 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSEF-CLGC at SemEval-2026 Task 11: Logical Notation Impact on Language Model Performance
Jun 08, 2026This paper revisits our pipeline called Syllogistic Evaluation Framework-Common Logic Grammar Construction (SEF-CLGC). We combine formal logical notations with Small Language Models (SLMs) to evaluate reasoning performance on the SemEval-2026 Task 11 Subtask 1: Disentangling Content and Formal Reasoning in Large Language Models. Our experiments show that by relying solely on SLMs, trained on a combination of natural and symbolic languages, our best model achieves a content score of 27.80% on the task while significantly lowering the content bias in reasoning.
Link Prediction or Perdition: the Seeds of Instability in Knowledge Graph Embeddings
Jun 02, 2026Embedding models (KGEMs) constitute the main link prediction approach to complete knowledge graphs. Standard evaluation protocols emphasize rank-based metrics such as MRR or Hits@$K$, but usually overlook the influence of random seeds on result stability. Moreover, these metrics conceal potential instabilities in individual predictions and in the organization of embedding spaces. In this work, we conduct a systematic stability analysis of multiple KGEMs across several datasets. We find that high-performance models actually produce divergent predictions at the triple level and highly variable embedding spaces. By isolating stochastic factors (i.e., initialization, triple ordering, negative sampling, dropout, hardware), we show that each independently induces instability of comparable magnitude. Furthermore, for a given model, hyperparameter configurations with better MRR are not guaranteed to be more stable. Moreover, voting, albeit a known remediation mechanism, only provides a limited enhancement of stability. These findings highlight critical limitations of current benchmarking protocols, and raise concerns about the reliability of KGEMs for knowledge graph completion.
Which Are the Low-Resource Languages of the Semantic Web?
May 07, 2026Emerging digital technologies are exacerbating the existing divide in Open Access Data (OAD) between high-and low-resource languages, excluding many communities from the global digital transformation. Multilingual Linked Open Data Knowledge Graphs (LOD KGs) could contribute to mitigating this divide through cross-lingual transfer; however, no clear quantitative definition of low-resource languages has yet been established in the context of LOD KGs. In this poster, we present a methodology to analyze the distribution of languages across LOD KGs and propose a preliminary multi-level categorization based on DBpedia, BabelNet, and Wikidata. This categorization is leveraged to bring a formal definition of low-, high-, and medium-resource languages that could be later leveraged to select cross-lingual transfer candidates.
Mimosa Framework: Toward Evolving Multi-Agent Systems for Scientific Research
Mar 30, 2026Current Autonomous Scientific Research (ASR) systems, despite leveraging large language models (LLMs) and agentic architectures, remain constrained by fixed workflows and toolsets that prevent adaptation to evolving tasks and environments. We introduce Mimosa, an evolving multi-agent framework that automatically synthesizes task-specific multi-agent workflows and iteratively refines them through experimental feedback. Mimosa leverages the Model Context Protocol (MCP) for dynamic tool discovery, generates workflow topologies via a meta-orchestrator, executes subtasks through code-generating agents that invoke available tools and scientific software libraries, and scores executions with an LLM-based judge whose feedback drives workflow refinement. On ScienceAgentBench, Mimosa achieves a success rate of 43.1% with DeepSeek-V3.2, surpassing both single-agent baselines and static multi-agent configurations. Our results further reveal that models respond heterogeneously to multi-agent decomposition and iterative learning, indicating that the benefits of workflow evolution depend on the capabilities of the underlying execution model. Beyond these benchmarks, Mimosa modular architecture and tool-agnostic design make it readily extensible, and its fully logged execution traces and archived workflows support auditability by preserving every analytical step for inspection and potential replication. Combined with domain-expert guidance, the framework has the potential to automate a broad range of computationally accessible scientific tasks across disciplines. Released as a fully open-source platform, Mimosa aims to provide an open foundation for community-driven ASR.
Overcoming the Generalization Limits of SLM Finetuning for Shape-Based Extraction of Datatype and Object Properties
Nov 05, 2025Small language models (SLMs) have shown promises for relation extraction (RE) when extracting RDF triples guided by SHACL shapes focused on common datatype properties. This paper investigates how SLMs handle both datatype and object properties for a complete RDF graph extraction. We show that the key bottleneck is related to long-tail distribution of rare properties. To solve this issue, we evaluate several strategies: stratified sampling, weighted loss, dataset scaling, and template-based synthetic data augmentation. We show that the best strategy to perform equally well over unbalanced target properties is to build a training set where the number of occurrences of each property exceeds a given threshold. To enable reproducibility, we publicly released our datasets, experimental results and code. Our findings offer practical guidance for training shape-aware SLMs and highlight promising directions for future work in semantic RE.
MetaboT: AI-based agent for natural language-based interaction with metabolomics knowledge graphs
Oct 02, 2025Mass spectrometry metabolomics generates vast amounts of data requiring advanced methods for interpretation. Knowledge graphs address these challenges by structuring mass spectrometry data, metabolite information, and their relationships into a connected network (Gaudry et al. 2024). However, effective use of a knowledge graph demands an in-depth understanding of its ontology and its query language syntax. To overcome this, we designed MetaboT, an AI system utilizing large language models (LLMs) to translate user questions into SPARQL semantic query language for operating on knowledge graphs (Steve Harris 2013). We demonstrate its effectiveness using the Experimental Natural Products Knowledge Graph (ENPKG), a large-scale public knowledge graph for plant natural products (Gaudry et al. 2024).MetaboT employs specialized AI agents for handling user queries and interacting with the knowledge graph by breaking down complex tasks into discrete components, each managed by a specialised agent (Fig. 1a). The multi-agent system is constructed using the LangChain and LangGraph libraries, which facilitate the integration of LLMs with external tools and information sources (LangChain, n.d.). The query generation process follows a structured workflow. First, the Entry Agent determines if the question is new or a follow-up to previous interactions. New questions are forwarded to the Validator Agent, which verifies if the question is related to the knowledge graph. Then, the valid question is sent to the Supervisor Agent, which identifies if the question requires chemical conversions or standardized identifiers. In this case it delegates the question to the Knowledge Graph Agent, which can use tools to extract necessary details, such as URIs or taxonomies of chemical names, from the user query. Finally, an agent responsible for crafting the SPARQL queries equipped with the ontology of the knowledge graph uses the provided identifiers to generate the query. Then, the system executes the generated query against the metabolomics knowledge graph and returns structured results to the user (Fig. 1b). To assess the performance of MetaboT we have curated 50 metabolomics-related questions and their expected answers. In addition to submitting these questions to MetaboT, we evaluated a baseline by submitting them to a standard LLM (GPT-4o) with a prompt that incorporated the knowledge graph ontology but did not provide specific entity IDs. This baseline achieved only 8.16% accuracy, compared to MetaboT's 83.67%, underscoring the necessity of our multi-agent system for accurately retrieving entities and generating correct SPARQL queries. MetaboT demonstrates promising performance as a conversational question-answering assistant, enabling researchers to retrieve structured metabolomics data through natural language queries. By automating the generation and execution of SPARQL queries, it removes technical barriers that have traditionally hindered access to knowledge graphs. Importantly, MetaboT leverages the capabilities of LLMs while maintaining experimentally grounded query generation, ensuring that outputs remain aligned with domain-specific standards and data structures. This approach facilitates data-driven discoveries by bridging the gap between complex semantic technologies and user-friendly interaction. MetaboT is accessible at [https://metabot.holobiomicslab.eu/], and its source code is available at [https://github.com/HolobiomicsLab/MetaboT].
Eat your own KR: a KR-based approach to index Semantic Web Endpoints and Knowledge Graphs
Aug 12, 2025Over the last decade, knowledge graphs have multiplied, grown, and evolved on the World Wide Web, and the advent of new standards, vocabularies, and application domains has accelerated this trend. IndeGx is a framework leveraging an extensible base of rules to index the content of KGs and the capacities of their SPARQL endpoints. In this article, we show how knowledge representation (KR) and reasoning methods and techniques can be used in a reflexive manner to index and characterize existing knowledge graphs (KG) with respect to their usage of KR methods and techniques. We extended IndeGx with a fully ontology-oriented modeling and processing approach to do so. Using SPARQL rules and an OWL RL ontology of the indexing domain, IndeGx can now build and reason over an index of the contents and characteristics of an open collection of public knowledge graphs. Our extension of the framework relies on a declarative representation of procedural knowledge and collaborative environments (e.g., GitHub) to provide an agile, customizable, and expressive KR approach for building and maintaining such an index of knowledge graphs in the wild. In doing so, we help anyone answer the question of what knowledge is out there in the world wild Semantic Web in general, and we also help our community monitor which KR research results are used in practice. In particular, this article provides a snapshot of the state of the Semantic Web regarding supported standard languages, ontology usage, and diverse quality evaluations by applying this method to a collection of over 300 open knowledge graph endpoints.
Q${}^2$Forge: Minting Competency Questions and SPARQL Queries for Question-Answering Over Knowledge Graphs
May 19, 2025The SPARQL query language is the standard method to access knowledge graphs (KGs). However, formulating SPARQL queries is a significant challenge for non-expert users, and remains time-consuming for the experienced ones. Best practices recommend to document KGs with competency questions and example queries to contextualise the knowledge they contain and illustrate their potential applications. In practice, however, this is either not the case or the examples are provided in limited numbers. Large Language Models (LLMs) are being used in conversational agents and are proving to be an attractive solution with a wide range of applications, from simple question-answering about common knowledge to generating code in a targeted programming language. However, training and testing these models to produce high quality SPARQL queries from natural language questions requires substantial datasets of question-query pairs. In this paper, we present Q${}^2$Forge that addresses the challenge of generating new competency questions for a KG and corresponding SPARQL queries. It iteratively validates those queries with human feedback and LLM as a judge. Q${}^2$Forge is open source, generic, extensible and modular, meaning that the different modules of the application (CQ generation, query generation and query refinement) can be used separately, as an integrated pipeline, or replaced by alternative services. The result is a complete pipeline from competency question formulation to query evaluation, supporting the creation of reference query sets for any target KG.
Love Me, Love Me, Say that You Love Me: Enriching the WASABI Song Corpus with Lyrics Annotations
Dec 05, 2019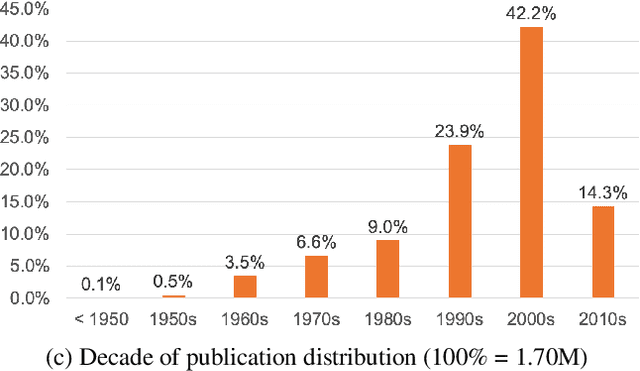
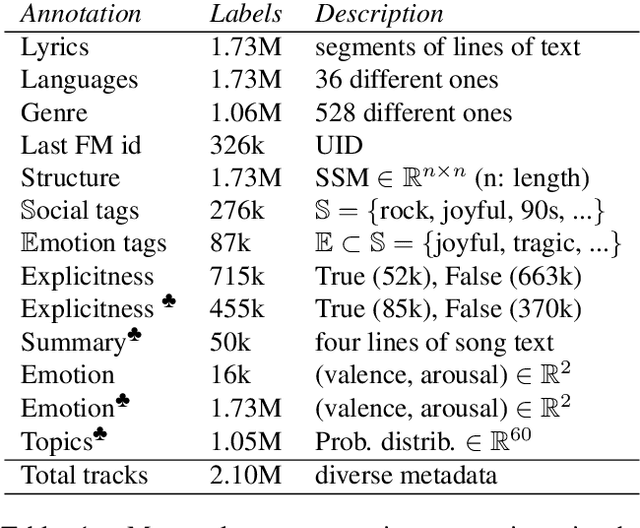

We present the WASABI Song Corpus, a large corpus of songs enriched with metadata extracted from music databases on the Web, and resulting from the processing of song lyrics and from audio analysis. More specifically, given that lyrics encode an important part of the semantics of a song, we focus here on the description of the methods we proposed to extract relevant information from the lyrics, such as their structure segmentation, their topics, the explicitness of the lyrics content, the salient passages of a song and the emotions conveyed. The creation of the resource is still ongoing: so far, the corpus contains 1.73M songs with lyrics (1.41M unique lyrics) annotated at different levels with the output of the above mentioned methods. Such corpus labels and the provided methods can be exploited by music search engines and music professionals (e.g. journalists, radio presenters) to better handle large collections of lyrics, allowing an intelligent browsing, categorization and segmentation recommendation of songs.
Graph Data on the Web: extend the pivot, don't reinvent the wheel
Mar 11, 2019This article is a collective position paper from the Wimmics research team, expressing our vision of how Web graph data technologies should evolve in the future in order to ensure a high-level of interoperability between the many types of applications that produce and consume graph data. Wimmics stands for Web-Instrumented Man-Machine Interactions, Communities, and Semantics. We are a joint research team between INRIA Sophia Antipolis-M{\'e}diterran{\'e}e and I3S (CNRS and Universit{\'e} C{\^o}te d'Azur). Our challenge is to bridge formal semantics and social semantics on the web. Our research areas are graph-oriented knowledge representation, reasoning and operationalization to model and support actors, actions and interactions in web-based epistemic communities. The application of our research is supporting and fostering interactions in online communities and management of their resources. In this position paper, we emphasize the need to extend the semantic Web standard stack to address and fulfill new graph data needs, as well as the importance of remaining compatible with existing recommendations, in particular the RDF stack, to avoid the painful duplication of models, languages, frameworks, etc. The following sections group motivations for different directions of work and collect reasons for the creation of a working group on RDF 2.0 and other recommendations of the RDF family.