 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAligning Hotel Embeddings using Domain Adaptation for Next-Item Recommendation
Aug 31, 2021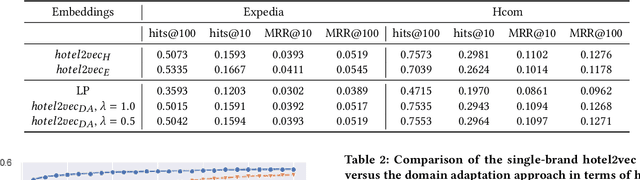

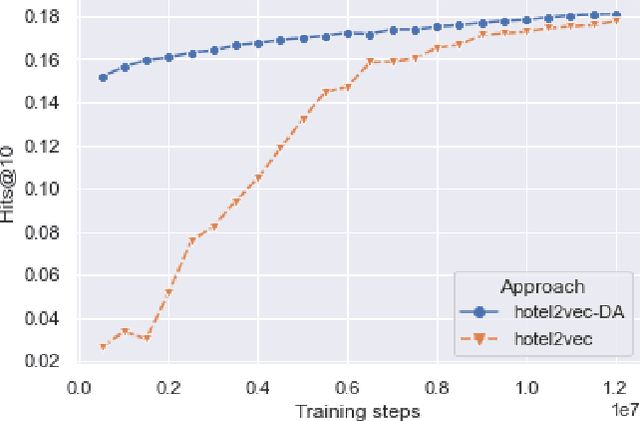
In online platforms it is often the case to have multiple brands under the same group which may target different customer profiles, or have different domains. For example, in the hospitality domain, Expedia Group has multiple brands like Brand Expedia, Hotels.com and Wotif which have either different traveler profiles or are more relevant in a local context. In this context, learning embeddings for hotels that can be leveraged in recommendation tasks in multiple brands requires to have a common embedding that can be induced using alignment approaches. In the same time, one needs to ensure that this common embedding space does not degrade the performance in any of the brands. In this work we build upon the hotel2vec model and propose a simple regularization approach for aligning hotel embeddings of different brands via domain adaptation. We also explore alignment methods previously used in cross-lingual embeddings to align spaces of different languages. We present results on the task of next-hotel prediction using click sessions from two brands. The results show that the proposed approach can align the two embedding spaces while achieving good performance in both brands. Additionally, with respect to single-brand training we show that the proposed approach can significantly reduce training time and improve the predictive performance.
Wasserstein distances for evaluating cross-lingual embeddings
Nov 11, 2019
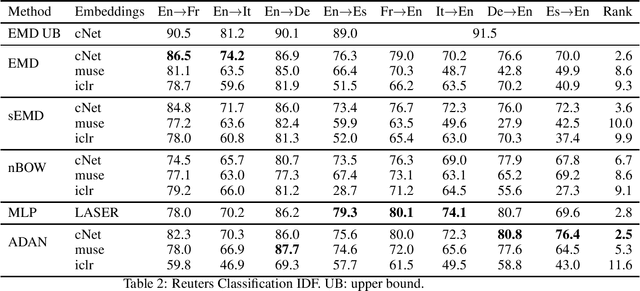
Word embeddings are high dimensional vector representations of words that capture their semantic similarity in the vector space. There exist several algorithms for learning such embeddings both for a single language as well as for several languages jointly. In this work we propose to evaluate collections of embeddings by adapting downstream natural language tasks to the optimal transport framework. We show how the family of Wasserstein distances can be used to solve cross-lingual document retrieval and the cross-lingual document classification problems. We argue on the advantages of this approach compared to more traditional evaluation methods of embeddings like bilingual lexical induction. Our experimental results suggest that using Wasserstein distances on these problems out-performs several strong baselines and performs on par with state-of-the-art models.
Hotel2vec: Learning Attribute-Aware Hotel Embeddings with Self-Supervision
Sep 30, 2019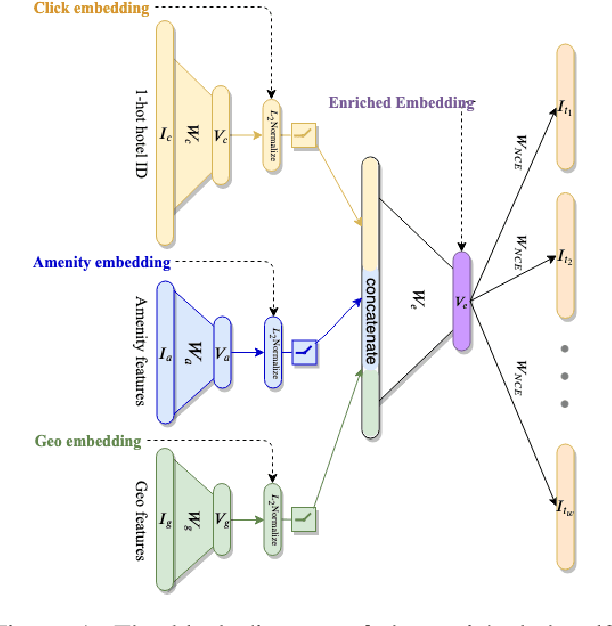
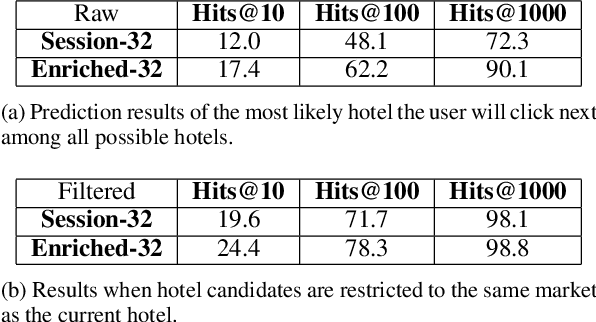

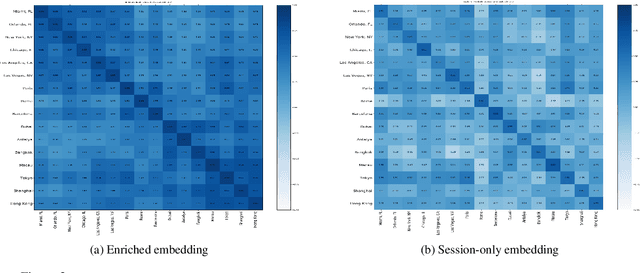
We propose a neural network architecture for learning vector representations of hotels. Unlike previous works, which typically only use user click information for learning item embeddings, we propose a framework that combines several sources of data, including user clicks, hotel attributes (e.g., property type, star rating, average user rating), amenity information (e.g., the hotel has free Wi-Fi or free breakfast), and geographic information. During model training, a joint embedding is learned from all of the above information. We show that including structured attributes about hotels enables us to make better predictions in a downstream task than when we rely exclusively on click data. We train our embedding model on more than 40 million user click sessions from a leading online travel platform and learn embeddings for more than one million hotels. Our final learned embeddings integrate distinct sub-embeddings for user clicks, hotel attributes, and geographic information, providing an interpretable representation that can be used flexibly depending on the application. We show empirically that our model generates high-quality representations that boost the performance of a hotel recommendation system in addition to other applications. An important advantage of the proposed neural model is that it addresses the cold-start problem for hotels with insufficient historical click information by incorporating additional hotel attributes which are available for all hotels.
On the effectiveness of feature set augmentation using clusters of word embeddings
Jul 30, 2018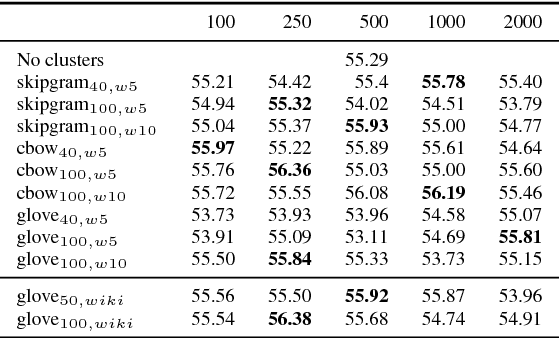
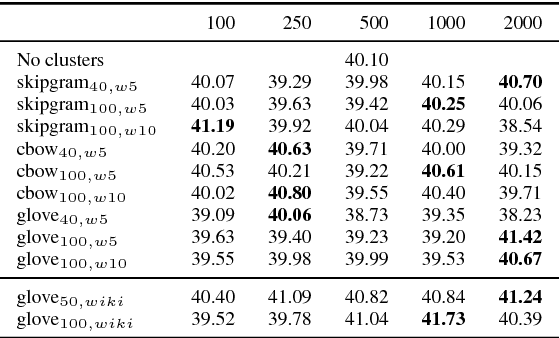
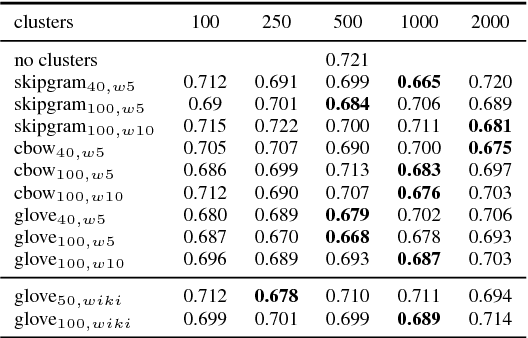

Word clusters have been empirically shown to offer important performance improvements on various tasks. Despite their importance, their incorporation in the standard pipeline of feature engineering relies more on a trial-and-error procedure where one evaluates several hyper-parameters, like the number of clusters to be used. In order to better understand the role of such features we systematically evaluate their effect on four tasks, those of named entity segmentation and classification as well as, those of five-point sentiment classification and quantification. Our results strongly suggest that cluster membership features improve the performance.
Aggressive Sampling for Multi-class to Binary Reduction with Applications to Text Classification
Sep 14, 2017
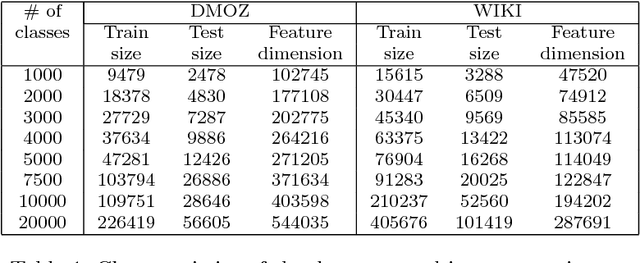

We address the problem of multi-class classification in the case where the number of classes is very large. We propose a double sampling strategy on top of a multi-class to binary reduction strategy, which transforms the original multi-class problem into a binary classification problem over pairs of examples. The aim of the sampling strategy is to overcome the curse of long-tailed class distributions exhibited in majority of large-scale multi-class classification problems and to reduce the number of pairs of examples in the expanded data. We show that this strategy does not alter the consistency of the empirical risk minimization principle defined over the double sample reduction. Experiments are carried out on DMOZ and Wikipedia collections with 10,000 to 100,000 classes where we show the efficiency of the proposed approach in terms of training and prediction time, memory consumption, and predictive performance with respect to state-of-the-art approaches.
CAp 2017 challenge: Twitter Named Entity Recognition
Jul 24, 2017
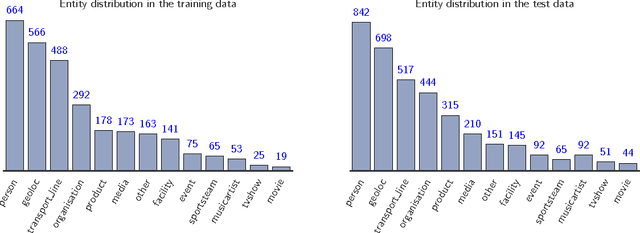
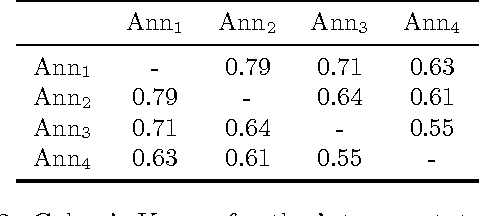
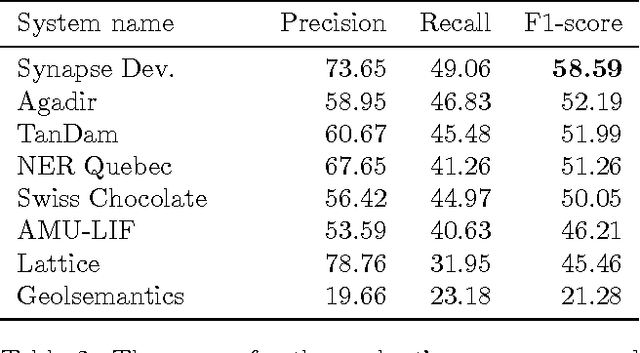
The paper describes the CAp 2017 challenge. The challenge concerns the problem of Named Entity Recognition (NER) for tweets written in French. We first present the data preparation steps we followed for constructing the dataset released in the framework of the challenge. We begin by demonstrating why NER for tweets is a challenging problem especially when the number of entities increases. We detail the annotation process and the necessary decisions we made. We provide statistics on the inter-annotator agreement, and we conclude the data description part with examples and statistics for the data. We, then, describe the participation in the challenge, where 8 teams participated, with a focus on the methods employed by the challenge participants and the scores achieved in terms of F$_1$ measure. Importantly, the constructed dataset comprising $\sim$6,000 tweets annotated for 13 types of entities, which to the best of our knowledge is the first such dataset in French, is publicly available at \url{http://cap2017.imag.fr/competition.html} .
e-Commerce product classification: our participation at cDiscount 2015 challenge
Jun 09, 2016

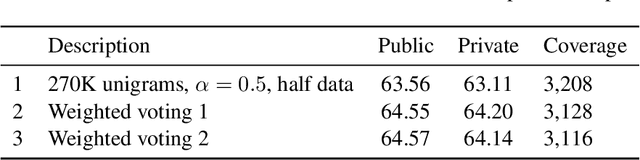
This report describes our participation in the cDiscount 2015 challenge where the goal was to classify product items in a predefined taxonomy of products. Our best submission yielded an accuracy score of 64.20\% in the private part of the leaderboard and we were ranked 10th out of 175 participating teams. We followed a text classification approach employing mainly linear models. The final solution was a weighted voting system which combined a variety of trained models.
LSHTC: A Benchmark for Large-Scale Text Classification
Mar 30, 2015
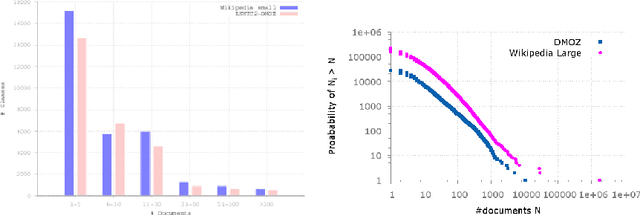
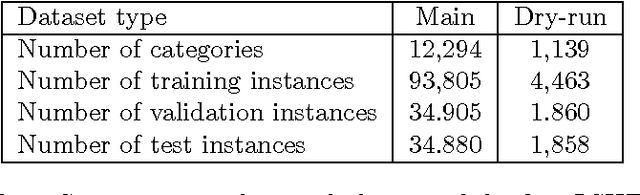
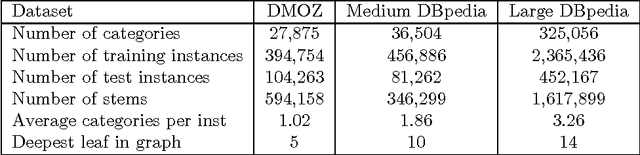
LSHTC is a series of challenges which aims to assess the performance of classification systems in large-scale classification in a a large number of classes (up to hundreds of thousands). This paper describes the dataset that have been released along the LSHTC series. The paper details the construction of the datsets and the design of the tracks as well as the evaluation measures that we implemented and a quick overview of the results. All of these datasets are available online and runs may still be submitted on the online server of the challenges.
Evaluation Measures for Hierarchical Classification: a unified view and novel approaches
Jul 01, 2013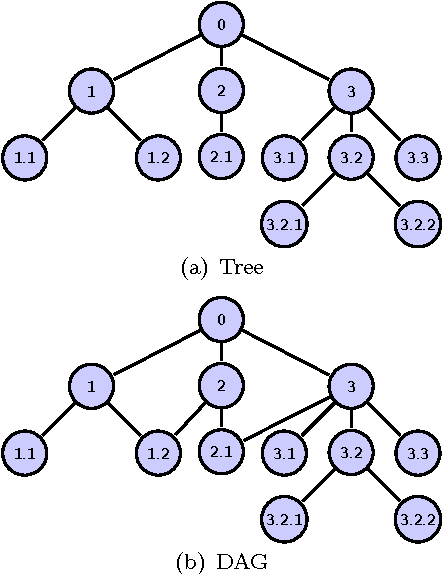

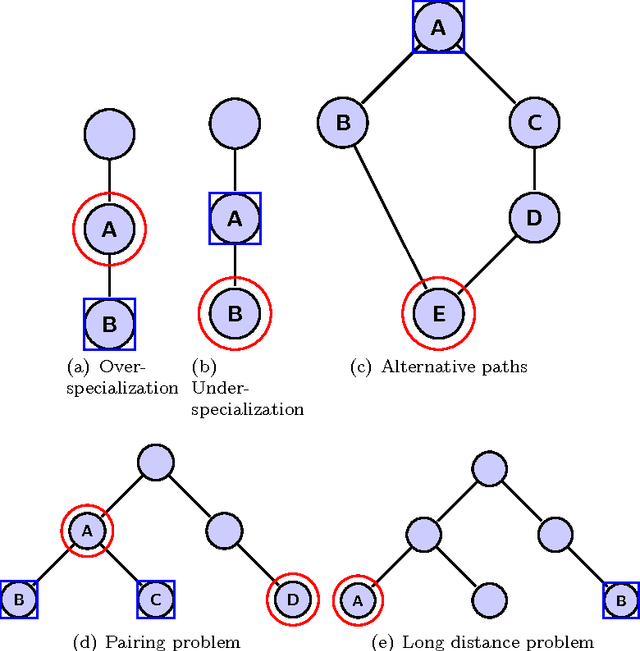
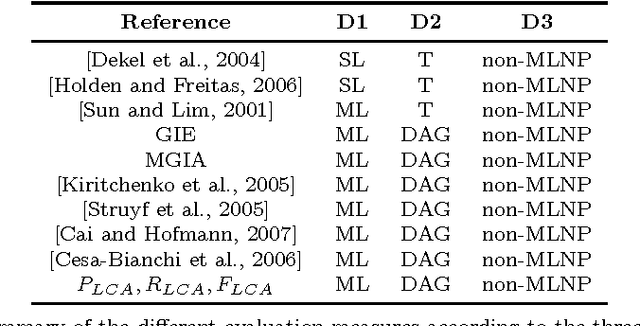
Hierarchical classification addresses the problem of classifying items into a hierarchy of classes. An important issue in hierarchical classification is the evaluation of different classification algorithms, which is complicated by the hierarchical relations among the classes. Several evaluation measures have been proposed for hierarchical classification using the hierarchy in different ways. This paper studies the problem of evaluation in hierarchical classification by analyzing and abstracting the key components of the existing performance measures. It also proposes two alternative generic views of hierarchical evaluation and introduces two corresponding novel measures. The proposed measures, along with the state-of-the art ones, are empirically tested on three large datasets from the domain of text classification. The empirical results illustrate the undesirable behavior of existing approaches and how the proposed methods overcome most of these methods across a range of cases.