 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Profiles of Cognitive Distortions Associated with Mental Health Disorders
May 24, 2026Cognitive distortions, distorted patterns of thinking, have been increasingly studied in computational mental health research. Although they are related to many, if not all, mental health disorders, most existing studies focus primarily on depression. In this work, we explore distortion profiles across multiple mental health conditions. We analyzed a large Reddit-based dataset containing posts from nine self-reported mental health groups as well as a control group using both an n-gram-based method and a fine-tuned transformer model for detecting cognitive distortions. Mental health groups, both when pooled together and when examined individually, showed higher prevalence of cognitive distortions compared to the control group, with the effect sizes ranging from small to moderate. When comparing distortion profiles across conditions, we observed largely similar patterns, although some groups exhibited overall higher levels of distortions than others. These findings suggest that relatively simple lexical approaches can be useful for exploratory analyses of group-level trends in large-scale mental health text data.
EstLLM: Enhancing Estonian Capabilities in Multilingual LLMs via Continued Pretraining and Post-Training
Mar 02, 2026Large language models (LLMs) are predominantly trained on English-centric data, resulting in uneven performance for smaller languages. We study whether continued pretraining (CPT) can substantially improve Estonian capabilities in a pretrained multilingual LLM while preserving its English and general reasoning performance. Using Llama 3.1 8B as the main base model, we perform CPT on a mixture that increases Estonian exposure while approximating the original training distribution through English replay and the inclusion of code, mathematics, and instruction-like data. We subsequently apply supervised fine-tuning, preference optimization, and chat vector merging to introduce robust instruction-following behavior. Evaluation on a comprehensive suite of Estonian benchmarks shows consistent gains in linguistic competence, knowledge, reasoning, translation quality, and instruction-following compared to the original base model and its instruction-tuned variant, while maintaining competitive performance on English benchmarks. These findings indicate that CPT, with an appropriately balanced data mixture, together with post-training alignment, can substantially improve single-language capabilities in pretrained multilingual LLMs.
Creation of the Estonian Subjectivity Dataset: Assessing the Degree of Subjectivity on a Scale
Dec 10, 2025



This article presents the creation of an Estonian-language dataset for document-level subjectivity, analyzes the resulting annotations, and reports an initial experiment of automatic subjectivity analysis using a large language model (LLM). The dataset comprises of 1,000 documents-300 journalistic articles and 700 randomly selected web texts-each rated for subjectivity on a continuous scale from 0 (fully objective) to 100 (fully subjective) by four annotators. As the inter-annotator correlations were moderate, with some texts receiving scores at the opposite ends of the scale, a subset of texts with the most divergent scores was re-annotated, with the inter-annotator correlation improving. In addition to human annotations, the dataset includes scores generated by GPT-5 as an experiment on annotation automation. These scores were similar to human annotators, however several differences emerged, suggesting that while LLM based automatic subjectivity scoring is feasible, it is not an interchangeable alternative to human annotation, and its suitability depends on the intended application.
TartuNLP at SemEval-2025 Task 5: Subject Tagging as Two-Stage Information Retrieval
Apr 30, 2025We present our submission to the Task 5 of SemEval-2025 that aims to aid librarians in assigning subject tags to the library records by producing a list of likely relevant tags for a given document. We frame the task as an information retrieval problem, where the document content is used to retrieve subject tags from a large subject taxonomy. We leverage two types of encoder models to build a two-stage information retrieval system -- a bi-encoder for coarse-grained candidate extraction at the first stage, and a cross-encoder for fine-grained re-ranking at the second stage. This approach proved effective, demonstrating significant improvements in recall compared to single-stage methods and showing competitive results according to qualitative evaluation.
Exploratory Study into Relations between Cognitive Distortions and Emotional Appraisals
Mar 20, 2025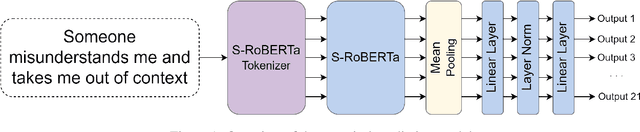
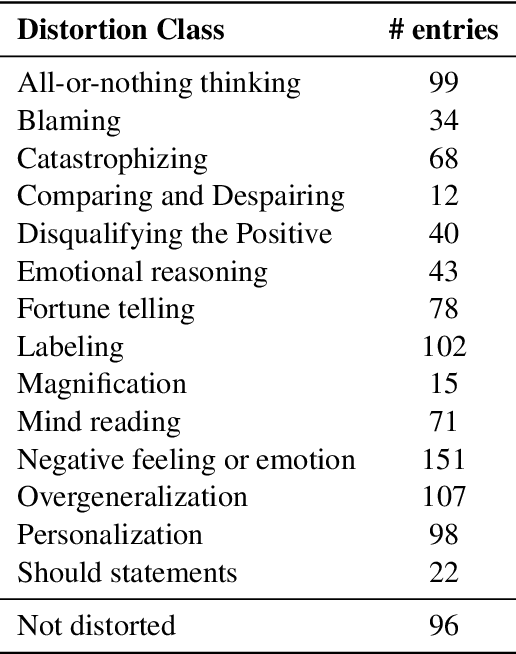
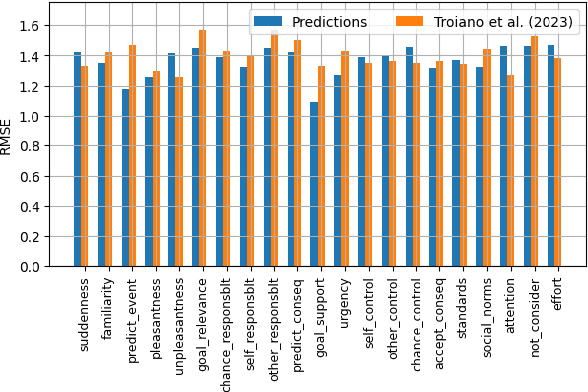
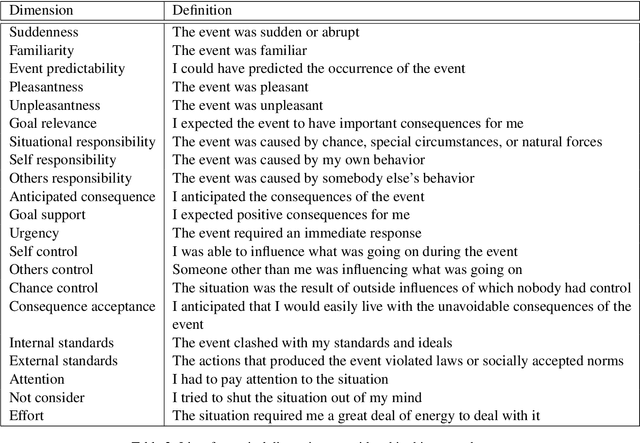
In recent years, there has been growing interest in studying cognitive distortions and emotional appraisals from both computational and psychological perspectives. Despite considerable similarities between emotional reappraisal and cognitive reframing as emotion regulation techniques, these concepts have largely been examined in isolation. This research explores the relationship between cognitive distortions and emotional appraisal dimensions, examining their potential connections and relevance for future interdisciplinary studies. Under this pretext, we conduct an exploratory computational study, aimed at investigating the relationship between cognitive distortion and emotional appraisals. We show that the patterns of statistically significant relationships between cognitive distortions and appraisal dimensions vary across different distortion categories, giving rise to distinct appraisal profiles for individual distortion classes. Additionally, we analyze the impact of cognitive restructuring on appraisal dimensions, exemplifying the emotion regulation aspect of cognitive restructuring.
Prune or Retrain: Optimizing the Vocabulary of Multilingual Models for Estonian
Jan 05, 2025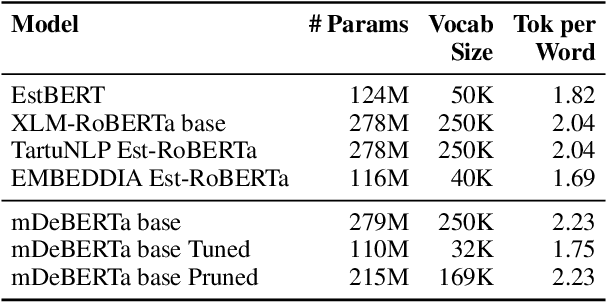
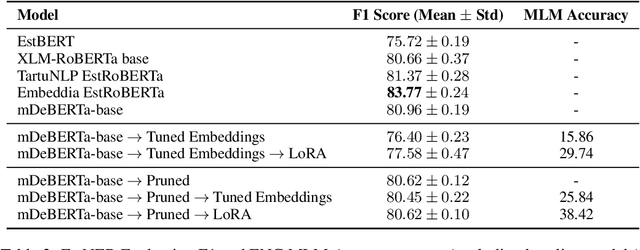
Adapting multilingual language models to specific languages can enhance both their efficiency and performance. In this study, we explore how modifying the vocabulary of a multilingual encoder model to better suit the Estonian language affects its downstream performance on the Named Entity Recognition (NER) task. The motivations for adjusting the vocabulary are twofold: practical benefits affecting the computational cost, such as reducing the input sequence length and the model size, and performance enhancements by tailoring the vocabulary to the particular language. We evaluate the effectiveness of two vocabulary adaptation approaches -- retraining the tokenizer and pruning unused tokens -- and assess their impact on the model's performance, particularly after continual training. While retraining the tokenizer degraded the performance of the NER task, suggesting that longer embedding tuning might be needed, we observed no negative effects on pruning.
GliLem: Leveraging GliNER for Contextualized Lemmatization in Estonian
Dec 29, 2024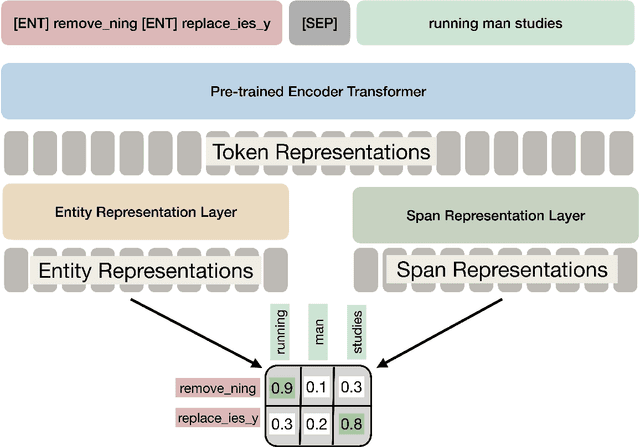

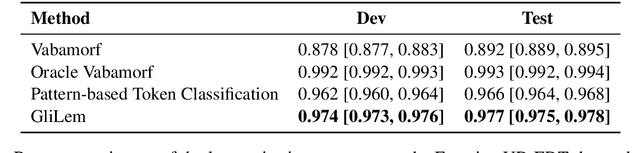
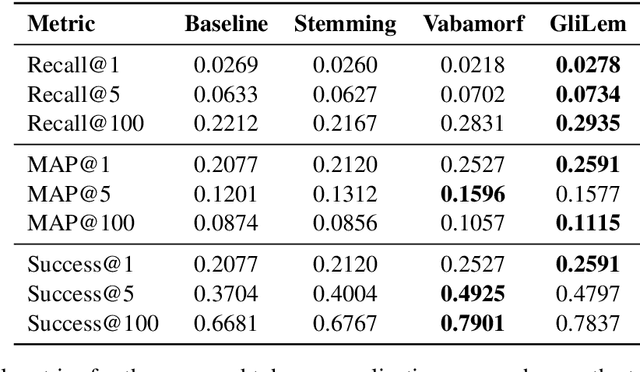
We present GliLem -- a novel hybrid lemmatization system for Estonian that enhances the highly accurate rule-based morphological analyzer Vabamorf with an external disambiguation module based on GliNER -- an open vocabulary NER model that is able to match text spans with text labels in natural language. We leverage the flexibility of a pre-trained GliNER model to improve the lemmatization accuracy of Vabamorf by 10\% compared to its original disambiguation module and achieve an improvement over the token classification-based baseline. To measure the impact of improvements in lemmatization accuracy on the information retrieval downstream task, we first created an information retrieval dataset for Estonian by automatically translating the DBpedia-Entity dataset from English. We benchmark several token normalization approaches, including lemmatization, on the created dataset using the BM25 algorithm. We observe a substantial improvement in IR metrics when using lemmatization over simplistic stemming. The benefits of improving lemma disambiguation accuracy manifest in small but consistent improvement in the IR recall measure, especially in the setting of high k.
TartuNLP @ AXOLOTL-24: Leveraging Classifier Output for New Sense Detection in Lexical Semantics
Jul 04, 2024We present our submission to the AXOLOTL-24 shared task. The shared task comprises two subtasks: identifying new senses that words gain with time (when comparing newer and older time periods) and producing the definitions for the identified new senses. We implemented a conceptually simple and computationally inexpensive solution to both subtasks. We trained adapter-based binary classification models to match glosses with usage examples and leveraged the probability output of the models to identify novel senses. The same models were used to match examples of novel sense usages with Wiktionary definitions. Our submission attained third place on the first subtask and the first place on the second subtask.
Context is Important in Depressive Language: A Study of the Interaction Between the Sentiments and Linguistic Markers in Reddit Discussions
May 28, 2024Research exploring linguistic markers in individuals with depression has demonstrated that language usage can serve as an indicator of mental health. This study investigates the impact of discussion topic as context on linguistic markers and emotional expression in depression, using a Reddit dataset to explore interaction effects. Contrary to common findings, our sentiment analysis revealed a broader range of emotional intensity in depressed individuals, with both higher negative and positive sentiments than controls. This pattern was driven by posts containing no emotion words, revealing the limitations of the lexicon based approaches in capturing the full emotional context. We observed several interesting results demonstrating the importance of contextual analyses. For instance, the use of 1st person singular pronouns and words related to anger and sadness correlated with increased positive sentiments, whereas a higher rate of present-focused words was associated with more negative sentiments. Our findings highlight the importance of discussion contexts while interpreting the language used in depression, revealing that the emotional intensity and meaning of linguistic markers can vary based on the topic of discussion.
TartuNLP at EvaLatin 2024: Emotion Polarity Detection
May 02, 2024This paper presents the TartuNLP team submission to EvaLatin 2024 shared task of the emotion polarity detection for historical Latin texts. Our system relies on two distinct approaches to annotating training data for supervised learning: 1) creating heuristics-based labels by adopting the polarity lexicon provided by the organizers and 2) generating labels with GPT4. We employed parameter efficient fine-tuning using the adapters framework and experimented with both monolingual and cross-lingual knowledge transfer for training language and task adapters. Our submission with the LLM-generated labels achieved the overall first place in the emotion polarity detection task. Our results show that LLM-based annotations show promising results on texts in Latin.