 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSõnajaht: Definition Embeddings and Semantic Search for Reverse Dictionary Creation
Paper and Code


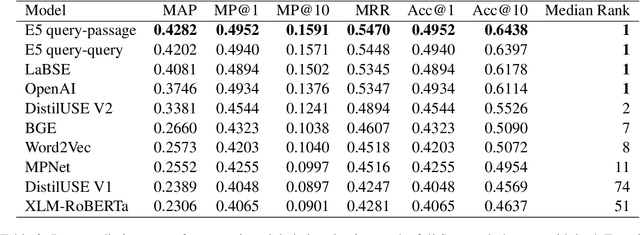
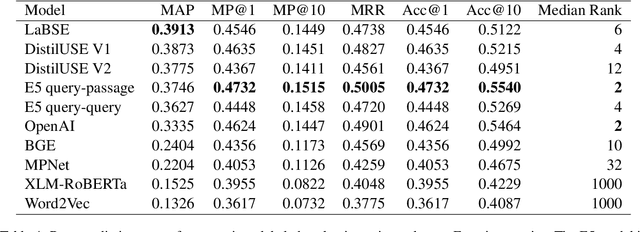
We present an information retrieval based reverse dictionary system using modern pre-trained language models and approximate nearest neighbors search algorithms. The proposed approach is applied to an existing Estonian language lexicon resource, S\~onaveeb (word web), with the purpose of enhancing and enriching it by introducing cross-lingual reverse dictionary functionality powered by semantic search. The performance of the system is evaluated using both an existing labeled English dataset of words and definitions that is extended to contain also Estonian and Russian translations, and a novel unlabeled evaluation approach that extracts the evaluation data from the lexicon resource itself using synonymy relations. Evaluation results indicate that the information retrieval based semantic search approach without any model training is feasible, producing median rank of 1 in the monolingual setting and median rank of 2 in the cross-lingual setting using the unlabeled evaluation approach, with models trained for cross-lingual retrieval and including Estonian in their training data showing superior performance in our particular task.