 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOntologies-based Architecture for Sociocultural Knowledge Co-Construction Systems
Apr 11, 2019


Considering the evolution of the semantic wiki engine based platforms, two main approaches could be distinguished: Ontologies for Wikis (OfW) and Wikis for Ontologies (WfO). OfW vision requires existing ontologies to be imported. Most of them use the RDF-based (Resource Description Framework) systems in conjunction with the standard SQL (Structured Query Language) database to manage and query semantic data. But, relational database is not an ideal type of storage for semantic data. A more natural data model for SMW (Semantic MediaWiki) is RDF, a data format that organizes information in graphs rather than in fixed database tables. This paper presents an ontology based architecture, which aims to implement this idea. The architecture mainly includes three layered functional architectures: Web User Interface Layer, Semantic Layer and Persistence Layer.
Graph Data on the Web: extend the pivot, don't reinvent the wheel
Mar 11, 2019This article is a collective position paper from the Wimmics research team, expressing our vision of how Web graph data technologies should evolve in the future in order to ensure a high-level of interoperability between the many types of applications that produce and consume graph data. Wimmics stands for Web-Instrumented Man-Machine Interactions, Communities, and Semantics. We are a joint research team between INRIA Sophia Antipolis-M{\'e}diterran{\'e}e and I3S (CNRS and Universit{\'e} C{\^o}te d'Azur). Our challenge is to bridge formal semantics and social semantics on the web. Our research areas are graph-oriented knowledge representation, reasoning and operationalization to model and support actors, actions and interactions in web-based epistemic communities. The application of our research is supporting and fostering interactions in online communities and management of their resources. In this position paper, we emphasize the need to extend the semantic Web standard stack to address and fulfill new graph data needs, as well as the importance of remaining compatible with existing recommendations, in particular the RDF stack, to avoid the painful duplication of models, languages, frameworks, etc. The following sections group motivations for different directions of work and collect reasons for the creation of a working group on RDF 2.0 and other recommendations of the RDF family.
HuTO: an Human Time Ontology for Semantic Web Applications
Jun 19, 2015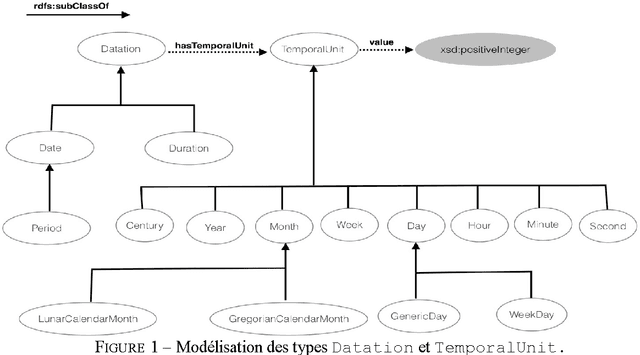
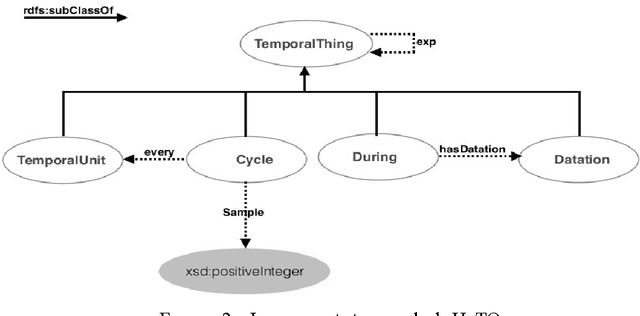
The temporal phenomena have many facets that are studied by different communities. In Semantic Web, large heterogeneous data are handled and produced. These data often have informal, semi-formal or formal temporal information which must be interpreted by software agents. In this paper we present Human Time Ontology (HuTO) an RDFS ontology to annotate and represent temporal data. A major contribution of HuTO is the modeling of non-convex intervals giving the ability to write queries for this kind of interval. HuTO also incorporates normalization and reasoning rules to explicit certain information. HuTO also proposes an approach which associates a temporal dimension to the knowledge base content. This facilitates information retrieval by considering or not the temporal aspect.
Towards a Semantic-based Approach for Modeling Regulatory Documents in Building Industry
Feb 20, 2013
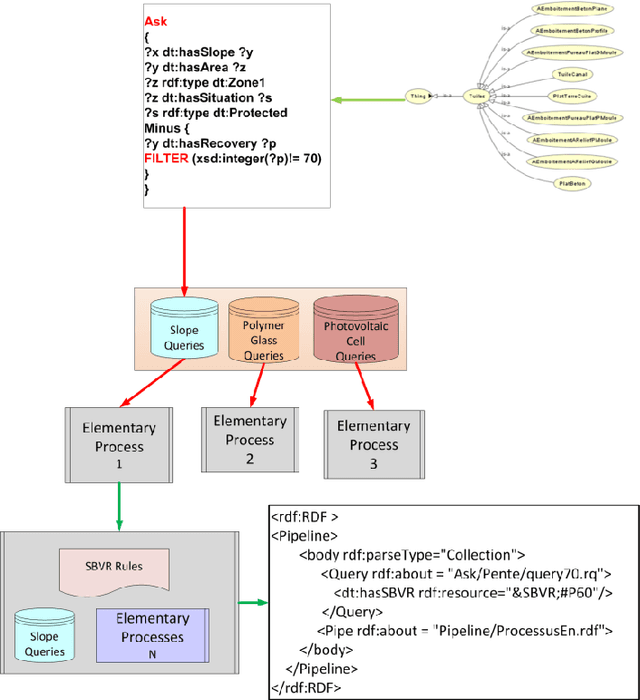
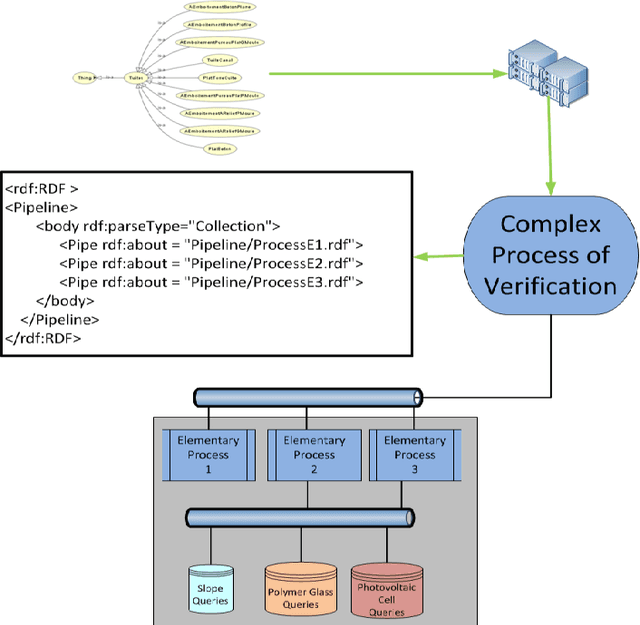

Regulations in the Building Industry are becoming increasingly complex and involve more than one technical area. They cover products, components and project implementation. They also play an important role to ensure the quality of a building, and to minimize its environmental impact. In this paper, we are particularly interested in the modeling of the regulatory constraints derived from the Technical Guides issued by CSTB and used to validate Technical Assessments. We first describe our approach for modeling regulatory constraints in the SBVR language, and formalizing them in the SPARQL language. Second, we describe how we model the processes of compliance checking described in the CSTB Technical Guides. Third, we show how we implement these processes to assist industrials in drafting Technical Documents in order to acquire a Technical Assessment; a compliance report is automatically generated to explain the compliance or noncompliance of this Technical Documents.
Semantic Social Network Analysis
Apr 23, 2009
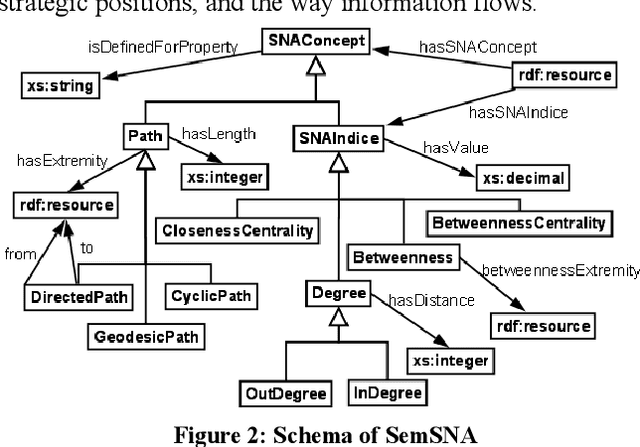
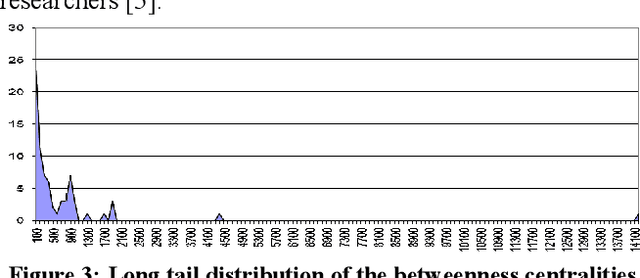
Social Network Analysis (SNA) tries to understand and exploit the key features of social networks in order to manage their life cycle and predict their evolution. Increasingly popular web 2.0 sites are forming huge social network. Classical methods from social network analysis (SNA) have been applied to such online networks. In this paper, we propose leveraging semantic web technologies to merge and exploit the best features of each domain. We present how to facilitate and enhance the analysis of online social networks, exploiting the power of semantic social network analysis.