 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBilingual Topic Models for Comparable Corpora
Nov 30, 2021

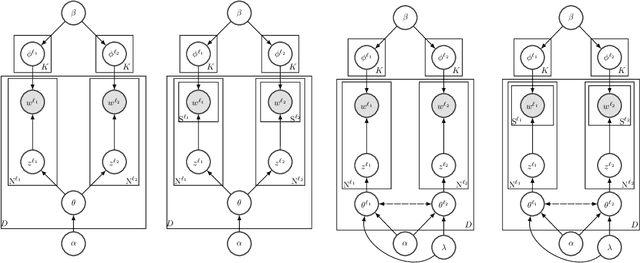
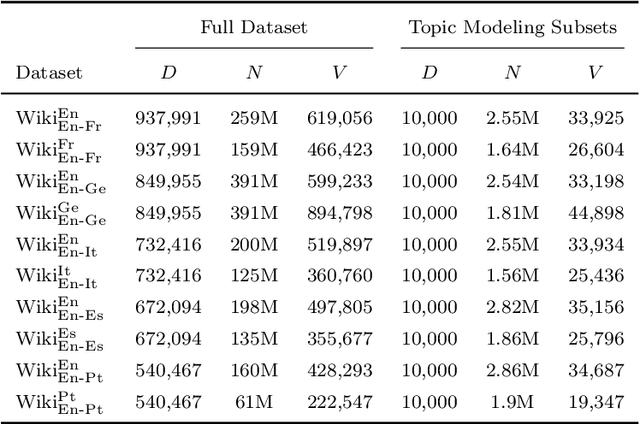
Probabilistic topic models like Latent Dirichlet Allocation (LDA) have been previously extended to the bilingual setting. A fundamental modeling assumption in several of these extensions is that the input corpora are in the form of document pairs whose constituent documents share a single topic distribution. However, this assumption is strong for comparable corpora that consist of documents thematically similar to an extent only, which are, in turn, the most commonly available or easy to obtain. In this paper we relax this assumption by proposing for the paired documents to have separate, yet bound topic distributions. % a binding mechanism between the distributions of the paired documents. We suggest that the strength of the bound should depend on each pair's semantic similarity. To estimate the similarity of documents that are written in different languages we use cross-lingual word embeddings that are learned with shallow neural networks. We evaluate the proposed binding mechanism by extending two topic models: a bilingual adaptation of LDA that assumes bag-of-words inputs and a model that incorporates part of the text structure in the form of boundaries of semantically coherent segments. To assess the performance of the novel topic models we conduct intrinsic and extrinsic experiments on five bilingual, comparable corpora of English documents with French, German, Italian, Spanish and Portuguese documents. The results demonstrate the efficiency of our approach in terms of both topic coherence measured by the normalized point-wise mutual information, and generalization performance measured by perplexity and in terms of Mean Reciprocal Rank in a cross-lingual document retrieval task for each of the language pairs.
Query Understanding for Natural Language Enterprise Search
Dec 11, 2020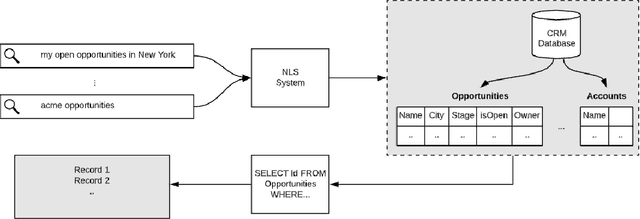
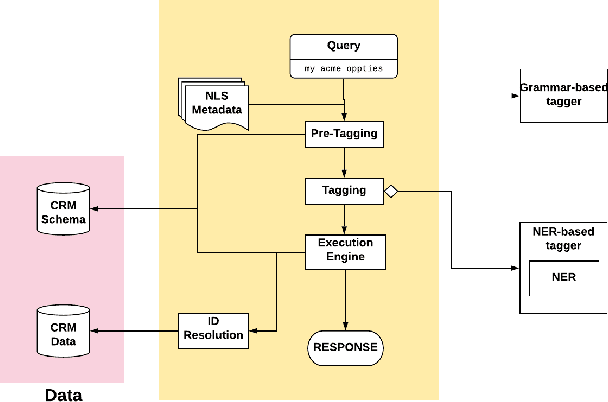

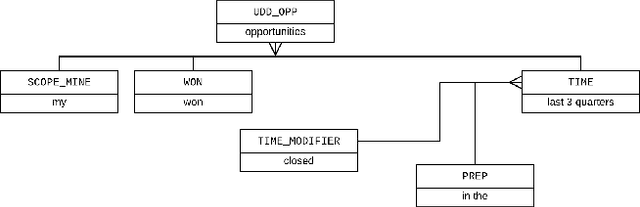
Natural Language Search (NLS) extends the capabilities of search engines that perform keyword search allowing users to issue queries in a more "natural" language. The engine tries to understand the meaning of the queries and to map the query words to the symbols it supports like Persons, Organizations, Time Expressions etc.. It, then, retrieves the information that satisfies the user's need in different forms like an answer, a record or a list of records. We present an NLS system we implemented as part of the Search service of a major CRM platform. The system is currently in production serving thousands of customers. Our user studies showed that creating dynamic reports with NLS saved more than 50% of our user's time compared to achieving the same result with navigational search. We describe the architecture of the system, the particularities of the CRM domain as well as how they have influenced our design decisions. Among several submodules of the system we detail the role of a Deep Learning Named Entity Recognizer. The paper concludes with discussion over the lessons learned while developing this product.
Wasserstein distances for evaluating cross-lingual embeddings
Nov 11, 2019
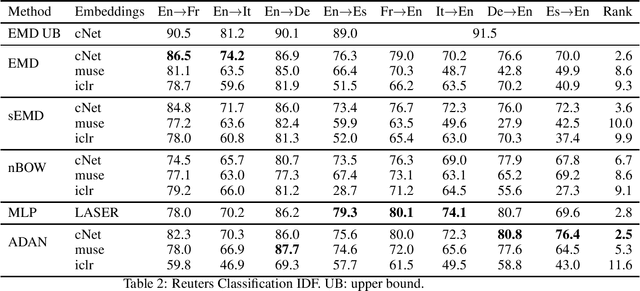
Word embeddings are high dimensional vector representations of words that capture their semantic similarity in the vector space. There exist several algorithms for learning such embeddings both for a single language as well as for several languages jointly. In this work we propose to evaluate collections of embeddings by adapting downstream natural language tasks to the optimal transport framework. We show how the family of Wasserstein distances can be used to solve cross-lingual document retrieval and the cross-lingual document classification problems. We argue on the advantages of this approach compared to more traditional evaluation methods of embeddings like bilingual lexical induction. Our experimental results suggest that using Wasserstein distances on these problems out-performs several strong baselines and performs on par with state-of-the-art models.
Lexical Bias In Essay Level Prediction
Sep 21, 2018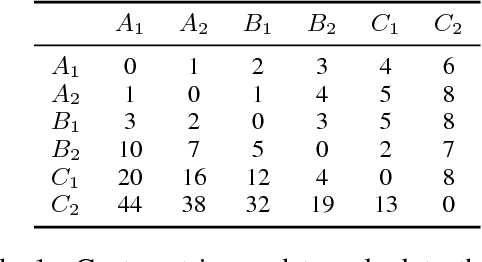
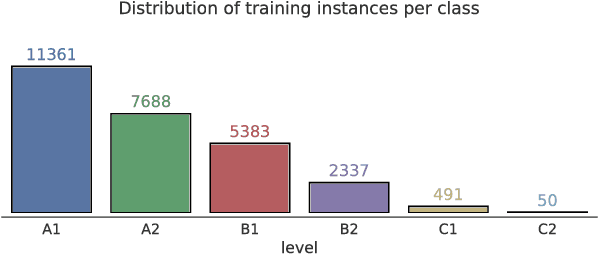
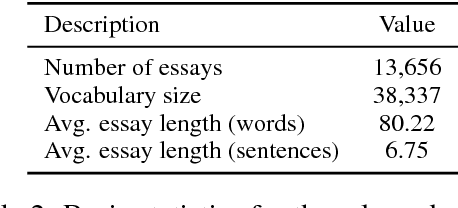
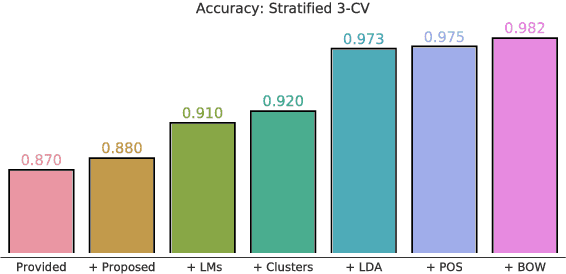
Automatically predicting the level of non-native English speakers given their written essays is an interesting machine learning problem. In this work I present the system "balikasg" that achieved the state-of-the-art performance in the CAp 2018 data science challenge among 14 systems. I detail the feature extraction, feature engineering and model selection steps and I evaluate how these decisions impact the system's performance. The paper concludes with remarks for future work.
On the effectiveness of feature set augmentation using clusters of word embeddings
Jul 30, 2018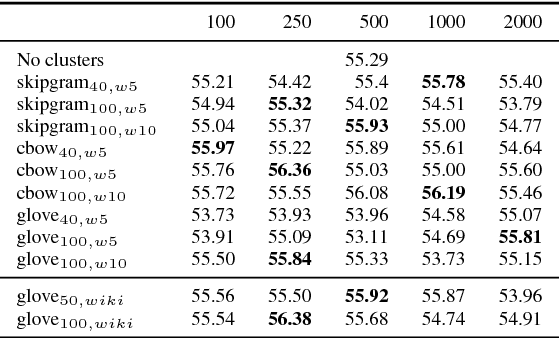
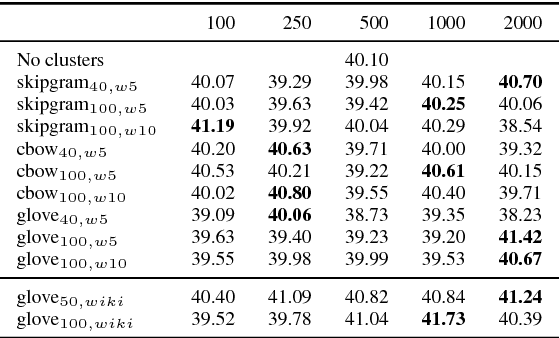
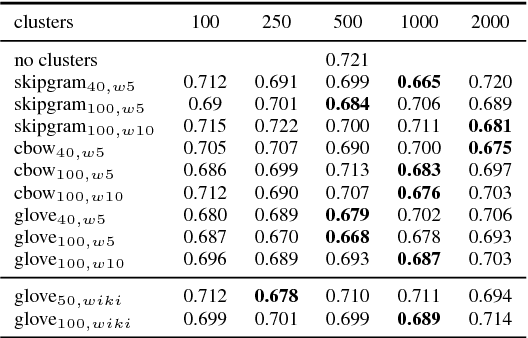

Word clusters have been empirically shown to offer important performance improvements on various tasks. Despite their importance, their incorporation in the standard pipeline of feature engineering relies more on a trial-and-error procedure where one evaluates several hyper-parameters, like the number of clusters to be used. In order to better understand the role of such features we systematically evaluate their effect on four tasks, those of named entity segmentation and classification as well as, those of five-point sentiment classification and quantification. Our results strongly suggest that cluster membership features improve the performance.
Concurrent Learning of Semantic Relations
Jul 30, 2018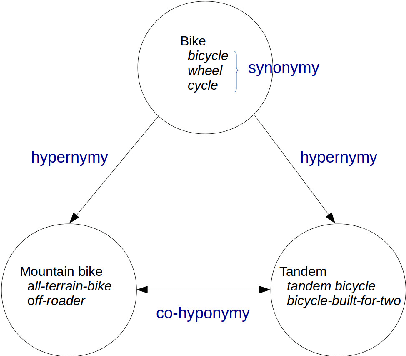

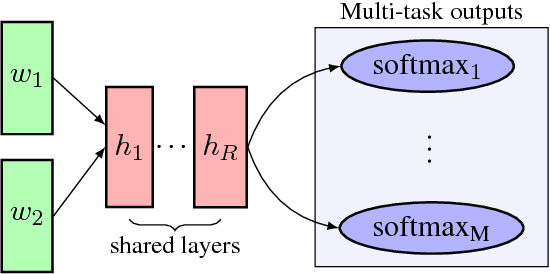
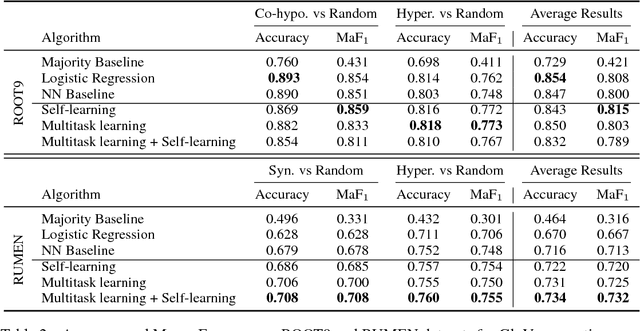
Discovering whether words are semantically related and identifying the specific semantic relation that holds between them is of crucial importance for NLP as it is essential for tasks like query expansion in IR. Within this context, different methodologies have been proposed that either exclusively focus on a single lexical relation (e.g. hypernymy vs. random) or learn specific classifiers capable of identifying multiple semantic relations (e.g. hypernymy vs. synonymy vs. random). In this paper, we propose another way to look at the problem that relies on the multi-task learning paradigm. In particular, we want to study whether the learning process of a given semantic relation (e.g. hypernymy) can be improved by the concurrent learning of another semantic relation (e.g. co-hyponymy). Within this context, we particularly examine the benefits of semi-supervised learning where the training of a prediction function is performed over few labeled data jointly with many unlabeled ones. Preliminary results based on simple learning strategies and state-of-the-art distributional feature representations show that concurrent learning can lead to improvements in a vast majority of tested situations.
Cross-lingual Document Retrieval using Regularized Wasserstein Distance
May 11, 2018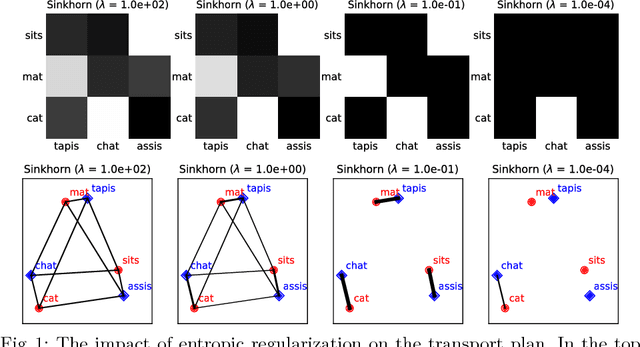
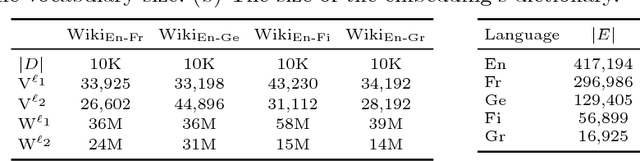
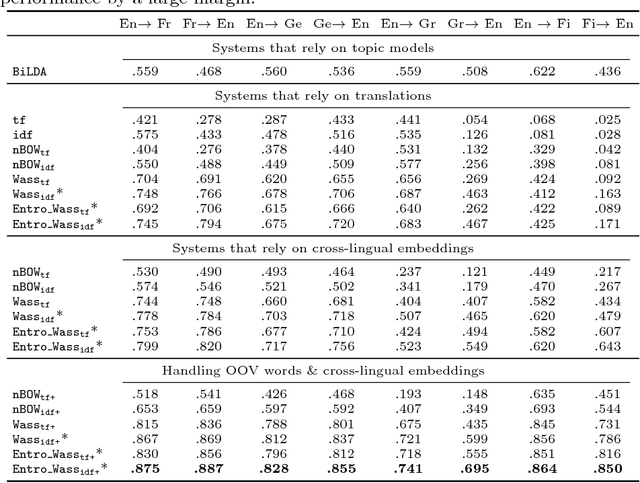
Many information retrieval algorithms rely on the notion of a good distance that allows to efficiently compare objects of different nature. Recently, a new promising metric called Word Mover's Distance was proposed to measure the divergence between text passages. In this paper, we demonstrate that this metric can be extended to incorporate term-weighting schemes and provide more accurate and computationally efficient matching between documents using entropic regularization. We evaluate the benefits of both extensions in the task of cross-lingual document retrieval (CLDR). Our experimental results on eight CLDR problems suggest that the proposed methods achieve remarkable improvements in terms of Mean Reciprocal Rank compared to several baselines.
CAp 2017 challenge: Twitter Named Entity Recognition
Jul 24, 2017
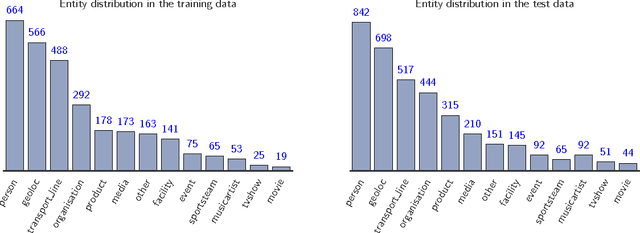
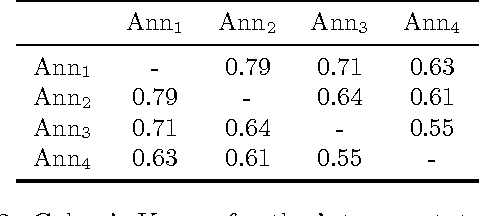
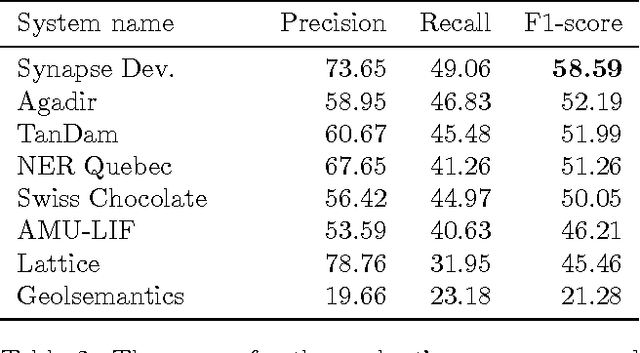
The paper describes the CAp 2017 challenge. The challenge concerns the problem of Named Entity Recognition (NER) for tweets written in French. We first present the data preparation steps we followed for constructing the dataset released in the framework of the challenge. We begin by demonstrating why NER for tweets is a challenging problem especially when the number of entities increases. We detail the annotation process and the necessary decisions we made. We provide statistics on the inter-annotator agreement, and we conclude the data description part with examples and statistics for the data. We, then, describe the participation in the challenge, where 8 teams participated, with a focus on the methods employed by the challenge participants and the scores achieved in terms of F$_1$ measure. Importantly, the constructed dataset comprising $\sim$6,000 tweets annotated for 13 types of entities, which to the best of our knowledge is the first such dataset in French, is publicly available at \url{http://cap2017.imag.fr/competition.html} .
Multitask Learning for Fine-Grained Twitter Sentiment Analysis
Jul 12, 2017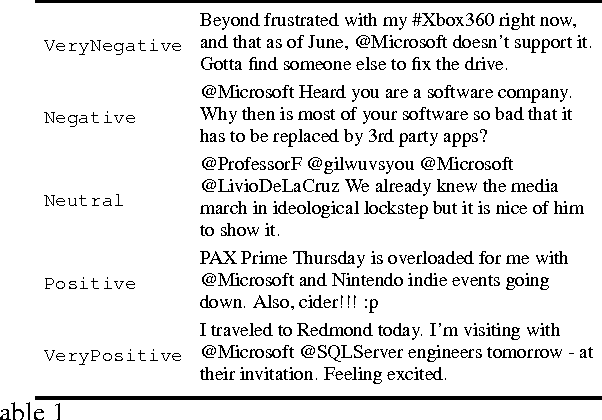
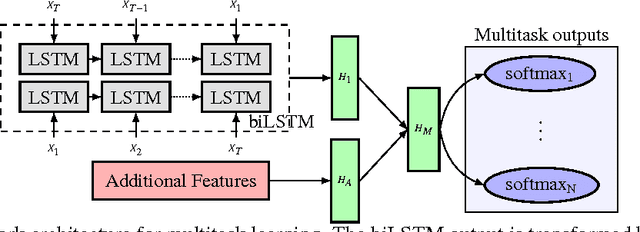
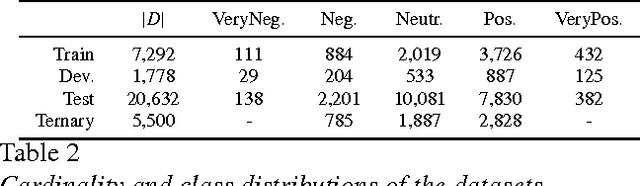
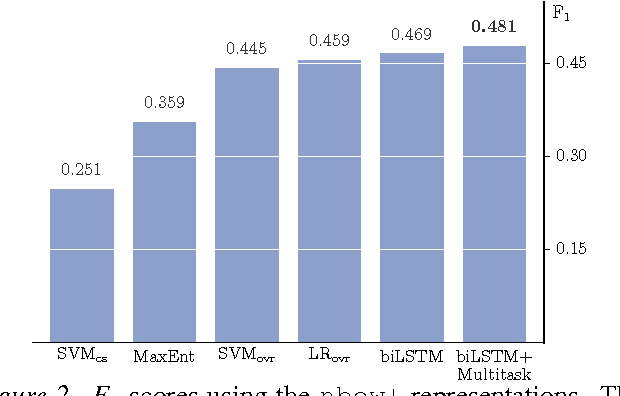
Traditional sentiment analysis approaches tackle problems like ternary (3-category) and fine-grained (5-category) classification by learning the tasks separately. We argue that such classification tasks are correlated and we propose a multitask approach based on a recurrent neural network that benefits by jointly learning them. Our study demonstrates the potential of multitask models on this type of problems and improves the state-of-the-art results in the fine-grained sentiment classification problem.
An empirical study on large scale text classification with skip-gram embeddings
Jun 21, 2016
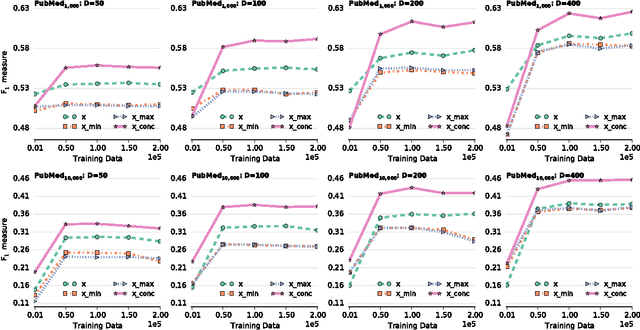
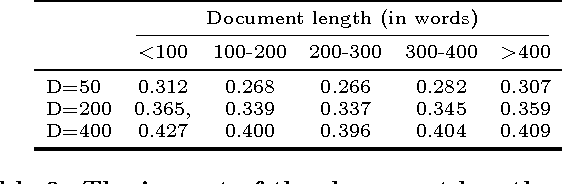
We investigate the integration of word embeddings as classification features in the setting of large scale text classification. Such representations have been used in a plethora of tasks, however their application in classification scenarios with thousands of classes has not been extensively researched, partially due to hardware limitations. In this work, we examine efficient composition functions to obtain document-level from word-level embeddings and we subsequently investigate their combination with the traditional one-hot-encoding representations. By presenting empirical evidence on large, multi-class, multi-label classification problems, we demonstrate the efficiency and the performance benefits of this combination.