 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Share by Masking the Non-shared for Multi-domain Sentiment Classification
Paper and Code

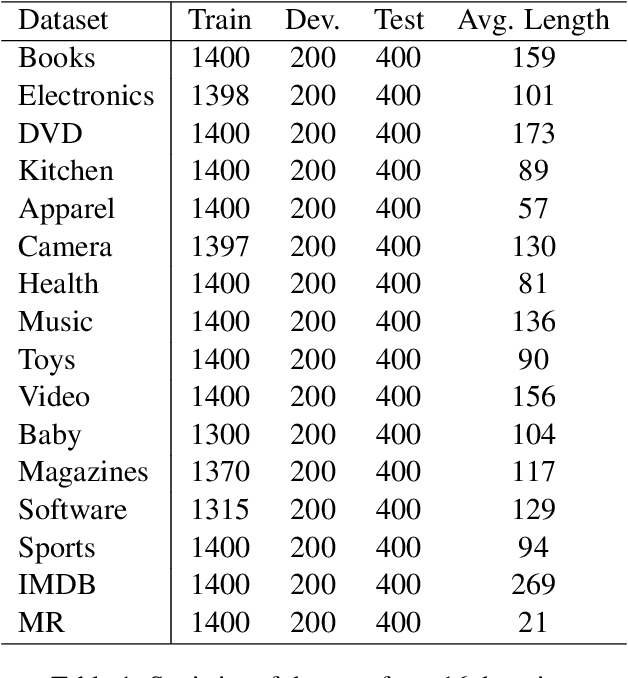
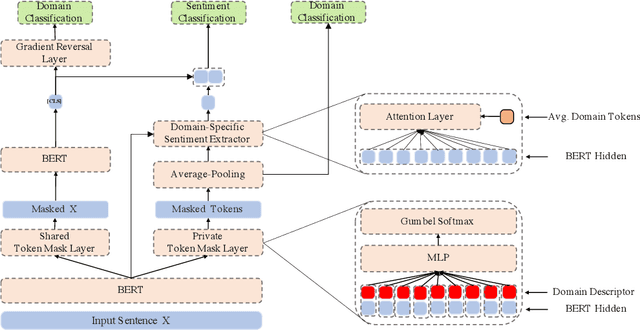
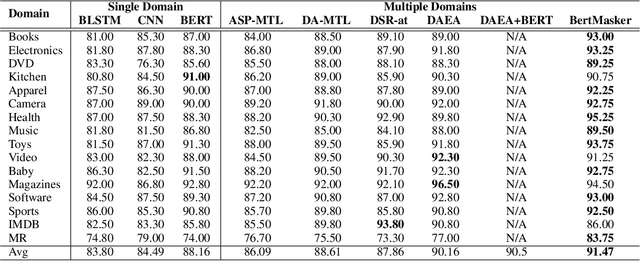
Multi-domain sentiment classification deals with the scenario where labeled data exists for multiple domains but insufficient for training effective sentiment classifiers that work across domains. Thus, fully exploiting sentiment knowledge shared across domains is crucial for real world applications. While many existing works try to extract domain-invariant features in high-dimensional space, such models fail to explicitly distinguish between shared and private features at text-level, which to some extent lacks interpretablity. Based on the assumption that removing domain-related tokens from texts would help improve their domain-invariance, we instead first transform original sentences to be domain-agnostic. To this end, we propose the BertMasker network which explicitly masks domain-related words from texts, learns domain-invariant sentiment features from these domain-agnostic texts, and uses those masked words to form domain-aware sentence representations. Empirical experiments on a well-adopted multiple domain sentiment classification dataset demonstrate the effectiveness of our proposed model on both multi-domain sentiment classification and cross-domain settings, by increasing the accuracy by 0.94% and 1.8% respectively. Further analysis on masking proves that removing those domain-related and sentiment irrelevant tokens decreases texts' domain distinction, resulting in the performance degradation of a BERT-based domain classifier by over 12%.