 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFacilitating Cognitive Accessibility with LLMs: A Multi-Task Approach to Easy-to-Read Text Generation
Oct 01, 2025
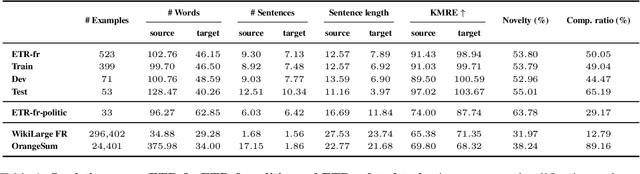
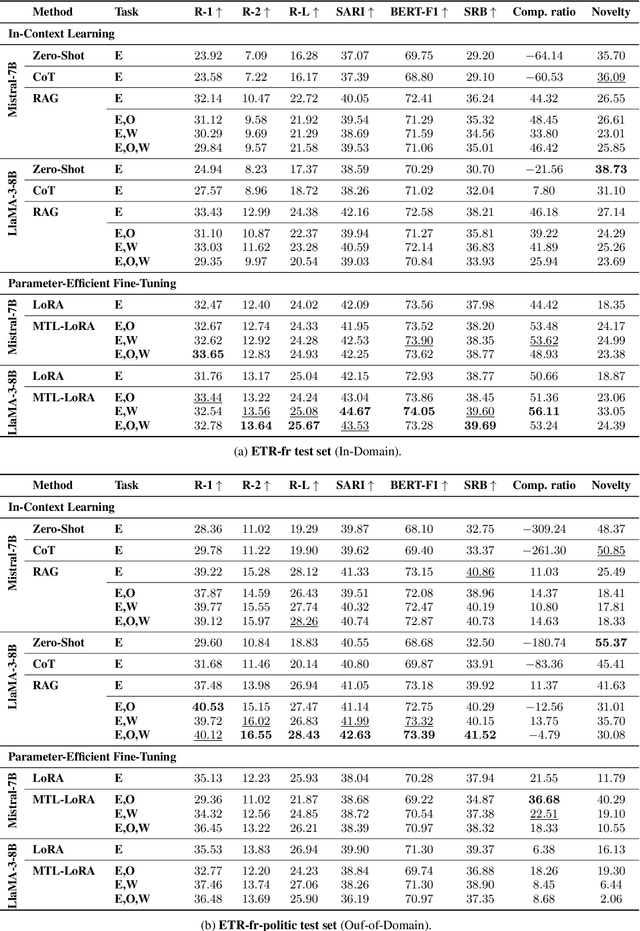
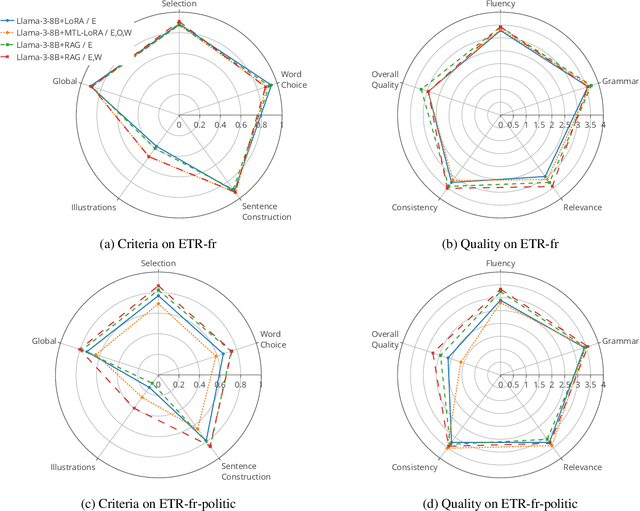
Simplifying complex texts is essential for ensuring equitable access to information, especially for individuals with cognitive impairments. The Easy-to-Read (ETR) initiative offers a framework for making content accessible to the neurodivergent population, but the manual creation of such texts remains time-consuming and resource-intensive. In this work, we investigate the potential of large language models (LLMs) to automate the generation of ETR content. To address the scarcity of aligned corpora and the specificity of ETR constraints, we propose a multi-task learning (MTL) approach that trains models jointly on text summarization, text simplification, and ETR generation. We explore two different strategies: multi-task retrieval-augmented generation (RAG) for in-context learning, and MTL-LoRA for parameter-efficient fine-tuning. Our experiments with Mistral-7B and LLaMA-3-8B, based on ETR-fr, a new high-quality dataset, demonstrate the benefits of multi-task setups over single-task baselines across all configurations. Moreover, results show that the RAG-based strategy enables generalization in out-of-domain settings, while MTL-LoRA outperforms all learning strategies within in-domain configurations.
Inclusive Easy-to-Read Generation for Individuals with Cognitive Impairments
Oct 01, 2025Ensuring accessibility for individuals with cognitive impairments is essential for autonomy, self-determination, and full citizenship. However, manual Easy-to-Read (ETR) text adaptations are slow, costly, and difficult to scale, limiting access to crucial information in healthcare, education, and civic life. AI-driven ETR generation offers a scalable solution but faces key challenges, including dataset scarcity, domain adaptation, and balancing lightweight learning of Large Language Models (LLMs). In this paper, we introduce ETR-fr, the first dataset for ETR text generation fully compliant with European ETR guidelines. We implement parameter-efficient fine-tuning on PLMs and LLMs to establish generative baselines. To ensure high-quality and accessible outputs, we introduce an evaluation framework based on automatic metrics supplemented by human assessments. The latter is conducted using a 36-question evaluation form that is aligned with the guidelines. Overall results show that PLMs perform comparably to LLMs and adapt effectively to out-of-domain texts.
Are LLMs Enough for Hyperpartisan, Fake, Polarized and Harmful Content Detection? Evaluating In-Context Learning vs. Fine-Tuning
Sep 09, 2025
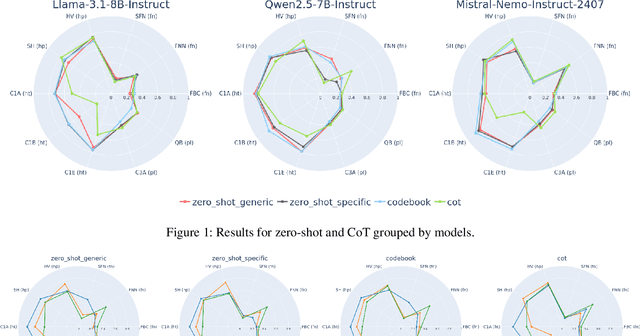
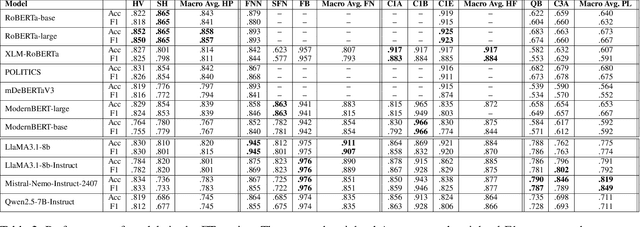
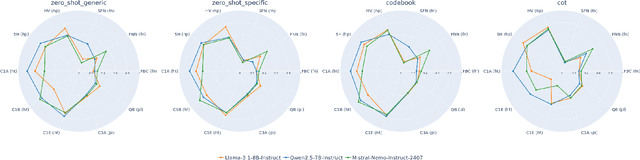
The spread of fake news, polarizing, politically biased, and harmful content on online platforms has been a serious concern. With large language models becoming a promising approach, however, no study has properly benchmarked their performance across different models, usage methods, and languages. This study presents a comprehensive overview of different Large Language Models adaptation paradigms for the detection of hyperpartisan and fake news, harmful tweets, and political bias. Our experiments spanned 10 datasets and 5 different languages (English, Spanish, Portuguese, Arabic and Bulgarian), covering both binary and multiclass classification scenarios. We tested different strategies ranging from parameter efficient Fine-Tuning of language models to a variety of different In-Context Learning strategies and prompts. These included zero-shot prompts, codebooks, few-shot (with both randomly-selected and diversely-selected examples using Determinantal Point Processes), and Chain-of-Thought. We discovered that In-Context Learning often underperforms when compared to Fine-Tuning a model. This main finding highlights the importance of Fine-Tuning even smaller models on task-specific settings even when compared to the largest models evaluated in an In-Context Learning setup - in our case LlaMA3.1-8b-Instruct, Mistral-Nemo-Instruct-2407 and Qwen2.5-7B-Instruct.
Integrating Probabilistic Trees and Causal Networks for Clinical and Epidemiological Data
Jan 27, 2025


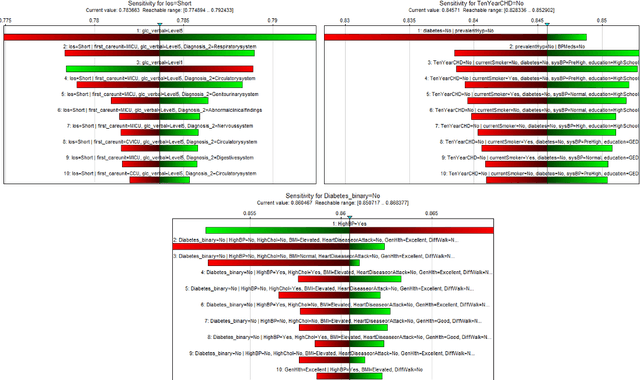
Healthcare decision-making requires not only accurate predictions but also insights into how factors influence patient outcomes. While traditional Machine Learning (ML) models excel at predicting outcomes, such as identifying high risk patients, they are limited in addressing what-if questions about interventions. This study introduces the Probabilistic Causal Fusion (PCF) framework, which integrates Causal Bayesian Networks (CBNs) and Probability Trees (PTrees) to extend beyond predictions. PCF leverages causal relationships from CBNs to structure PTrees, enabling both the quantification of factor impacts and simulation of hypothetical interventions. PCF was validated on three real-world healthcare datasets i.e. MIMIC-IV, Framingham Heart Study, and Diabetes, chosen for their clinically diverse variables. It demonstrated predictive performance comparable to traditional ML models while providing additional causal reasoning capabilities. To enhance interpretability, PCF incorporates sensitivity analysis and SHapley Additive exPlanations (SHAP). Sensitivity analysis quantifies the influence of causal parameters on outcomes such as Length of Stay (LOS), Coronary Heart Disease (CHD), and Diabetes, while SHAP highlights the importance of individual features in predictive modeling. By combining causal reasoning with predictive modeling, PCF bridges the gap between clinical intuition and data-driven insights. Its ability to uncover relationships between modifiable factors and simulate hypothetical scenarios provides clinicians with a clearer understanding of causal pathways. This approach supports more informed, evidence-based decision-making, offering a robust framework for addressing complex questions in diverse healthcare settings.
Evaluating Lexicon Incorporation for Depression Symptom Estimation
Apr 30, 2024
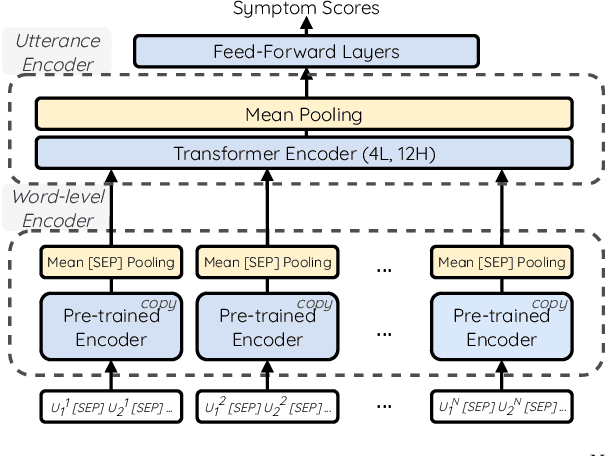
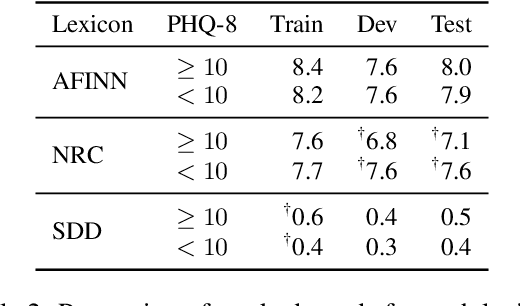
This paper explores the impact of incorporating sentiment, emotion, and domain-specific lexicons into a transformer-based model for depression symptom estimation. Lexicon information is added by marking the words in the input transcripts of patient-therapist conversations as well as in social media posts. Overall results show that the introduction of external knowledge within pre-trained language models can be beneficial for prediction performance, while different lexicons show distinct behaviours depending on the targeted task. Additionally, new state-of-the-art results are obtained for the estimation of depression level over patient-therapist interviews.
Your Model Is Not Predicting Depression Well And That Is Why: A Case Study of PRIMATE Dataset
Mar 01, 2024



This paper addresses the quality of annotations in mental health datasets used for NLP-based depression level estimation from social media texts. While previous research relies on social media-based datasets annotated with binary categories, i.e. depressed or non-depressed, recent datasets such as D2S and PRIMATE aim for nuanced annotations using PHQ-9 symptoms. However, most of these datasets rely on crowd workers without the domain knowledge for annotation. Focusing on the PRIMATE dataset, our study reveals concerns regarding annotation validity, particularly for the lack of interest or pleasure symptom. Through reannotation by a mental health professional, we introduce finer labels and textual spans as evidence, identifying a notable number of false positives. Our refined annotations, to be released under a Data Use Agreement, offer a higher-quality test set for anhedonia detection. This study underscores the necessity of addressing annotation quality issues in mental health datasets, advocating for improved methodologies to enhance NLP model reliability in mental health assessments.
The Verbal and Non Verbal Signals of Depression -- Combining Acoustics, Text and Visuals for Estimating Depression Level
Apr 02, 2019
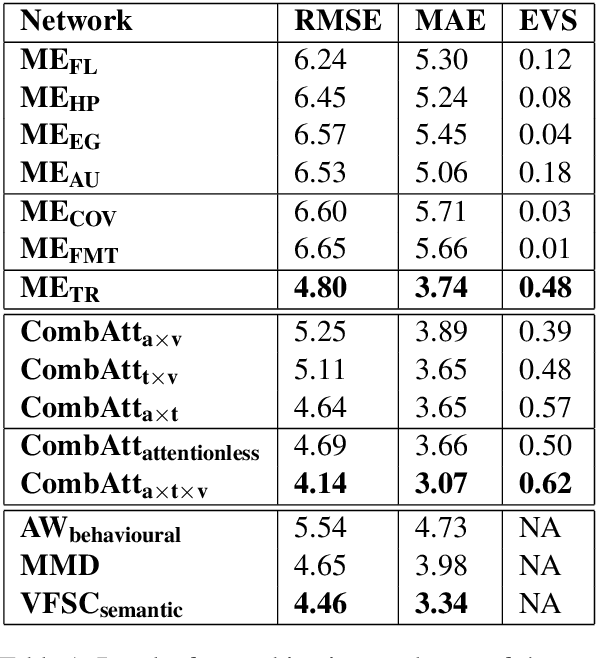
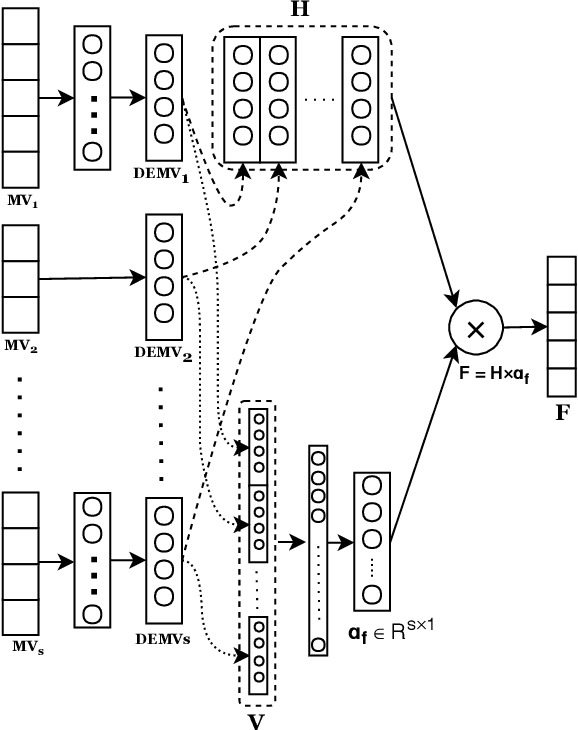
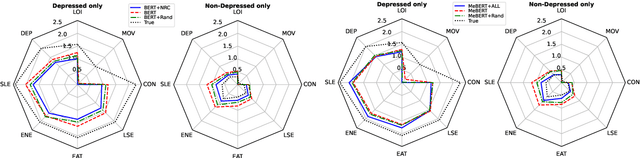
Depression is a serious medical condition that is suffered by a large number of people around the world. It significantly affects the way one feels, causing a persistent lowering of mood. In this paper, we propose a novel attention-based deep neural network which facilitates the fusion of various modalities. We use this network to regress the depression level. Acoustic, text and visual modalities have been used to train our proposed network. Various experiments have been carried out on the benchmark dataset, namely, Distress Analysis Interview Corpus - a Wizard of Oz (DAIC-WOZ). From the results, we empirically justify that the fusion of all three modalities helps in giving the most accurate estimation of depression level. Our proposed approach outperforms the state-of-the-art by 7.17% on root mean squared error (RMSE) and 8.08% on mean absolute error (MAE).
Concurrent Learning of Semantic Relations
Jul 30, 2018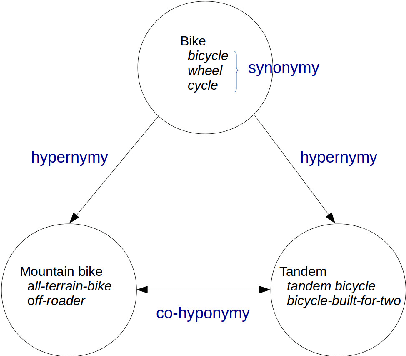

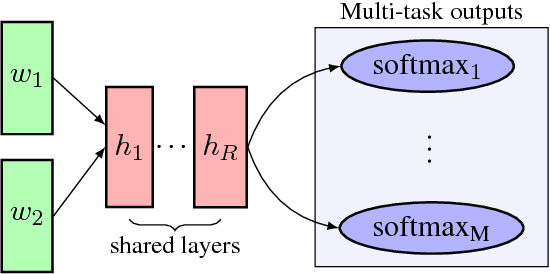
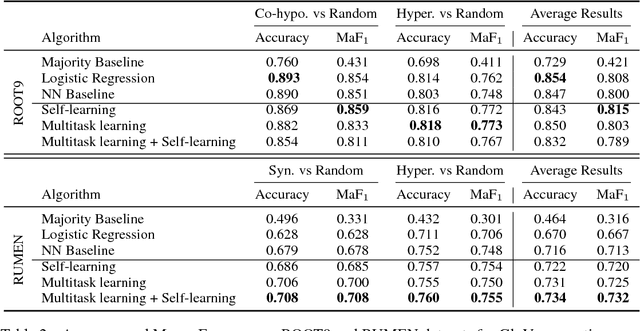
Discovering whether words are semantically related and identifying the specific semantic relation that holds between them is of crucial importance for NLP as it is essential for tasks like query expansion in IR. Within this context, different methodologies have been proposed that either exclusively focus on a single lexical relation (e.g. hypernymy vs. random) or learn specific classifiers capable of identifying multiple semantic relations (e.g. hypernymy vs. synonymy vs. random). In this paper, we propose another way to look at the problem that relies on the multi-task learning paradigm. In particular, we want to study whether the learning process of a given semantic relation (e.g. hypernymy) can be improved by the concurrent learning of another semantic relation (e.g. co-hyponymy). Within this context, we particularly examine the benefits of semi-supervised learning where the training of a prediction function is performed over few labeled data jointly with many unlabeled ones. Preliminary results based on simple learning strategies and state-of-the-art distributional feature representations show that concurrent learning can lead to improvements in a vast majority of tested situations.