 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-lingual Document Retrieval using Regularized Wasserstein Distance
Paper and Code
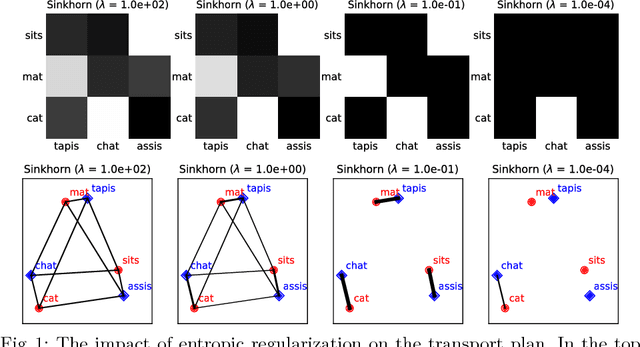
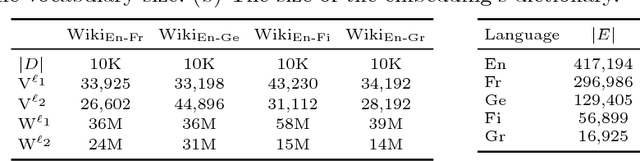
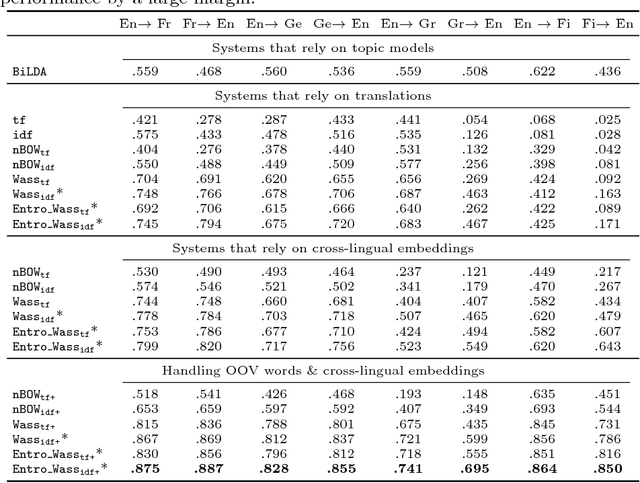
Many information retrieval algorithms rely on the notion of a good distance that allows to efficiently compare objects of different nature. Recently, a new promising metric called Word Mover's Distance was proposed to measure the divergence between text passages. In this paper, we demonstrate that this metric can be extended to incorporate term-weighting schemes and provide more accurate and computationally efficient matching between documents using entropic regularization. We evaluate the benefits of both extensions in the task of cross-lingual document retrieval (CLDR). Our experimental results on eight CLDR problems suggest that the proposed methods achieve remarkable improvements in terms of Mean Reciprocal Rank compared to several baselines.