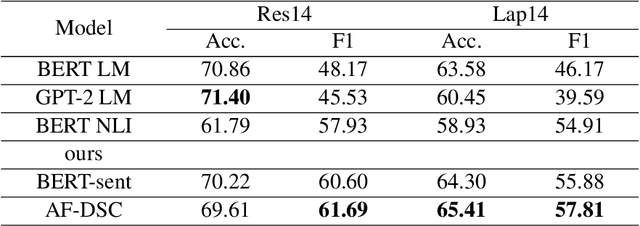
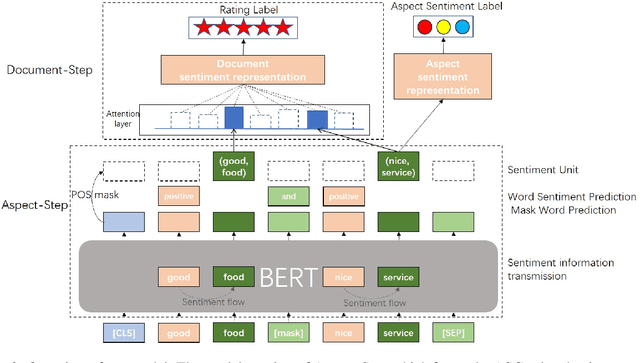
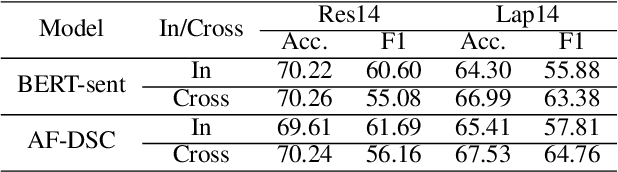
As aspect-level sentiment labels are expensive and labor-intensive to acquire, zero-shot aspect-level sentiment classification is proposed to learn classifiers applicable to new domains without using any annotated aspect-level data. In contrast, document-level sentiment data with ratings are more easily accessible. In this work, we achieve zero-shot aspect-level sentiment classification by only using document-level reviews. Our key intuition is that the sentiment representation of a document is composed of the sentiment representations of all the aspects of that document. Based on this, we propose the AF-DSC method to explicitly model such sentiment composition in reviews. AF-DSC first learns sentiment representations for all potential aspects and then aggregates aspect-level sentiments into a document-level one to perform document-level sentiment classification. In this way, we obtain the aspect-level sentiment classifier as the by-product of the document-level sentiment classifier. Experimental results on aspect-level sentiment classification benchmarks demonstrate the effectiveness of explicit utilization of sentiment composition in document-level sentiment classification. Our model with only 30k training data outperforms previous work utilizing millions of data.
Learning to Share by Masking the Non-shared for Multi-domain Sentiment Classification
Apr 17, 2021
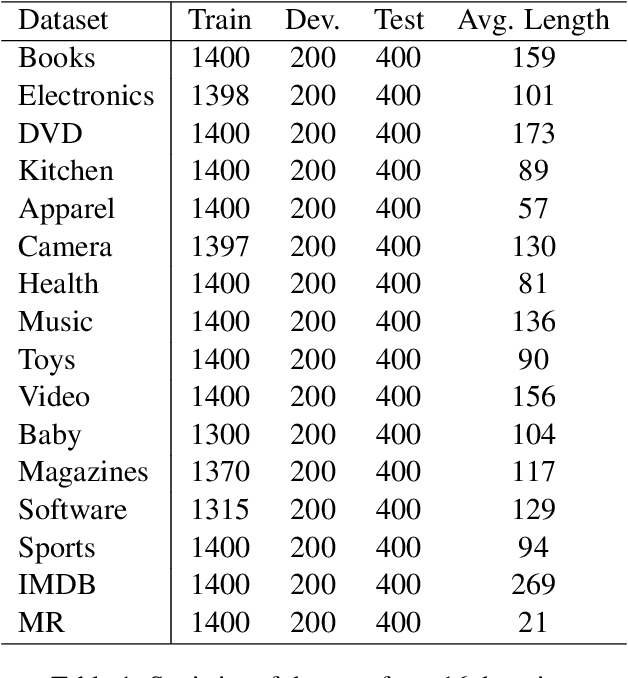
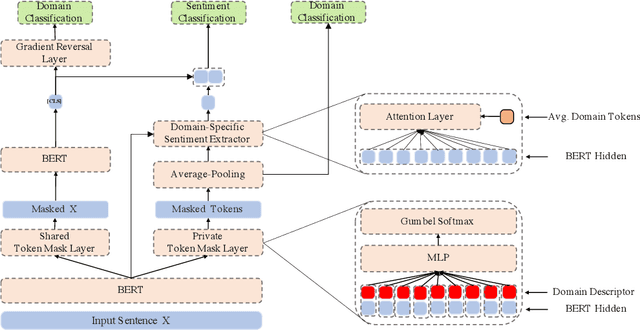
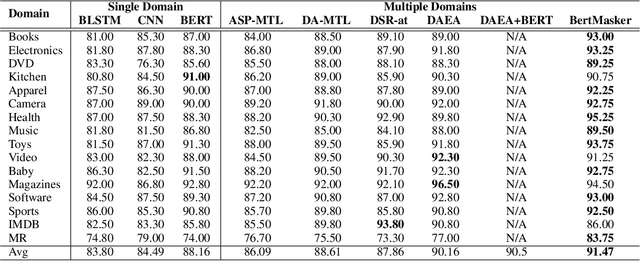
Multi-domain sentiment classification deals with the scenario where labeled data exists for multiple domains but insufficient for training effective sentiment classifiers that work across domains. Thus, fully exploiting sentiment knowledge shared across domains is crucial for real world applications. While many existing works try to extract domain-invariant features in high-dimensional space, such models fail to explicitly distinguish between shared and private features at text-level, which to some extent lacks interpretablity. Based on the assumption that removing domain-related tokens from texts would help improve their domain-invariance, we instead first transform original sentences to be domain-agnostic. To this end, we propose the BertMasker network which explicitly masks domain-related words from texts, learns domain-invariant sentiment features from these domain-agnostic texts, and uses those masked words to form domain-aware sentence representations. Empirical experiments on a well-adopted multiple domain sentiment classification dataset demonstrate the effectiveness of our proposed model on both multi-domain sentiment classification and cross-domain settings, by increasing the accuracy by 0.94% and 1.8% respectively. Further analysis on masking proves that removing those domain-related and sentiment irrelevant tokens decreases texts' domain distinction, resulting in the performance degradation of a BERT-based domain classifier by over 12%.