 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEstLLM: Enhancing Estonian Capabilities in Multilingual LLMs via Continued Pretraining and Post-Training
Mar 02, 2026Large language models (LLMs) are predominantly trained on English-centric data, resulting in uneven performance for smaller languages. We study whether continued pretraining (CPT) can substantially improve Estonian capabilities in a pretrained multilingual LLM while preserving its English and general reasoning performance. Using Llama 3.1 8B as the main base model, we perform CPT on a mixture that increases Estonian exposure while approximating the original training distribution through English replay and the inclusion of code, mathematics, and instruction-like data. We subsequently apply supervised fine-tuning, preference optimization, and chat vector merging to introduce robust instruction-following behavior. Evaluation on a comprehensive suite of Estonian benchmarks shows consistent gains in linguistic competence, knowledge, reasoning, translation quality, and instruction-following compared to the original base model and its instruction-tuned variant, while maintaining competitive performance on English benchmarks. These findings indicate that CPT, with an appropriately balanced data mixture, together with post-training alignment, can substantially improve single-language capabilities in pretrained multilingual LLMs.
TartuNLP at SemEval-2025 Task 5: Subject Tagging as Two-Stage Information Retrieval
Apr 30, 2025We present our submission to the Task 5 of SemEval-2025 that aims to aid librarians in assigning subject tags to the library records by producing a list of likely relevant tags for a given document. We frame the task as an information retrieval problem, where the document content is used to retrieve subject tags from a large subject taxonomy. We leverage two types of encoder models to build a two-stage information retrieval system -- a bi-encoder for coarse-grained candidate extraction at the first stage, and a cross-encoder for fine-grained re-ranking at the second stage. This approach proved effective, demonstrating significant improvements in recall compared to single-stage methods and showing competitive results according to qualitative evaluation.
Prune or Retrain: Optimizing the Vocabulary of Multilingual Models for Estonian
Jan 05, 2025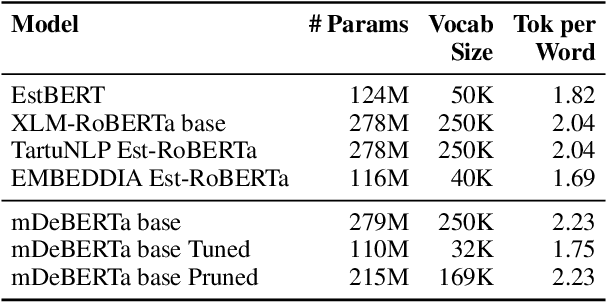
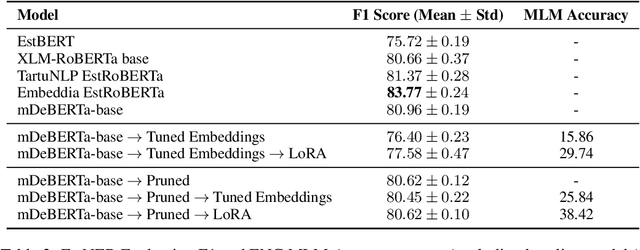
Adapting multilingual language models to specific languages can enhance both their efficiency and performance. In this study, we explore how modifying the vocabulary of a multilingual encoder model to better suit the Estonian language affects its downstream performance on the Named Entity Recognition (NER) task. The motivations for adjusting the vocabulary are twofold: practical benefits affecting the computational cost, such as reducing the input sequence length and the model size, and performance enhancements by tailoring the vocabulary to the particular language. We evaluate the effectiveness of two vocabulary adaptation approaches -- retraining the tokenizer and pruning unused tokens -- and assess their impact on the model's performance, particularly after continual training. While retraining the tokenizer degraded the performance of the NER task, suggesting that longer embedding tuning might be needed, we observed no negative effects on pruning.
GliLem: Leveraging GliNER for Contextualized Lemmatization in Estonian
Dec 29, 2024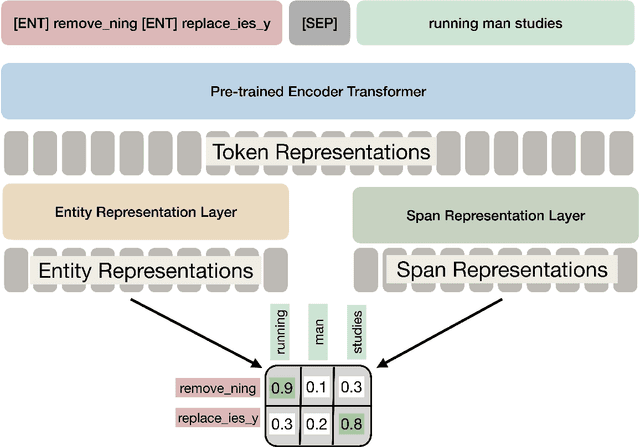

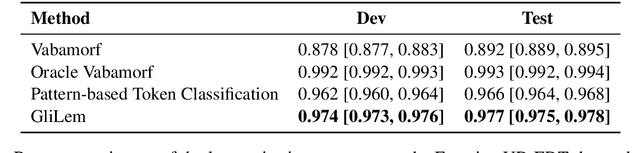
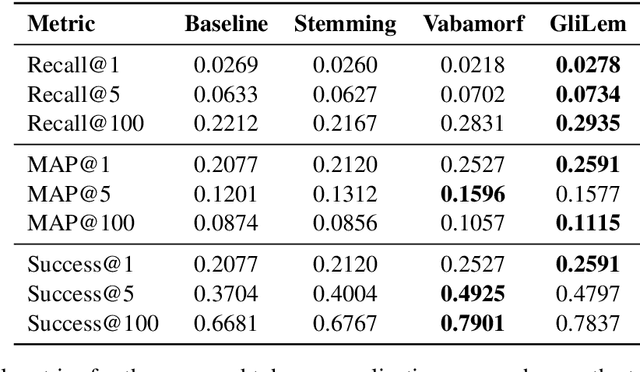
We present GliLem -- a novel hybrid lemmatization system for Estonian that enhances the highly accurate rule-based morphological analyzer Vabamorf with an external disambiguation module based on GliNER -- an open vocabulary NER model that is able to match text spans with text labels in natural language. We leverage the flexibility of a pre-trained GliNER model to improve the lemmatization accuracy of Vabamorf by 10\% compared to its original disambiguation module and achieve an improvement over the token classification-based baseline. To measure the impact of improvements in lemmatization accuracy on the information retrieval downstream task, we first created an information retrieval dataset for Estonian by automatically translating the DBpedia-Entity dataset from English. We benchmark several token normalization approaches, including lemmatization, on the created dataset using the BM25 algorithm. We observe a substantial improvement in IR metrics when using lemmatization over simplistic stemming. The benefits of improving lemma disambiguation accuracy manifest in small but consistent improvement in the IR recall measure, especially in the setting of high k.
TartuNLP @ AXOLOTL-24: Leveraging Classifier Output for New Sense Detection in Lexical Semantics
Jul 04, 2024We present our submission to the AXOLOTL-24 shared task. The shared task comprises two subtasks: identifying new senses that words gain with time (when comparing newer and older time periods) and producing the definitions for the identified new senses. We implemented a conceptually simple and computationally inexpensive solution to both subtasks. We trained adapter-based binary classification models to match glosses with usage examples and leveraged the probability output of the models to identify novel senses. The same models were used to match examples of novel sense usages with Wiktionary definitions. Our submission attained third place on the first subtask and the first place on the second subtask.
TartuNLP at EvaLatin 2024: Emotion Polarity Detection
May 02, 2024This paper presents the TartuNLP team submission to EvaLatin 2024 shared task of the emotion polarity detection for historical Latin texts. Our system relies on two distinct approaches to annotating training data for supervised learning: 1) creating heuristics-based labels by adopting the polarity lexicon provided by the organizers and 2) generating labels with GPT4. We employed parameter efficient fine-tuning using the adapters framework and experimented with both monolingual and cross-lingual knowledge transfer for training language and task adapters. Our submission with the LLM-generated labels achieved the overall first place in the emotion polarity detection task. Our results show that LLM-based annotations show promising results on texts in Latin.
Sõnajaht: Definition Embeddings and Semantic Search for Reverse Dictionary Creation
Apr 30, 2024

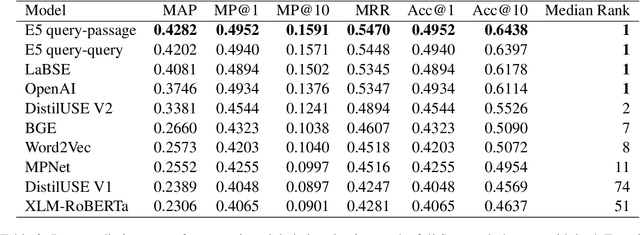
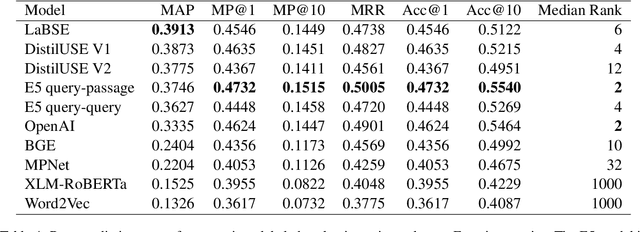
We present an information retrieval based reverse dictionary system using modern pre-trained language models and approximate nearest neighbors search algorithms. The proposed approach is applied to an existing Estonian language lexicon resource, S\~onaveeb (word web), with the purpose of enhancing and enriching it by introducing cross-lingual reverse dictionary functionality powered by semantic search. The performance of the system is evaluated using both an existing labeled English dataset of words and definitions that is extended to contain also Estonian and Russian translations, and a novel unlabeled evaluation approach that extracts the evaluation data from the lexicon resource itself using synonymy relations. Evaluation results indicate that the information retrieval based semantic search approach without any model training is feasible, producing median rank of 1 in the monolingual setting and median rank of 2 in the cross-lingual setting using the unlabeled evaluation approach, with models trained for cross-lingual retrieval and including Estonian in their training data showing superior performance in our particular task.
Comparison of Current Approaches to Lemmatization: A Case Study in Estonian
Apr 23, 2024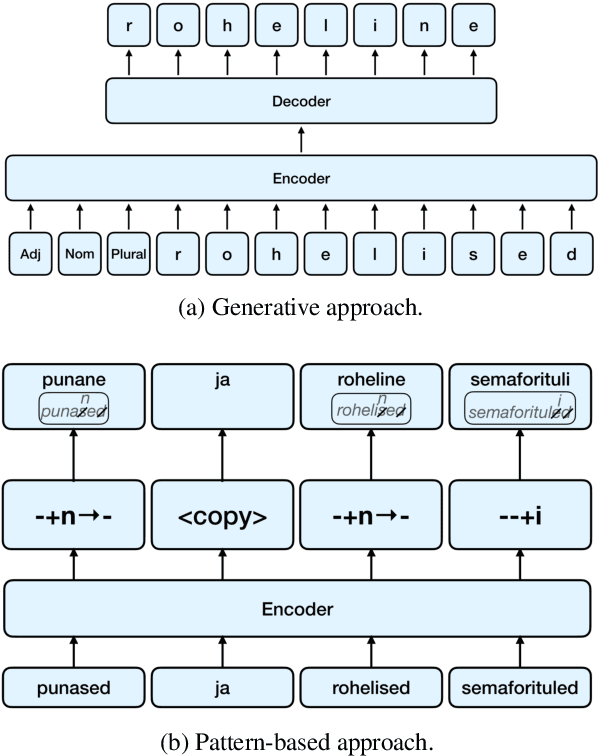
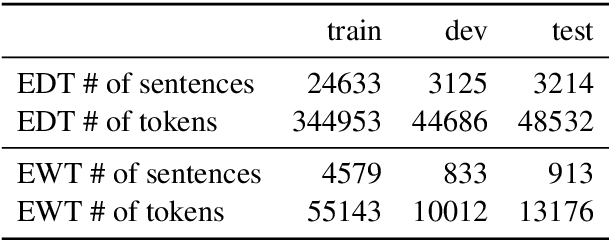
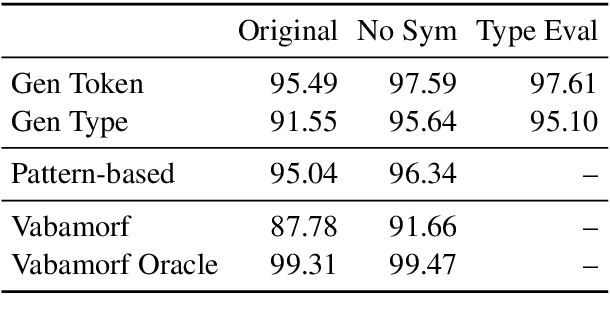
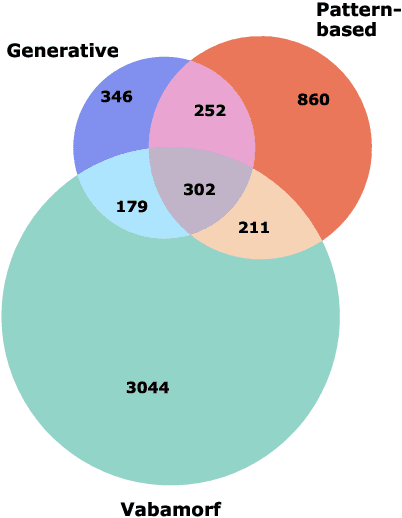
This study evaluates three different lemmatization approaches to Estonian -- Generative character-level models, Pattern-based word-level classification models, and rule-based morphological analysis. According to our experiments, a significantly smaller Generative model consistently outperforms the Pattern-based classification model based on EstBERT. Additionally, we observe a relatively small overlap in errors made by all three models, indicating that an ensemble of different approaches could lead to improvements.
* 6 pages, 2 figures
TartuNLP @ SIGTYP 2024 Shared Task: Adapting XLM-RoBERTa for Ancient and Historical Languages
Apr 19, 2024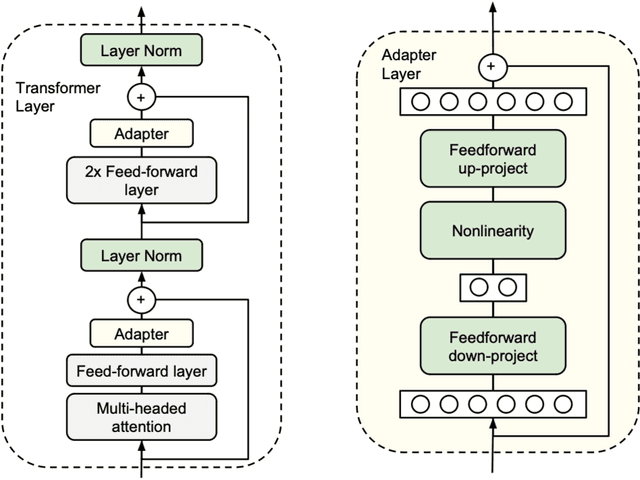
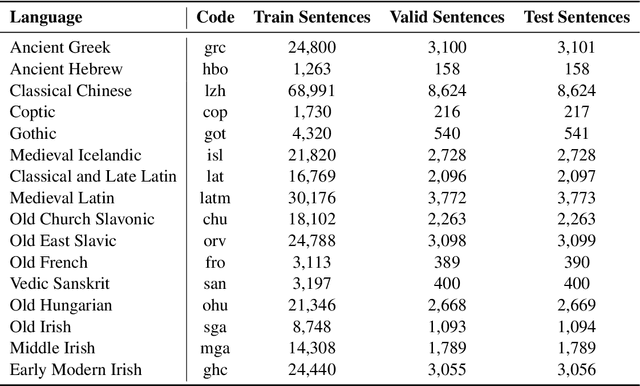
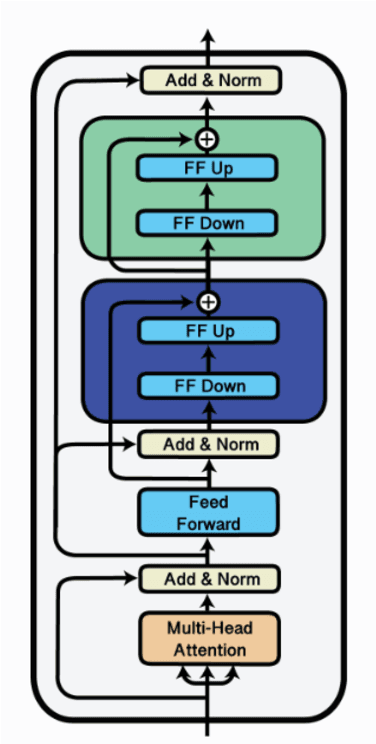
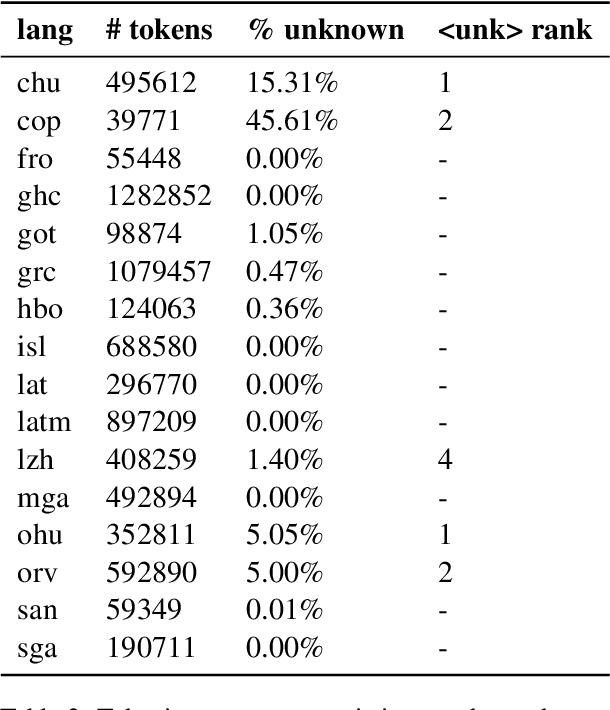
We present our submission to the unconstrained subtask of the SIGTYP 2024 Shared Task on Word Embedding Evaluation for Ancient and Historical Languages for morphological annotation, POS-tagging, lemmatization, character- and word-level gap-filling. We developed a simple, uniform, and computationally lightweight approach based on the adapters framework using parameter-efficient fine-tuning. We applied the same adapter-based approach uniformly to all tasks and 16 languages by fine-tuning stacked language- and task-specific adapters. Our submission obtained an overall second place out of three submissions, with the first place in word-level gap-filling. Our results show the feasibility of adapting language models pre-trained on modern languages to historical and ancient languages via adapter training.
* 11 pages, 3 figures