 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReassessing Graph Linearization for Sequence-to-sequence AMR Parsing: On the Advantages and Limitations of Triple-Based Encoding
May 13, 2025Sequence-to-sequence models are widely used to train Abstract Meaning Representation (Banarescu et al., 2013, AMR) parsers. To train such models, AMR graphs have to be linearized into a one-line text format. While Penman encoding is typically used for this purpose, we argue that it has limitations: (1) for deep graphs, some closely related nodes are located far apart in the linearized text (2) Penman's tree-based encoding necessitates inverse roles to handle node re-entrancy, doubling the number of relation types to predict. To address these issues, we propose a triple-based linearization method and compare its efficiency with Penman linearization. Although triples are well suited to represent a graph, our results suggest room for improvement in triple encoding to better compete with Penman's concise and explicit representation of a nested graph structure.
Should Cross-Lingual AMR Parsing go Meta? An Empirical Assessment of Meta-Learning and Joint Learning AMR Parsing
Oct 04, 2024Cross-lingual AMR parsing is the task of predicting AMR graphs in a target language when training data is available only in a source language. Due to the small size of AMR training data and evaluation data, cross-lingual AMR parsing has only been explored in a small set of languages such as English, Spanish, German, Chinese, and Italian. Taking inspiration from Langedijk et al. (2022), who apply meta-learning to tackle cross-lingual syntactic parsing, we investigate the use of meta-learning for cross-lingual AMR parsing. We evaluate our models in $k$-shot scenarios (including 0-shot) and assess their effectiveness in Croatian, Farsi, Korean, Chinese, and French. Notably, Korean and Croatian test sets are developed as part of our work, based on the existing The Little Prince English AMR corpus, and made publicly available. We empirically study our method by comparing it to classical joint learning. Our findings suggest that while the meta-learning model performs slightly better in 0-shot evaluation for certain languages, the performance gain is minimal or absent when $k$ is higher than 0.
SMILK, linking natural language and data from the web
Dec 20, 2018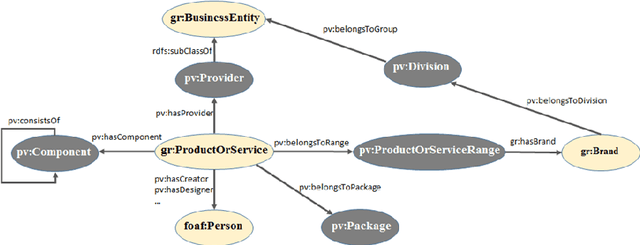
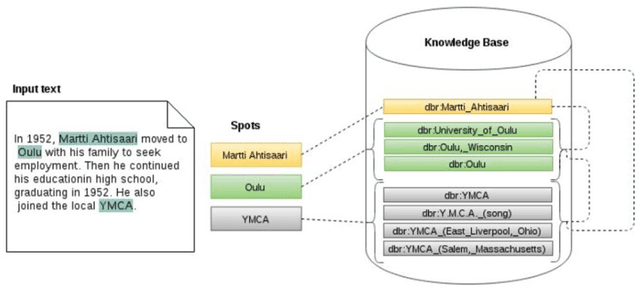
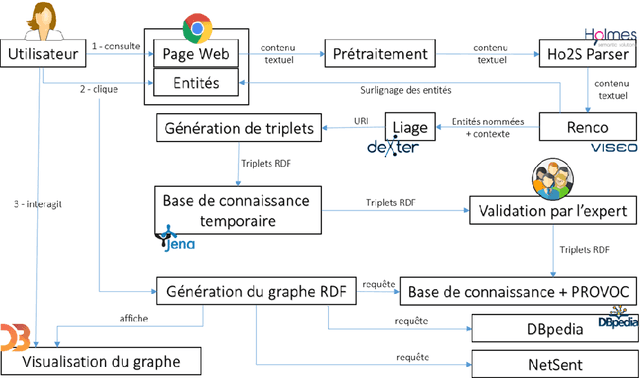
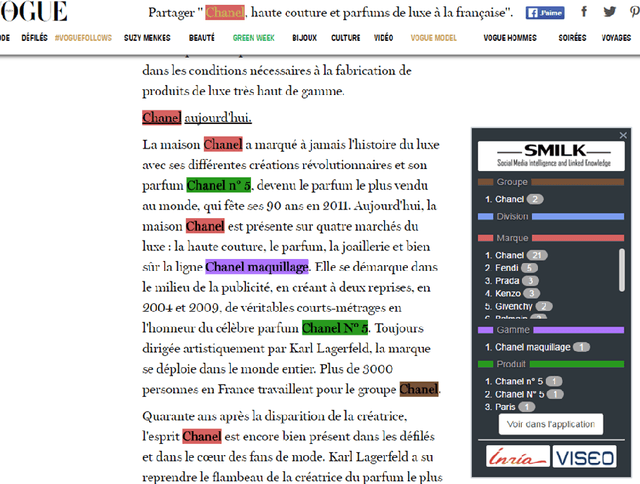
As part of the SMILK Joint Lab, we studied the use of Natural Language Processing to: (1) enrich knowledge bases and link data on the web, and conversely (2) use this linked data to contribute to the improvement of text analysis and the annotation of textual content, and to support knowledge extraction. The evaluation focused on brand-related information retrieval in the field of cosmetics. This article describes each step of our approach: the creation of ProVoc, an ontology to describe products and brands; the automatic population of a knowledge base mainly based on ProVoc from heterogeneous textual resources; and the evaluation of an application which that takes the form of a browser plugin providing additional knowledge to users browsing the web.
* in French
CAp 2017 challenge: Twitter Named Entity Recognition
Jul 24, 2017
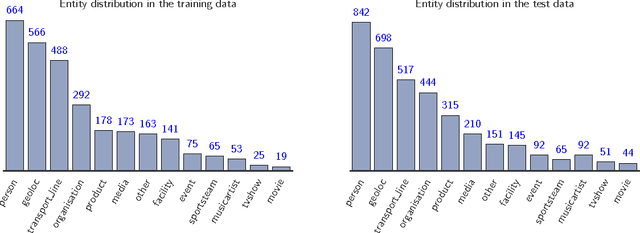
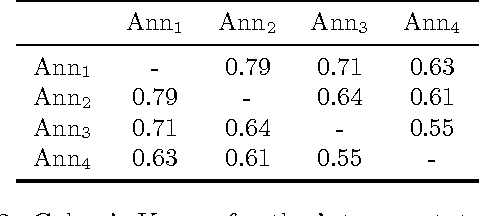
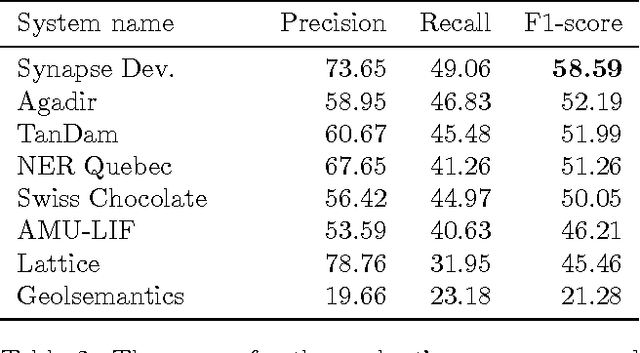
The paper describes the CAp 2017 challenge. The challenge concerns the problem of Named Entity Recognition (NER) for tweets written in French. We first present the data preparation steps we followed for constructing the dataset released in the framework of the challenge. We begin by demonstrating why NER for tweets is a challenging problem especially when the number of entities increases. We detail the annotation process and the necessary decisions we made. We provide statistics on the inter-annotator agreement, and we conclude the data description part with examples and statistics for the data. We, then, describe the participation in the challenge, where 8 teams participated, with a focus on the methods employed by the challenge participants and the scores achieved in terms of F$_1$ measure. Importantly, the constructed dataset comprising $\sim$6,000 tweets annotated for 13 types of entities, which to the best of our knowledge is the first such dataset in French, is publicly available at \url{http://cap2017.imag.fr/competition.html} .