 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWasserstein distances for evaluating cross-lingual embeddings
Paper and Code

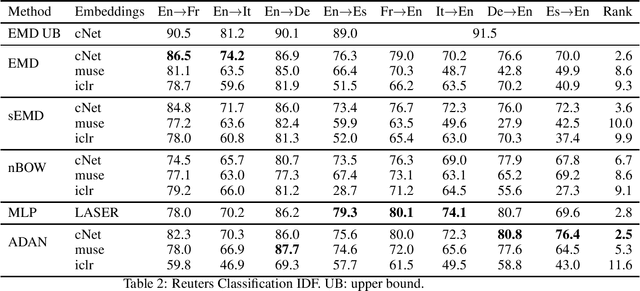
Word embeddings are high dimensional vector representations of words that capture their semantic similarity in the vector space. There exist several algorithms for learning such embeddings both for a single language as well as for several languages jointly. In this work we propose to evaluate collections of embeddings by adapting downstream natural language tasks to the optimal transport framework. We show how the family of Wasserstein distances can be used to solve cross-lingual document retrieval and the cross-lingual document classification problems. We argue on the advantages of this approach compared to more traditional evaluation methods of embeddings like bilingual lexical induction. Our experimental results suggest that using Wasserstein distances on these problems out-performs several strong baselines and performs on par with state-of-the-art models.